ź╦źÕĪ╝źĒź┴ź├źū▄ć└ŌĪĪĪ┴żżżĶżżżĶ╚ŠŲ│öüż╬Įą╚ų(2-1)
ŗī2ŠŽĪ¦źŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬ź╦źÕĪ╝źĒź┴ź├źūżžż╬╝┬äóĪ┴żĮż╬┤¬ĮĻżŽ!!
ż│ż╬ŗī2ŠŽżŽĪó┐═╣®ē¶ē”Ī╩AIĪ╦ż╬┬Õ╔Į┼¬ż╩▒■├ōżŪżóżļ▓ĶćĄŪ¦╝▒ż╦żĶż»╗╚ż’żņżŲżżżļCNN Ī╩Convolutional Neural Network:: øQż▀╣■ż▀ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»Ī╦ż“Šę▓żĘĪóLSI▓Įż╣żļŠņ╣ńż╦ØŁ═ūż╩▒ķōQż“Ę┌ż»ż╣żļż┐żßż╬źŲź»ź╬źĒźĖĪ╝ż“├µ┐┤ż╦▓“└ŌżĘżŲżżżļĪŻŗī2ŠŽżŽ3ŗż╦╩¼ż▒żŲĘŪ║▄ż╣żļĪŻ║ŪĮķż╚ż╩żļ2-1żŽĪóCNNż╬┤╦▄╣Į└«ż“Šę▓żĘżŲżżżļĪŻĪ╩ź╗ź▀ź│ź¾ź▌Ī╝ź┐źļįćĮĖ╝╝Ī╦
├°ŪvĪ¦ĖĄ╚ŠŲ│öü═²╣®│žĖ”ē|ź╗ź¾ź┐Ī╝Ī╩STARCĪ╦/ĖĄ┼ņėøĪĪ╝å└źĪĪĘ╝
ŗī1ŠŽż╬╦┴Ų¼żŪ═Į╣żĘż┐ŲŌ═Ųż“╩čśŗżĘĪóŗī2ŠŽżŪżŽČĄ╗šŃ~żĻ│žØ{żŪ▓ĶćĄŪ¦╝▒ż╬┬Õ╔Į┼¬ź═ź├ź╚ź’Ī╝ź»żŪżóżļCNN (Convolutional Neural NetworkĪ¦øQ╣■ż▀ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»)ż“├ōżżżŲĪóźŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż“LSIż╦╝┬äóżĘż┐║▌ż╦─_═ūż╚ż╩żļĘQ¹|ż╬┤¬ĮĻż“└Ō£½ż╣żļĪŻCNNż¼║ŪżŌż╩żĖż▀┐╝ż»Īó└żż╦¾Hż»ż╬╝┬└ėż“æųż▓żŲżżżļż½żķżŪżóżļĪŻ
║ŪĮķż╦Īó2.1Ī┴2.3£IżŪCNNż╬┤╦▄ż“└Ō£½żĘĪóżĮżĘżŲźŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬źóźļź┤źĻź║źÓĪ”źŌźŪźļż╬µ£öüż╬Ų░Ė■ż“▄ć└Ōż╣żļĪŻ├µ╚ūż╬2.4Ī┴2.6£IżŪżŽĪóCNNż╬┬Õ╔Į┼¬ż╩┤÷ż─ż½ż╬źŌźŪźļż╬źóĪ╝źŁźŲź»ź┴źŃĪó╣Į└«═ū┴ŪĪó▒ķōQ┐¶ż╚źčźķźßĪ╝ź┐┐¶ż“żĮż╬┐õöĪż╚Č”ż╦└Ō£½ż╣żļĪŻ║ŪĖÕż╦2.7Īó2.8£IżŪĪó║Ū┐Ęż╬─Ńźėź├ź╚▓ĮĪ”░ĄĮ╠Č\Įčż“Šę▓żĘĪó║Ū┐Ęż╬źŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚Ī╩ex. CNNĪóResNet 34┴žĪ╦ż¼źŌźąźżźļż╦┼ļ║▄▓─ē”Ī╩źĄźų0.1WĄķĪ╦żŪżóżļż│ż╚ż“į~├▒ż╩╗ŅōQż“├ōżżżŲ┐āż╣ĪŻ
ŗī2ŠŽĪ¦źŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬ź╦źÕĪ╝źĒź┴ź├źūżžż╬╝┬äóĪĪĪ┴żĮż╬┤¬ĮĻżŽĪ¬Ī¬Ī┴
2.1 CNN┤╦▄╣Į└«(1)Ī┴▒ķōQźųźĒź├ź»Ī┴
2.2 CNN┤╦▄╣Į└«(2)Ī┴ź═ź├ź╚ź’Ī╝ź»ż╚źčźķźßĪ╝ź┐ Ī┴
2.3 źŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»µ£Ę╩Ī┴źóźļź┤źĻź║źÓĪ”źŌźŪźļĪ┴
2.4 CNNż╬źŌźŪźļż╬┐╩▓Į(1)Ī┴źóĪ╝źŁźŲź»ź┴źŃż╬╩č╔ÅĪ¦żĶżĻ╣Łż»Ī®Ī¬ żĶżĻ┐╝ż»152┴žĪ┴
2.5 CNNż╬źŌźŪźļż╬┐╩▓Į(2)Ī┴╣Į└«═ū┴Ūż╬┤¬ĮĻĪ¦ź▌źżź¾ź╚żŽ5Īó6ź½ĮĻĪ┴
2.6 CNNż╬źŌźŪźļż╬┐╩▓Į(3)Ī┴▒ķōQ┐¶ż╚źčźķźßĪ╝ź┐┐¶Ī¦34┴ž░╠żŪ╬╔żżż╬żŪżŽż╩żżż½?!Ī┴
2.7 źŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»(1)Ī┴źßźŌźĻ╝┬äóż╦┤žż╣żļ╣═╗ĪĪ¦3ż─ż╬ź┐źżźūĪ┴
2.8 źŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»(2)Ī┴źßźŌźĻ╬╠Ś„žō źĄźų0.1WżŌ!źŌźąźżźļż╦źĒź├ź»ź¬ź¾
2.1ĪĪCNN┤╦▄╣Į└«(1)Ī┴▒ķōQźųźĒź├ź»Ī┴
┐▐6ż╦CNNż╬┤╦▄┼¬ż╩▒ķōQźųźĒź├ź»żŪżóżļ┴žż╚┤ž┐¶ż└ż▒żŪ╣Į└«żĘż┐▓ĶćĄŪ¦╝▒Ī╩▐k╚╠رöüŪ¦╝▒Ī╦├ōź═ź├ź╚ź’Ī╝ź»ż╬į~ŠS┐▐ż“┐āż╣ĪŻCNNż“─╠żĘżŲ×┤ō■رĪ╩żęż▐ż’żĻĪóź┴źÕĪ╝źĻź├źūĪóĪ”Ī”Ī”ĪóŪŁ┼∙Ī╣Ī╦ż“╩¼╬Ó(¾Hź»źķź╣╩¼ż▒)ż╣żļĪŻ║ĖŖõż½żķĪųżęż▐ż’żĻĪūż╬▓ĶćĄĪ╩─╠Š’3ĮŚ RGBĪ╦ż“Ų■╬üż╚żĘżŲŲ■żņżļĪŻ┐▐ż╬▓╝├╩żŽŲ■Įą╬üż╬źšźņĪ╝źÓĪ╩│░Ž╚Ī╦ż“Īóæų├╩żŽżĮż╬źšźņĪ╝źÓż╬ŲŌ═ŲżŪżóżļźŪĪ╝ź┐źżźßĪ╝źĖż╬╬«żņż“┐āż╣ĪŻ┐▐ż╬└Ō£½ż“Øi├╩ŗż╬ØŖ─¦├ĻĮąŗż╚ĖÕ├╩ŗż╬╩¼╬Ó▀_ż╦╩¼ż▒└Ō£½ż╣żļĪŻż╩ż¬Īóż│ż╬║ŅČ╚żŽŪ¦╝▒ż╚żżż”╝┬╣įźšź¦Ī╝ź║żŪżóżļĪŻ║ŻövżŽŠ▄żĘż»└Ō£½żĘż╩żżż¼ĪóżĮżņ░╩Øiż╦│žØ{ż╚żżż”║ŅČ╚ż¼╣įż’żņżĮż╬│╬─ĻżĘż┐ź═ź├ź╚ź’Ī╝ź»ż╦▓Ķ楿“Ų■╬üż╣żļĪŻ
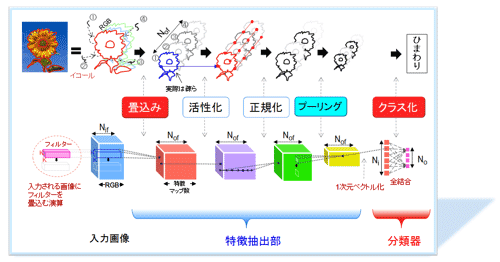
┐▐6ĪĪCNNż╬╣Į└«▄ćŠS
(1) ØŖ─¦├ĻĮąŗ
Øi├╩ż╬ØŖ─¦├ĻĮąŗżŽĪó2ż─ż╬┴žĪ╩øQ╣■ż▀┴žĪ”źūĪ╝źĻź¾ź░┴žĪ╦Ī󿬿Ķżė2ż─ż╬┤ž┐¶Ī╩īÖ└Ł▓Į┤ž┐¶Ī”┘ćæä▓Į┤ž┐¶Ī╦ż½żķż╩żļĪŻĘQ┴žż╚┤ž┐¶ż╦┤žżĘżŲ└Ō£½ż╣żļĪ╩Š▄║┘żŽ╗▓╣═½@╬┴8Īó6╗▓Š╚Ī╦ĪŻ
øQ╣■ż▀┴ž
øQ╣■ż▀┴žż╦┤žżĘżŲżŽ╚ŠŲ│öüżŪ▓Ķ楿╬źšźŻźļź┐ĮĶ═²ż╦Ų▒══ż╬ĮĶ═²ż¼╗╚ż’żņżŲżżżļż╬żŪ²Rģ¢ż▀┐╝żżöĄżŌ¾HżżżŽż║żŪżóżļĪŻ─Š┤Č┼¬ż╦żŽŲ■╬ü▓Ķ楿“Īó╬Ńż©żąŖAżßż╬źšźŻźļź┐ż╩żĻ│╩╗ęėXźšźŻźļź┐Ī╩╗▓╣═½@╬┴6ż╬102╩Ūż╦╝┬║▌ż╬źšźŻźļź┐╬ŃĪ╦ż╩żĻĪóźšźŻźļź┐▒█żĘż╦Ė½ż┐Ų■╬ü▓Ķ楿╬±T▓╠ż“Įą╬üŖõż╦┼Š└^ż╣żļ║ŅČ╚ż╚źżźßĪ╝źĖż╣żļż╚═²▓“żĘżõż╣żżĪ╩╝┬║▌ż╬źšźŻźļź┐żŽż½ż╩żĻŠ«żĄżżźĄźżź║3x3ĮjżŁż»żŲżŌ11x11żŪżóżļż¼Ī╦ĪŻŲ▒żĖż»ĪųøQ╣■ż▀Īūż╬ź═Ī╝ź▀ź¾ź░ż╦┤žżĘżŲżŽ┐▐6ż╬▓╝├╩ż╬▐k╚ų║ĖŖõż╦┘UŲ■żĘż┐┘U│©ż╬══ż╦ĪųŲ■╬üżĄżņżļ▓Ķ楿╦źšźŻźļź┐ż“øQż▀╣■żÓ▒ķōQĪ╩╗▓╣═½@╬┴14Ī╦Īūż╚┬¬ż©żļż╚Ė└±äż╬┴T╠Żż¼Š»żĘżŽżĘż├ż»żĻ═ĶżļĪŻż╩ż¬Īóź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬▒ķōQż╬┤╦▄żŽĪó¾HŲ■╬üż╬└čŽ┬▒ķōQżŪżóżļĪŻĘQŲ■╬üż╦żŽżĮżņżŠżņ│žØ{ż╦żĶżĻ»é─ĻżĄżņż┐╔wŃ~ż╬─_ż▀Ī╩źčźķźßĪ╝ź┐Ī╦ż¼²Xż▒żķżņżļĪŻżĮż╬┴ĒŽ┬ż“īÖ└Ł▓Į┤ž┐¶ż╦─╠żĘżŲ╝Ī├╩ż╦Įą╬üż╣żļĪŻØŁ═ūż╦▒■żĖżŲ┘ćæä▓Į┤ž┐¶ż╬ĮĶ═²ż“╣įż”ĪŻ┐└Ęą║┘╦”źŌźŪźļż╚╚µż┘żļż╚Īó─_ż▀+└čż¼źĘź╩źūź╣ż╬ĄĪē”ż╦┴Ļ┼÷żĘĪó┴ĒŽ┬+īÖ└Ł▓Į┤ž┐¶+Ī╩┘ćæä▓Į┤ž┐¶Ī╦ż╬▒ķōQż¼ź╦źÕĪ╝źĒź¾ż╬ĄĪē”ż╦┴Ļ┼÷ż╣żļĪŻ┐└Ęą║┘╦”źŌźŪźļżŽżŌż├ż╚╩Ż╗©żŪżóżļż¼ź╦źÕĪ╝źķźļź═ź├ź╚żŪżŽż│ż╬żĶż”ż╦į~┴Ū▓ĮżĄżņżŲżżżļĪŻ
ż╩ż¬Īó▓ĶćĄĮĶ═²ż╦Ø{żżĪóźšźŻźļź┐ż╚Š╬żĘż┐ĪóżĮż╬źšźŻźļź┐ż╬═ū┴Ūż¼─_ż▀żŪżóżļĪŻ
ź▐ź├ź»ź╣źūĪ╝źĻź¾ź░┴ž
źūĪ╝źĻź¾ź░┴žż╬├µżŪżĶż»╗╚ż’żņżļź▐ź├ź»ź╣źūĪ╝źĻź¾ź░┴žżŽżĮż╬Ų■╬üĪ╩Øi├╩Ī╦ż╬▐kŗżŪżóżļĪŻ╬Ńż©żą2x2ż╬ČļĘ┴ōļ░Ķż╬4ż─ż╬źµź╦ź├ź╚ż╬║ŪĮj├═ż“Įą╬üĪ╩╝Ī├╩Ī╦ż╬1x1ż╬ōļ░Ķż╦┼Š└^ż╣żļĪŻŲ■╬üōļ░Ķµ£öüż╦Ų▒żĖ┴Ó║Ņż“ź╣źķźżź╔żĘż╩ż¼żķĘ½żĻ╩ųżĘĪóĮą╬üĀCż¼┤░└«ż╣żļĪŻ±T▓╠ĪóĮą╬üźĄźżź║ż¼1/4ż╦ż╩żļĪŻ░╩æTĪó╝ŖōQ╬╠żŌ1/4ż╦ż╩żļĪŻ
▓ĶćĄŪ¦╝▒ż╬Ė·▓╠ż╚żĘżŲżŽ2ż─żóżĻĪóČ”ż╦CNNż╬ĮjżŁż╩ØŖ─╣ż“└«żĘżŲżżżļĪŻ1ż─żŽ£å┼└ż¼ź▀ź»źĒż½żķź▐ź»źĒż╦│╚Įjż╣żļ┼└żŪżóżļĪŻ┐▐6żŪżŽźĄźżź║ż¼Š«żĄż»ż╩żļĪŻżĘż½żĘżĮż╬═ū┴ŪżŪżóżļæųĮęż╬1x1ōļ░ĶżŽź▐ź├ź»ź╣źūĪ╝źĻź¾ź░ĮĶ═²Øiż╬żĶżĻź▐ź»źĒż╩2x2ż“┬Õ╔ĮżĘżŲżżżļĪŻż╣ż╩ż’ż┴żĶżĻĮjżŁż╩ōļ░ĶżŪØŖ─¦ż“┬¬ż©żļż│ż╚ż¼▓─ē”ż╚ż╩żļĪŻżŌż”1ż─żŽŲ■╬ü▓ĶćĄŲŌż╬×┤ō■رĪ╩żęż▐ż’żĻĪ╦ż╬┤÷▓┐Ī╩ĮjŠ«Īóöv┼ŠĪóźĘźšź╚Ī╦╩č▓Įż╦×┤ż╣żļ╔į╩č└Łż“żŌż┐żķż╣ĪŻż╣ż╩ż’ż┴×┤ō■رĪ╩żęż▐ż’żĻĪ╦ż╬Ų■╬ü▓ĶĀCŲŌżŪż╬░╠ÅøĪóĮjżŁżĄż╦żĶżķż║Īóż▐ż┐öv┼ŠżĘżŲżŌĪ╚żęż▐ż’żĻĪ╔ż╚Ū¦╝▒żŪżŁżļĪŻź▐ź├ź»ź╣źūĪ╝źĻź¾ź░ż“ĖÕĮęż╣żļCNNż╬┬Õ╔Į┼¬ż╩źŌźŪźļż╬AlexNetżŽ3övĪóVGGNetżŽ5övĪóżĮżĘżŲGoogLeNetżŽ4övĪ╩ż┐ż└żĘĪóVersion1żŪżŽInception LayerŲŌż╦Slideż¼1ż╬źūĪ╝źĻź¾ź░┴žż“¾H├ōżĘżŲżżżļĪ╦╗╚├ōż╣żļĪŻResNetżŪżŽ1öv╗╚├ōż╣żļĪŻż┴ż╩ż▀ż╦øQ╣■ż▀┴žż╬źšźŻźļź┐┴Ó║ŅżŌō¶─╠ż├żŲżżżļż╬żŪæųĄŁż╬2ż─ż╬Ė·▓╠ż“øQ╣■ż▀┴žż╦“EżĻ╣■żÓĄ£ż¼▓─ē”ż╚╣═ż©żķżņżļĪŻż╚ż╣żļż╩żķżąĪóź▐ź├ź»ź╣źūĪ╝źĻź¾ź░┴žżŽż╩ż»żŲżŌżĶżż▓─ē”└ŁżŌżóżļĪŻż┐ż└żĘŲŌŗżŽżĶżĻźųźķź├ź»ź▄ź├ź»ź╣▓Įż╣żļĪŻ
īÖ└Ł▓Į┤ž┐¶
īÖ└Ł▓Į┤ž┐¶żŽĪó┐└Ęą║┘╦”ż╬żĶż”ż╦▒ķōQĪ╩└čŽ┬Ī╦ż╬±T▓╠ż“ØÖ└■Ę┴ż╦╩č┤╣ż╣żļ┤ž┐¶żŪżóżļĪŻ¹|Ī╣ż╬ØÖ└■Ę┴┤ž┐¶ż¼─¾░ŲżĄżņżŲżŁż┐╬“╗╦ż¼żóżļż¼ĪóżĮż╬┴T╠Ż╣ńżżżŽ▐kĖ└żŪżŽ┬¬ż©ż╦ż»żżĪŻ╝┬żŽ│žØ{╗■ż╬ĖĒ║╣Ąš┼┴ś“╦Ī┼¼├ōż╬║▌ż╬╚∙╩¼ĮĶ═²ż¼ź╣ź▐Ī╝ź╚ż╦╣įż©żļż│ż╚ż¼┤ž┐¶ż╦ĄßżßżķżņżļżĶż”ż└ĪŻWikiPediaĪ╩╗▓╣═½@╬┴15Ī╦żŪżŽĪóĪų┐═╣®┐└Ęąż╬īÖ└Ł▓Į┤ž┐¶żŽĪóź═ź├ź╚ź’Ī╝ź»ż“äė▓Įż▐ż┐żŽ├▒ĮŃ▓Įż╣żļżĶż”ż╩ØŖ└Łż“Ęeż─żŌż╬ż¼┬ōżążņżļĪūż╚Į±ż½żņżŲżżżļĪŻ2015ŃQ5ĘŅ╗©╗’Natureż╦źķź¾źū┤ž┐¶ż╬ReLUĪ╩Rectified Linear UnitĪ¦┘ćż╬├═żŽżĮż╬ż▐ż▐ź╣źļĪ╝żĘĪó╔ķż╬├═żŽ0ż╚Ė½ż╩ż╣Ī¦╗▓╣═½@╬┴6Īó8Ī╦ż¼║ŪżŌ╗╚ż’żņżŲż½ż─żĶżĻ╣ŌÅ]ż╦│žØ{ż╣żļż╚Į±ż½żņżŲżżżļĪ╩Y. LeCun, Y. Bengio, G. HintonČ”├°Ī¦╗▓╣═½@╬┴16Ī╦ĪŻĖĮ║▀ż█ż╚ż¾ż╔ż╬źŌźŪźļż¼ReLUż“╗╚├ōżĘżŲżżżļĪŻ
┘ćæä▓Į┤ž┐¶
┘ćæä▓Į┤ž┐¶ż╦┤žżĘżŲżŽ═ŠżĻ╗╚ż’żņżŲżżż╩ż½ż├ż┐żĶż”ż└ż¼Īó2015ŃQ3ĘŅż╦─¾░ŲżĄżņż┐Batch NormalizationĪ╩2.3£IżŪį~├▒ż╦└Ō£½Ī╦żŽżĶż»╗╚ż’żņżŲżżżļ(GoogLeNetĪóResNet)ĪŻż▐ż┐Īó2.8£IżŪ└Ō£½ż╣żļBinarized NetżŪżŽ─_═ūż╩┴T╠Żż“Ęeż├żŲżżżļżķżĘżżĪŻ
ØŖ─¦ź▐ź├źū┐¶Ī╩NifĪóNofĪ╦
┐▐6ż╬ØŖ─¦├ĻĮąŗż“─╠āįż╣żļż│ż╚ż╦żĶżĻĪųżęż▐ż’żĻĪūż╬▓Ķ楿½żķ╩Ż┐¶ż╬ØŖ─¦ź▐ź├źūż“├ĻĮąż╣żļĪŻż╩ż¬ĪóNofĪ╩Number of output feature mapsĪ╦żŽ┴žż╬Įą╬üŖõż╬ØŖ─¦ź▐ź├źūż╬┐¶żŪĪóNif(Number of input feature maps)żŽŲ■╬üŖõż╬ØŖ─¦ź▐ź├źū┐¶żŪżóżļĪŻīÖ└Ł▓Į┤ž┐¶Īó┘ćæä▓Į┤ž┐¶Ī󿥿ķż╦źūĪ╝źĻź¾ź░┴žż“ĘążŲżŌź▐ź├źū┐¶NofżŽ╩čż’żķż╩żżĪŻ
(2) ╩¼╬Ó▀_
µ£±T╣ń┴ž
ĖÕ├╩ż╬╩¼╬Ó▀_ż╦░·żŁ┼Žż╣║▌ż╦Īųżęż▐ż’żĻĪūż╬ØŖ─¦ź▐ź├źūż“1╝ĪĖĄż╬ź┘ź»ź╚źļż╦╩┬ż┘ü÷ż©żļĪŻĖÕ├╩ż╬╩¼╬Ó▀_żŪżŽ3Ė─Ī╩1Ė─żŌżóżĻĪ╦µć┼┘ż╬µ£±T╣ń┴žĪ╩×┤Ė■ż╣żļ2Ė─ż╬ź┘ź»ź╚źļż╬µ£źµź╦ź├ź╚ż¼µ£żŲ±T╣ńĪ╦ż¼╝ĪĪ╣ż╚╗┼╩¼ż▒ż“╣įżż╩¼╬ÓĪ╩¾Hź»źķź╣▓ĮĪ╦żĘżŲ║ŪĮķż╬▓ĶćĄŲ■╬üż¼▓┐żŪżóżļż½ż“╚Įéāż╣żļĪŻ
īÖ└Ł▓Į┤ž┐¶Softmax
żĮż╬╚ĮéāżŽ║ŪĮ¬├╩ż╬NoĖ─ż╬Įą╬ü├═żŪ╚Į─Ļż╣żļĪ╩NoĖ─Ī¦Number of output ź»źķź╣┐¶ż╬Ė─┐¶Ī¦ILSVRC/Imagenetż╬ź┘ź¾ź┴ź▐Ī╝ź»ż╬▐k╚╠رöüŪ¦╝▒ż╬ź»źķź╣┐¶żŽ1000Ė─Ī╦ĪŻ╝┬żŽĪó║ŪĮ¬├╩ż╦żŽSoftmaxĪ╩╗▓╣═½@╬┴6Ī╦ż╚żżż”īÖ└Ł▓Į┤ž┐¶ż¼╗╚├ōżĄżņĪó├═żŽ╚µ╬©ż╦╩č┤╣żĄżņżŲĮą╬üżĄżņżļ╗┼²Xż▒ż╦ż╩ż├żŲżżżļĪŻSoftmaxż╦żŽź│ź¾ź╚źķź╣ź╚ż“äėż»ż╣żļŲ»żŁżŌżóżļĪŻ
ź»źķź╣ż╚╚Į─Ļ
żĮż╬├µż╬Ī╚żęż▐ż’żĻĪ╔ż╬ź»źķź╣ż╬│╬╬©ż¼▐k╚ų╣ŌżżżŽż║żŪżóżļĪŻ╬Ńż©żąĪó80%ĪŻżĮż╬║▌┬Šż╬ź»źķź╣żŽĪ╚ź┴źÕĪ╝źĻź├źūĪ╔żŽ19%ż╚ż½ĪóĪ╚ŪŁĪ╔1%ż╚ż½ż╦ż╩żļĪŻŲ■╬ü▓Ķ楿Žżęż▐ż’żĻż╦▐k╚ųō¶żŲżżż┐ż¼Īó╝┬żŽŲ■╬ü▓Ķ楿╬żęż▐ż’żĻż╬▐kŗĪó╬Ńż©żą±äż├żčż╬Ę┴ėXż¼ź┴źÕĪ╝źĻź├źū±äż├żčż╦Š»żĘō¶żŲżżż┐ż╚╚Į─ĻżĄżņĪóź┴źÕĪ╝źĻź├źūż╬│╬╬©ż¼19%ż╬±T▓╠ż╦ż╩ż├ż┐ż╚żżż”┤ČżĖżŪżóżļĪŻż┴ż╩ż▀ż╦ż│ż│żŪ└Ō£½żĘż┐Øi├╩ż╬ØŖ─¦├ĻĮąŗżŽ─╠Š’╩Ż┐¶övĘ½żĻ╩ųżĄżņĪóØŖ─¦ź▐ź├źūż“ź▀ź»źĒż╩£å┼└ż½żķź▐ź»źĒż╩£å┼└żžż╚╩čż©żŲ╣įż»ĪŻ╬Ńż╚żĘżŲżŽżęż▐ż’żĻż½żķ▀`żņżļż¼Īó┐═┤ųż╩żķ£å┼└ż¼ź▀ź»źĒż╩╝¬ż╚żżż”Š«żĄż╩żŌż╬ż½żķĪóĮjżŁż»ż╩żĻŲ¼żŪĪ󿥿ķż╦żŽź▐ź»źĒż╩öüżŪż╚żżż”╬«żņżŪżóżļĪŻżĶżĻĮjČ╔┼¬ż╦ØŖ─¦ż“┬¬ż©żŲ╩¼╬ӿʿŲżżżļĪŻ
(3) ź»źķź╣ż╚żŽĪóżĮżĘżŲ│žØ{ż╚żŽ
║ŪĮķżŽ▓Ķ楿“Ų■żņżļż╚ĮjżŁż╩ĖĒ║╣ż¼Įążļ
ż│ż│żŪź»źķź╣ż╚żŽ▓┐ż½ż╚żżż”ż│ż╚ż“į~├▒ż╦└Ō£½ż╣żļĪŻĄ£Øiż╦│žØ{ż╬źšź¦Ī╝ź║żŪĪó╬Ńż©żą┐═┤ųż¼ż╔ż”Ė½żŲżŌĪ╚żęż▐ż’żĻĪ╔ż╚╗ūż©żļ▓Ķ楿“1000ĮŚ┬Ęż©żŲĪóæųĄŁż╬┐▐6ż╬ź═ź├ź╚ź’Ī╝ź»ż╬║ĖŖõż½żķŲ■╬üż╣żļĪŻĮą╬üżŽĪóżęż▐ż’żĻż╬ź»źķź╣Īóź┴źÕĪ╝źĻź├źūż╬ź»źķź╣ĪóŪŁż╬ź»źķź╣ż╬3ż─ż¼żóżļż╚ż╣żļĪŻż│żņżķż╬ź»źķź╣ć@żŽØiżŌż├żŲ┐═┤ųż¼»éżßżļĪŻ│žØ{ż╬║ŪĮķż╬1ĮŚų`żŪżŽĪóżęż▐ż’żĻź»źķź╣ż╬│╬╬©żŽ▓Šż╦33%ż╚ż╣żļĪ╩3ź»źķź╣ż└ż├ż┐żķ╩┐Č迎33%Ī╦ĪŻ═²„[┼¬ż╩Įą╬üżŽĪóżęż▐ż’żĻż╬ź»źķź╣żŽ100%żŪ┬Šż╬ź»źķź╣żŽ0%ż╬żŽż║żŪżóżļĪŻżĮż╬ĖĒ║╣╩¼(100-33) %ż“┴Ļ£¹ż╣żļż┐żßż╦ĪóżĶżĻżęż▐ż’żĻż╬ź»źķź╣ż╬╚µ╬©ż¼æųż¼żļżĶż”ż╦├µ┤ųż╬ź═ź├ź╚ź’Ī╝ź»ż╬─_ż▀ż“─┤┼Dż╣żļĪŻ─╠Š’▐k┼┘ż╦ź╔ź¾ż╚żŽżõżķż║└ąČČż“ųÖż»żĶż”ż╦żĖż’żĖż’żõżļĪŻ
źčź┴ź¾ź│ż╬┼Ż╗šż╚ĖĒ║╣Ąš┼┴ś“╦Ī
│žØ{ż╬öĄ╦ĪżŽźčź┴ź¾ź│ż╬┼Ż╗šż╬╗┼Ą£ż╦ō¶żŲżżżļĪŻ─╠Š’Īó╩─ܬĖÕż╦╣įż”ĪŻ╚ūĀCż╬╠Ą┐¶ż╬┼Żż“źŽź¾ź▐Ī╝żŪųÖżżżŲ│č┼┘ż“╚∙─┤żĘĪóźčź┴ź¾ź│Č╠ż╬╬«żņż“╩čż©Īóź█Ī╝źļĘĻż╦Ų■żļ│╬╬©ż“─┤┼Dż╣żļ╗┼Ą£żŪżóżļĪŻźčź┴ź¾ź│ܬż╬żŌż”ż▒ż╦─Š±Tż╣żļĪŻżęż╚┼Ż─ŠżĘż┐żķĪóż▐ż┐źčź┴ź¾ź│Č╠ż“╚¶żążĘżŲ══╗ęż“Ė½żļĪŻżęż╚┼Ż╦ĶĪó╚ūĀCµ£ĀCŃæųtż╦─┤┼DżĘżŲ╣įż»ĪŻźčź┴ź¾ź│ż╬ź█Ī╝źļĘĻż╦ŖZżż┼Żż█ż╔Ų■żļ│╬╬©ż╦ĮjżŁż»▒Ųūxż╣żļż╬ż¼─╠Š’żŪżóżļĪŻĖ╬ż╦Īóź█Ī╝źļĘĻż╦ŖZżż┐▐6żŪżżż”ż╚Įą╬üŖõż½żķĄšöĄĖ■ż╦Īó┼Żż“╚∙─┤Ī╩╚∙╩¼Ī╦żĘżŲż┴żńż├ż╚żĘż┐Ų■żĻÉ║╣ńż╬░ŃżżĪ╩Įą╬üż╬ĖĒ║╣╩¼Ī╦ż“╚ūĀCĪ╩ź═ź├ź╚ź’Ī╝ź»µ£öüĪ╦ż╦╩¼ÜgżĄż╗żļĪŻż│żņż¼ĖĒ║╣Ąš┼┴ś“╦Īż╬źżźßĪ╝źĖżŪżóżļĪ╩żŌż┴żĒż¾Īó╝ŖōQżŽź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬┤ž┐¶/Ų│┤ž┐¶ż“├ōżżżŲ╣įż”Ī╦ĪŻ
(4) ČĄ╗šŃ~żĻ│žØ{
│žØ{╗■żŽĪóĄ£Øiż╦┐═┤ųż¼┬ōżĻż╣ż░ż├ż┐Ī╚żęż▐ż’żĻĪ╔ĪóĪ╚ź┴źÕĪ╝źĻź├źūĪ╔ĪóĪ╚ŪŁĪ╔ż“ĘQĪ╣╬Ńż©żą1000ĮŚż┤ż╚Īó╣ń╝Ŗ3000ĮŚż“╬«ż╣ż│ż╚ż╦żĶż├żŲź═ź├ź╚ź’Ī╝ź»ż¼│╬─ĻĪ╩─_ż▀»éżßĪ¦─_ż▀ż╦┤žżĘżŲżŽ╝Ī£IżŪ└Ō£½ż╣żļĪ╦ż╣żļĪŻż╚Ų▒╗■ż╦Įą╬üŖõż¼│žØ{ØiżŽć@żąż½żĻżŪżóż├ż┐ż¼ć@ż╦├čżĖż╠┐┐ż╬3ż─ż╬ź»źķź╣ż╦└«─╣ż╣żļĪŻż│żņż¼żżż’żµżļČĄ╗šŃ~żĻ│žØ{żŪżóżļĪŻČĄ╗šŃ~żĻ│žØ{żŽĪó║ŅČ╚┼¬ż╦żŽČĄ╗š▓ĶćĄĪ╩ź»źķź╣ż¼Ą£Øiż╦»éżßżķżņż┐▓ĶćĄĪ╦ż╬╝┬╣įż╚ĖĒ║╣Ąš┼┴ś“╦Īż╦żĶżļ─_ż▀ż╬╚∙─┤ż╬2ż─ż╬║ŅČ╚ż╬Ążż¼▒¾ż»ż╩żļż█ż╔ż╬Ę½żĻ╩ųżĘżŪżóżļĪŻż│żņż¼śOŲ░żŪż½ż─ź┐ź╣ź»ų`┼¬ż╦żĶżķż║└@├ō┼¬ż╦żŪżŁżļż╬ż¼ĖĒ║╣Ąš┼┴ś“╦Īż╬═źżņż┐┼└żŪżóżļĪŻ░╩æųż¼ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬│žØ{ż╬źżźßĪ╝źĖżŪżóżļĪŻżĮż│ż╦¹|Ī╣ż╬Č\╦ĪĪ╩2.3£IżŪ▐kŗŠę▓Ī╦ż¼įćż▀ĮążĄżņ¾H┴žĪ╩3┴ž░╩æųżžż╬·t│½ż¼║żžMż╩┼▀ż╬╗■┬Õż¼żóż├ż┐ż¼Ī╦żžż╬·t│½ż¼▓─ē”ż╦ż╩ż├ż┐ĪŻż│żņż¼┐╝┴ž│žØ{Ī╩źŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░Ī╦żóżļĪŻżĮż╬Č\╦Īż╬ŲŌ═ŲżŽ2.3£IżŪŠę▓ż╣żļż¼Īó¾Hż»ż¼×┤ĮĶ┬ä╦Ī┼¬ż╦Ė½ż©żļĪŻ▒¾ż½żķż║┐═┤ųż╬╦Nż╬ĄĪē”ż“╠Ž╩’żĘżŲżżżļż╚żŽĖ└ż©Īó┐¶╝░ĮĶ═²ż╬╠ĄĄĪ䮿╩Č\╦Īż╬ĮĖ├─ż╦Ė½ż©żļĪŻżĘż½żĘĪóżĮżņĖ╬ż╦└@├ō┼¬żŪ╣ŁšJż╩ź┐ź╣ź»ż╦·t│½żŪżŁżļż╚═²▓“żĘżŲżżżļĪŻ
(5) │žØ{żĘż┐ē¶╝▒żŽ─_ż▀Ī╩źčźķźßĪ╝ź┐Ī╦ż╦├▀ż©żķżņżļ
øQ╣■ż▀┴žż╚ź»źķź╣▓Į┴žĪ╩µ£±T╣ń┴žĪ╦ż└ż▒ż¼─_ż▀Ī╩źčźķźßĪ╝ź┐Ī╦ż“Ęeż─ż│ż╚ż½żķ─_═ūżŪżóżļĪŻżĮż╬─_ż▀ż╬┐¶żŽLSIż╬ź┴ź├źūźĄźżź║Īóź╣źįĪ╝ź╔ĪóżĮżĘżŲźčź’Ī╝ż╦─Š±Tż╣żļĪŻ
ż╩ż¬Īó┴žż╬ź½ź”ź¾ź╚żŽĪó¾Hż»ż╬Šņ╣ńżŽ─_ż▀Ī╩░╩æT─_ż▀ż“╝┬äóż╣żļ└Ō£½ż╬║▌ż╦żŽźčźķźßĪ╝ź┐ż╚Š╬ż╣Ī╦ż“Ń~ż╣żļ┴žżŪ┐¶ż©żļĪŻ┐▐6żŽøQ╣■ż▀┴žż╚ź»źķź╣▓Į┴žĪ╩µ£±T╣ń┴žĪ╦ż╬2┴žż╚ź½ź”ź¾ź╚żĄżņżļĪŻźūĪ╝źĻź¾ź░┴žżŽź½ź”ź¾ź╚żĘż╩żżż╬ż¼─╠╬Ńż╬żĶż”żŪżóżļĪŻ
2.2ĪĪCNN┤╦▄╣Į└«(2)Ī┴ź═ź├ź╚ź’Ī╝ź»ż╚źčźķźßĪ╝ź┐Ī┴
ŗī1ŠŽżŪżŌŠę▓żĘż┐ż╚ż¬żĻĪóźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╦ż╚ż├żŲĄŁŪ░╚Ļ┼¬ż╚Ė└ż’żņżŲżżżļCNNż╬źŌźŪźļżŪżóżļAlexNetż“├ōżżżŲĪóźŪĪ╝ź┐ż╬źšźĒĪ╝ż╚źčźķźßĪ╝ź┐ż╬Ų»żŁż“└Ō£½ż╣żļĪŻ
(1) źŪĪ╝ź┐ż╬╩č┤╣źšźĒĪ╝
┐▐7ż╦AlexNetĪ╩╗▓╣═½@╬┴23Ī╦ż╬ź═ź├ź╚ź’Ī╝ź»Ī╩æų├╩Ī╦ĪóźčźķźßĪ╝ź┐Ī”─_ż▀Ī╩├µ├╩Ī╦ĪóżĮżĘżŲ├▒ĮŃĮĶ═²Ī╩▓╝├╩Ī╦ż“┐āż╣ĪŻ║ĖŖõż½żķ▓ĶćĄĪ╩ĖżĪóWalker HoundĪ╦ż¼Ų■╬üżĄżņĪóīÜż╦Ė■ż½żżĮĶ═²żĄżņżļĪŻīÜŖõż╬±T▓╠żŽĪ󟻟ķź╣ż┤ż╚ż╦╚µ╬©Ī╩┐▐7īÜŖõż╬┘UŲ■┐▐ż╬╦└ź░źķźšĪó1000ź»źķź╣ż╬├µżŪ5ź»źķź╣ż╬±T▓╠ż“╔Į┐āĪ╦żŪ┐āżĄżņżļĪŻøQ╣■ż▀┴žż¼5övĘ½żĻ╩ųżĄżņżļĪŻźūĪ╝źĻź¾ź░┴žżŽ3övżŪżóżļĪŻĖÕ├╩ŗż╦żŽĪ󟻟ķź╣▓Įż“├┤ż”µ£±T╣ń┴žĪ╩FC1żŽ9216ż╚4096ż╬µ£±T╣ńĪ╦ż¼3övżóżļĪŻīÖ└Ł▓Į┤ž┐¶ż╚żĘżŲżŽReLUż¼Īóż▐ż┐║ŪĮ¬├╝ż╦Softmaxż¼╗╚ż’żļĪŻØi£IżŪżŌĮęż┘ż┐żĶż”ż╦Īó─_═ūż╩ż╬żŽøQ╣■ż▀┴žĪ╩░╩æTConv┴žż╚╔Į┐āĪ╦ż╚ź»źķź╣▓Įż“╣įż”µ£±T╣ń┴žĪ╩Fully Connected┴žĪ╦ż╬└čŽ┬▒ķōQöv┐¶ż╚żĮż╬║▌ż╦╗╚├ōżĄżņżļźčźķźßĪ╝ź┐ż╬┐¶żŪżóżļĪŻźčźķźßĪ╝ź┐┐¶żŽ┴Ē┐¶62MĖ─Īó└čŽ┬▒ķōQöv┐¶żŽ11▓»4000╦³övĪ╩1ĮŚż╬▓ĶćĄĮĶ═²Ī╦żŪżóżļĪŻż╩ż¬Īóź═ź├ź╚ź’Ī╝ź»żŽØi├╩ŗż╬ØŖ─¦├ĻĮąŗżŪżŽ3╝ĪĖĄżŪż╬▒ķōQż“╣įżżĪóĖÕ├╩ŗżŪżŽ1╝ĪĖĄż╚ż╩żļĪŻźčźķźßĪ╝ź┐żŽĪóØŖ─¦├ĻĮąŗżŪżŽ3╝ĪĖĄż╬źčźķźßĪ╝ź┐ż“ØŖ─¦ź▐ź├źū┐¶╩¼Ęeż─ż╚╔ĮĖĮżĄżņżļĪŻ╝┬䮿Ž4╝ĪĖĄżŪżóżļĪŻ
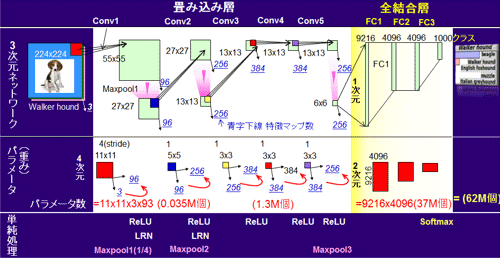
┐▐7ĪĪCNNź═ź├ź╚ź’Ī╝ź»ż╚źšźŻźļź┐ż╬Š▄║┘
(2) └čŽ┬▒ķōQöv┐¶ż╚źčźķźßĪ╝ź┐┐¶ż“Ė½└čżŌżļ
└čŽ┬▒ķōQż╬öv┐¶ż╚źčźķźßĪ╝ź┐┐¶ż╦ŠÆų`żĘ└Ō£½ż╣żļĪŻ║ŪĮķż╬Conv1┴žż╬└čŽ┬▒ķōQż╬öv┐¶żŽŲ■╬ü3xĪ╩224x224Ī╦ż½żķĮą╬ü96xĪ╩55x55)żžż╬└▄¶ö┐¶ż╬┴ĒŽ┬ż╚ż╩żļĪŻ└▄¶ö┐¶ż╬┴ĒŽ┬żŽ3x(11x11)x(55x55)x96ż╚ż╩żļĪŻ└▄¶öż╬╝ŖōQżŽŲ■╬ü224x224ż“╗╚ż’ż║ĪóźšźŻźļź┐źĄźżź║11x11ż“┤ż╦╝ŖōQż╣żļĪŻźšźŻźļź┐ż¼Stride 4Ī╩ź╣źŲź├źūż¼4źµź╦ź├ź╚╩¼żŪĪó║ĖīÜĪóæų▓╝ż╦öĪŲ░Ī╦żŪöĪŲ░żĘĪó55x55övĘ½żĻ╩ųżĘ╗╚├ōĪ╩└▄¶öĪ╦żĄżņżļĪŻĖÕżŽĪóŲ■╬üŖõĪóĮą╬üŖõż╬ź▐ź├źū┐¶3ż╚96ż“²Xż▒żļĪŻ
źčźķźßĪ╝ź┐┐¶ż╬ōQĮąöĄ╦Īż╦┤žżĘżŲ└Ō£½ż╣żļĪŻŲ■╬üż╦×┤żĘżŲ11x11ż╬źšźŻźļź┐▒ķōQĪ╩Matrix MultiplicationsĪ╦ż“55x55öv╣įżżĪóż½ż─RGB 3öv╩¼Ę½żĻ╩ųż╣ĪŻżĄżķż╦Ų▒żĖż│ż╚ż“Įą╬üŖõż╬ź▐ź├źū┐¶96övĘ½żĻ╩ųż╣ĪŻźčźķźßĪ╝ź┐┐¶żŽĪó3x(11x11)x96ż╚ż╩żļĪŻ
└čŽ┬▒ķōQż╬öv┐¶ż╚ĪóźčźķźßĪ╝ź┐┐¶ż╬║╣żŽ55x55ż╬Ń~╠Ąż╦ż╩żļĪŻCNNż╬Šņ╣ńż╦żŽźšźŻźļź┐ż“ź╣źķźżź╔żĘżŲżŌŲ▒żĖżŌż╬Ī╩─_ż▀Č”Ń~Ī¦Weight sharingĪó╗▓╣═½@╬┴6ż╬89╩ŪĪ╦ż“╗╚żżövż╣ż╬ż¼żĮż╬Ń~╠Ąż╬═²ĮyżŪżóżļĪŻżĮż╬╗╚żżövżĘż╬öv┐¶żŽĮą╬üż╬źĄźżź║55x55ż╦┼∙żĘżżĪŻ±T▓╠Īó▒ķōQ┐¶ż╦×┤żĘżŲ2Ī┴3ĘÕŠ»ż╩żżźčźķźßĪ╝ź┐Ī╩źßźŌźĻ╬╠Ī¦Š▄║┘żŽ2.6£IĪ╦┐¶żŪżĶżżż│ż╚ż╦ż╩żĻźŽĪ╝ź╔ź”ź¦źóżžż╬╔ķ├┤żŌŠ»ż╩ż»ż╩żļĪŻ║“║ŻCNNż¼ŠåŚ„ż╦╚»·tżĘż┐═²Įyż╬▐kż─żŪżóżļĪŻĄšż╦CNNż“╗╚├ōż╗ż║╩╠ż╬źóźļź┤źĻź║źÓż╬╗╚├ōż“╣═ż©żļż╚ĪóŠņ╣ńż╦żĶż├żŲżŽ2Ī┴3ĘÕæųż╬└Łē”ż“Ęeż─źŽĪ╝ź╔ź”ź¦źóż¼ØŁ═ūż╚ż╩żļż│ż╚ż“┴T╠Żż╣żļĪ╩2.8£I╗▓Š╚Ī╦ĪŻ
Ąšż╦ĪóĖÕ├╩ŗż╬µ£±T╣ńŗ╩¼żŪżŽ├▒ż╩żļ²Xż▒ōQĪ╩╬Ńż©żą 9216x4096Ī╦ż╦ż╩żļĪŻźčźķźßĪ╝ź┐┐¶żŽ¾Hż»Īóź═ź├ź╚µ£öüż╬90%ØiĖÕĪ╩AlexNetżŪżŽ94%Ī¦2.5£Iż“╗▓Š╚Ī╦ż“ĖÕ├╩ŗż¼žéżßżļĪŻ
(3) ╝ŖōQ╬╠ż“žōżķż╣ż┴żńż├ż╚äė░·ż╩öĄ╦ĪĪóź▐ź├ź»ź╣źūĪ╝źĻź¾ź░┴ž
╝┬äóż╬ćĶ┼└ż½żķĖ½żļż╚Īóź▐ź├ź»ź╣źūĪ╝źĻź¾ź░┴žż╬ĮĶ═²żŽµ£öüż╬▒ķōQ╬╠ż½żķż▀żļż╚ż█ż╚ż¾ż╔╠Ą£åżŪżŁżļĪŻConv1┴žż╬ĖÕż╦żóżĻĪó55x55ó¬27x27ż╚źĄźżź║ż“1/4ż╦żĘżŲżżżļĪŻż╣ż╩ż’ż┴żĮżņ░╩æTż╬▒ķōQ╬╠ż“1/4ż╦ż╣żļØÖŠ’ż╦ż¬żżżĘżżĄĪē”żŪżóżļĪŻŲ▒══ż╬▒ķōQ╬╠║’žōż╬Š}╦Īż╚żĘżŲBottleneck ModuleĪ╩╝Īöv2.4£I/┐▐10Ī╦.ż╩żļżŌż╬ż¼żóżļĪŻAlexNetżŪżŽ╗╚├ōżĘżŲżżż╩żżż¼Īó1x1ż╬źšźŻźļź┐ż“╗╚├ōżĘżŲØŖ─¦ź▐ź├źū┐¶ż“śOĮyż╦╗\žōż╣żļĪŻ║“║Ż¾H├ōżĄżņżŲżżżļĪŻ
2.3ĪĪźŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»µ£Ę╩Ī┴źóźļź┤źĻź║źÓĪ”źŌźŪźļĪ┴
CNNż╬źóźļź┤źĻź║źÓĪ”źŌźŪźļµ£öüżŽĪó┐▐8ż╬żĶż”ż╦·t│½żĄżņżŲżŁż┐ĪŻż│ż╬┐▐żŽĪóCNNż╬Ų░Ė■Ī╩╗▓╣═½@╬┴14Ī╦ż“ź┘Ī╝ź╣ż╦Īó┬Šż╬źóźļź┤źĻź║źÓĪ”źŌźŪźļż╚ŽóĘ╚żĘż┐╩Ż╣ńĄĪē”ż╬Ų░Ė■Ī╩╗▓╣═½@╬┴17Ī┴20┼∙Ī╦ż“▓├ż©╣Į└«żĘż┐ĪŻ2016ŃQż╬Ų░Ė■żŌ▓├╠ŻżĘż┐ĪŻ
(1) µ£öüż╬·t│½
·t│½ż╬öĄĖ■└ŁżŽĪóźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░żŌżĘż»żŽCNNż╬═²éb┼¬ż╩Īų═²▓“Īūż“żĶżĻ┐╝żßżĶż”ż╚ż╣żļŲ░żŁĪó╝Īż╦Ū¦╝▒╬©źóź├źūż“ż╚ż│ż╚ż¾╝{Ąßż╣żļĪų╣Ō└Łē”▓ĮĪūż╬Ų░żŁĪ󿥿ķż╦żŽĪó┬Šż╬źóźļź┤źĻź║źÓż╚ż╬┴╚ż▀╣ńż’ż╗ż╦żĶżļĪų╩Ż╣ńĄĪē”▓ĮĪ╩ź▐źļź┴Ī╦Īūż╬3ż─ż╦Įj╩╠żĄżņżļĪŻżĮż╬┬Šż╦Īóźóźļź┤źĻź║źÓĪ╩ØŖż╦CNNĪ╦ż╬äŅ║▀ē”╬ü╚»┘Eż╦żĶżļĪų╣ŌĄĪē”▓ĮĪūż╬Ų░żŁż¼żóżļĪŻż│żņżŽź═ź├ź╚ź’Ī╝ź»ż╬ŲŌŗż╬ėX▌åĪ”Ų░żŁż“┐╝ż»├Ążļż│ż╚ż╦żĶżĻĖ▓║▀▓ĮĪ”╚»·tżĘż┐Īų═²▓“Īū╝{Ąßż╬├µżŪÖ┌ż▐żņż┐└«▓╠ż╚Ė½żļż│ż╚żŌżŪżŁżļĪŻ

┐▐8ĪĪźŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬µ£Ę╩Ī╩źóźļź┤źĻź║źÓĪ”źŌźŪźļĪ╦ĪĪ2012ŃQ░╩æTż╦ŠÆų`.
(2) ╣Ō└Łē”▓Į
Īų╣Ō└Łē”▓ĮĪūż╬Ų░żŁżŽĪŃČ\╦ĪĪõĪóĪŃ╣Į└«ĪõĪóżĮżĘżŲĪŃ╣ŌÅ]▓ĮĪ”ź│ź¾źčź»ź╚▓ĮĪõż╬3ż─ż╦╩¼▓“żĄżņżļĪŻ
ĪŃČ\╦ĪĪõ 1ż─ų`żŽźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╬ź│źóČ\ĮčżŪżóżļ¾H┴žĪ╩źŪźŻĪ╝źūĪ╦żŪż╬│žØ{Ī╩źķĪ╝ź╦ź¾ź░Ī╦ż“═Ų░ūż╦żĘż┐ĘQ¹|ż╬ĪŃČ\╦ĪĪõżŪżóżļ(Š▄żĘż»żŽĪó╗▓╣═½@╬┴8Īó6ż“╗▓Š╚)ĪŻ┐¶¾Hż»żóżļż¼Īó┐▐8ż╦ĄŁżĄżņżŲżżżļżżż»ż─ż½ż╬Č\╦Īż“į~├▒ż╦└Ō£½ż╣żļĪŻ
DropoutżŽāį│žØ{ż“öUĖµż╣ż┘ż»Īó│žØ{╗■ż╦├µ┤ų┴žż╬źµź╦ź├ź╚ż╬├═ż“▐k─Ļż╬│õ╣ńżŪ0ż╦żĘĪó±T╣ńż“’L═ŅżĄż╗żļŠ}╦ĪżŪżóżļĪŻAlexNetżŪ╗╚├ōżĄżņżŲż¬żĻĖĮ║▀żŌ╝ń╬«żŪżóżļĪŻżĮżņż╦×┤żĘżŲDrop ConnectżŽ±T╣ńż╬─_ż▀śOöüż“0ż╦ż╣żļŠ}╦ĪżŪżóżļĪŻż│ż╬2ż─ż╦żĶżĻĪó│žØ{╗■ż╦╬Ńż©żąĪó╦▄═ĶżŽż«ż┴ż«ż┴ż╦└▄¶öżĘżŲżżżļµ£±T╣ń┴žż╬±T╣ńż“Š»żĘšÅżķż╦żĘżŲź═ź├ź╚śOöüż╦Į└Ų└Łż“Ęeż┐ż╗żļż│ż╚ż¼żŪżŁżļĪŻ┐═┤ųżŪ╬Ńż©żļż╩żķżąĪóĪųŲ¼ż¼╔wżżż╚▒■├ōż¼ŠWż½ż╩żżĪūż╚żżż”└Ł│╩ż“─Šż╣żĶż”ż╩źŌź╬żŪżóżļĪŻ
┼ŠöĪ│žØ{żŽ│žØ{ż╬öĄ╦Īż“┤žŽóż╣żļ░█¹|ż╬ź┐ź╣ź»ż╦┼Š├ōż╣żļ▐k╚╠┼¬ż╩Č\╦Īż╬ż│ż╚ż“╗žżĘĪóżĮż╬├µżŪFine TuningżŽ╩╠ż╬ź┐ź╣ź»żŪ│žØ{║čż▀ż╬ź═ź├ź╚ź’Ī╝ź»ż“ų`┼¬ż╬ź┐ź╣ź»ż╬│žØ{ż╬ż┐żßż╦║Ų│žØ{ż╣żļż│ż╚ż“╗žż╣ĪŻ╬Ńż©żąĪóĪųŪŁż╬¹|╩╠ż╬▓ĶćĄŪ¦╝▒Īūż╬│žØ{║čż▀ż╬ź═ź├ź╚ż“Īų▓╚ż╬¹|╬Óż╬╝▒╩╠Īūż╦┼Š├ōż╣żļĪŻż│ż╬ż│ż╚ż╦żĶżĻ▓╚ż╬ČĄ╗šźĄź¾źūźļżŽŠ»ż╩ż»żŲ║čżÓĪŻ┐═┤ųżŪ╬Ńż©żļż╩żķżąĪó┤┴├ż¼żĘż├ż½żĻżŪżŁżŲżżżņżą▒■├ōżŽį~├▒ż╚żżż├ż┐źżźßĪ╝źĖżŪżóżļĪ╩ź▌źļź╚ź¼źļĖņż¼ÅBż╗żļ┐═żŽĪóź╣ź┌źżź¾ĖņżŌį~├▒ż╦Ø{įużŪżŁżļż│ż╚ż╦ŖZżżĪ╦ĪŻ
2015ŃQż╦╚»╔ĮĪ╩╗▓╣═½@╬┴31Ī╦żĄżņż┐┘ćæä▓ĮŠ}╦Īż╬żęż╚ż─żŪżóżļBatch Normalizationż“╗╚├ōż╣żļż│ż╚ż╦żĶżĻĪóĮjżŁż╩│žØ{ĘĖ┐¶Ī╩ĖĒ║╣ż“╚µ│ė┼¬Įj├└ż╦Ąš┼┴ś“żĄż╗żļĪ╦ż¼Īó╗╚├ō▓─ē”ż╚ż╩żĻ│žØ{ż╬╝²╠Jż“┴ßż»ż╣żļż│ż╚ż¼▓─ē”ż╦ż╩ż├ż┐ĪŻżĮż╬ż┐żßż╦Ų■╬üźĄź¾źūźļż╬ĮĖ╣ńĪ╩BatchĪ╦ż╦×┤ż╣żļ├µ┤ų┴žż╬Įą╬üż╬Č”╩č╬╠źĘźšź╚ż“Š«żĄż»ż╣żļ┘ćæä▓Įż╬▐kŠ}╦Īż“ŲDżĻŲ■żņżļ(╗▓╣═½@╬┴14)ĪŻź═ź├ź╚ź’Ī╝ź»ż╬▐kż─ż╬╣Į└«═ū┴ŪżŪżóżļĪŻ║ŪĖÕż╬Knowledge DistillationĪ╩ē¶╝▒├ĻĮąĪ╦żŽĮjæä╠ŽźŌźŪźļż“Š«æä╠ŽźŌźŪźļż╦Åø┤╣ż╣żļŠ}╦ĪżŪżóżļĪŻ
ĪŃ╣Į└«Īõż╚ĪŃ╣ŌÅ]▓ĮĪ”ź│ź¾źčź»ź╚▓ĮĪõ
╝Īż╦ĪŃ╣Į└«Īõ═ū┴ŪżŪżóżļøQ╣■ż▀┴žĪó─_ż▀/ź½Ī╝ź═źļĪóżĮżĘżŲźūĪ╝źĻź¾ź░┴ž┼∙ż╬╣®╔ūż╦żĶżļź═ź├ź╚ź’Ī╝ź»źŌźŪźļż╬┐╩▓Įż¼żóżļĪ╩╝Ī£I░╩æTŠ▄║┘ż╦└Ō£½ż╣żļĪ╦ĪŻżĄżķż╦╬“╗╦żŽ─╣żżż¼║“ŃQ¼ŹżĶżĻĪó╔Į╔±±śż╦ĮążŲżŁżŲżżżļĪŃ╣ŌÅ]▓ĮĪ”ź│ź¾źčź»ź╚▓ĮĪõż╬Ų░żŁż¼żóżļĪ╩2.8£I╗▓Š╚öĄĪ╦ĪŻżĮż╬ŲŌ═ŲżŽźŪĪ╝ź┐ż╚źčźķźßĪ╝ź┐ż╬─Ńźėź├ź╚▓ĮĪó░ĄĮ╠Ī󿥿ķż╦╬╠╗ę▓ĮČ\ĮčżŪżóżļĪ╩─╠Š’żŽ32źėź├ź╚╔ŌŲ░Š«┐¶┼└ż“╗╚├ōĪ╦ĪŻź╣źįĪ╝ź╔ż╚źčź’Ī╝Č”ż╦▓■║¤żĄżņĪóĖ·╬©żŽ2ŠĶµć┼┘ż╦╚µ╬ѿʟżź¾źčź»ź╚żŽ└õĮjżŪżóżļĪŻ╦▄═Ķ╚ŠŲ│öüż╬övŽ®╣Į└«ż╚äėżż└▄┼└ż“żŌż─ż╚ż│żĒżŪżóżļĪŻż╣ż╩ż’ż┴¾Hż»ż╬Šņ╣ńĪóĖ·▓╠ż“┘ćżĘż»░·żŁĮąż╣ż┐żßż╦żŽźŽĪ╝ź╔ź”ź¦źóżŪż╬╣®╔ūż¼ØŁ═ūż╚ż╩żļĪŻ
(3) ╩Ż╣ńĄĪē”▓ĮĪ╩źĘź╣źŲźÓ▓ĮĪ╦
Īų╩Ż╣ńĄĪē”▓ĮĪūżŽż▐żĄżĘż»źóźūźĻź▒Ī╝źĘźńź¾ż“└«ż╣ż┐żßż╬ĪųźĘź╣źŲźÓ▓ĮĪūż╬Ų░żŁżŪżóżļĪŻCNNż“├µ┐┤ż╦ĪóØiĖÕż╦╩Ż┐¶ż╬źŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚Ī╩╬Ńż©żąRegion Proposal Network╗▓╣═½@╬┴21ĪóRecurrent Neural NetworkĪóReinforcement LearningĪ”Ī”Ī”Ī¦┐▐8ż╬£ņÅR╗▓Š╚öĄĪ╦ż¼─Šš`Ī╩╩┬š`Ī╦└▄¶öĪóżŌżĘż»żŽŲDżĻ╣■ż▐żņżļĘ┴żŪ╩Ż┐¶ż╬ĄĪē”ż½żķż╩żļźĘź╣źŲźÓż¼╣Į└«żĄżņżļĪŻ─ŠŖZż╬źŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░żŪ║ŪżŌź█ź├ź╚ż╩ōļ░Ķż╬żęż╚ż─żŪżóżļĪŻ╬Ńż╚żĘżŲżŽĪó┘Zż╬ŖW┐┤ŖWµ£ż╬śOŲ░═Į▒Rż¼żóżļĪŻź½źßźķżŪĪó(1)┘ZØiöĄĪó╩Ō╠O╝■╩šż╬رöüż“┬¬ż©(Region Proposal NetworkĪ¦Ø±öüĘ┴ėXż¬żĶżėżĮż╬┐¶źšźņĪ╝źÓ╩¼ż╬░╠ÅøĪ”Å]┼┘)Īó(2)żĮż╬رöüż“╬Ńż©żą┐═ż╚╝▒╩╠(CNN)Īó(3)żĮż╬┐═ż╬Ų░żŁż½żķĖĮ╗■┼└żĶżĻ┐¶źšźņĪ╝źÓ└Ķż╬Ų░żŁż“ĪóĄ£Øiż╦│žØ{żĘż┐┐═ż╬Ų░║Ņż╬ĄŁ▓▒ż“┤ż╦╝ŖōQĪ╩RNNĪ¦╗▓╣═½@╬┴22Ī╦żĘżŲĪó┐═ż¼╩Ō╠Oż╦ĮążŲż»żļż╚└ĶŲ╔ż▀żĘź╔źķźżźąĪ╝ż╦Ę┘╣ż“╚»ż╣żļĪŻ(1)Ī┴(3)ż╬3ż─ż╬źŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»żŪźĘź╣źŲźÓż¼╣Į└«żĄżņżļĪŻż╩ż¬Īó(1)Īó(2)Īó(3)ż╬ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╦ż¬żżżŲĪó3Žó±TżŪ╝┬ä󿥿ņż┐╩¾╣żŽĖĮ╗■┼└żŪżŽĮążŲżżż╩żżż╚╗ūż’żņżļĪŻ║“ŃQ(1)+(2)ż¼╣ńöüżĄżņĪó▐kż─ż╬ź═ź├ź╚ź’Ī╝ź»ż╦ż╩żĻ╗@┼┘ż¼╬╔ż»ż½ż─ĮĶ═²╗■┤ųż¼░Ą┼▌┼¬ż╦Å]ż»Ī╩FasterĪ╦ż╩ż├żŲżżżļFaster R-CNN Ī╩Faster Region-basedĪĪCNNĪĪ╗▓╣═½@╬┴21Ī╦ż¼╚»╔ĮżĄżņżŲżżżļĪŻ┐▐8ż╬▓╝Ŗõż╦Īó┬Õ╔Į┼¬ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»Ī”źóźļź┤źĻź║źÓż╚ż╬┤žŽóĪ╩żżż»ż─ż½ż╬▓Ż╦└Ī╦ż“┐āżĘż┐ĪŻ║┘ż½żż└Ō£½żŽ│õ░”ż╣żļĪŻ
(4) Įø═Ķż╦Ė■ż▒żŲĪ╩Missing PartsĪ╦
║ŻĖÕØŁ═ūż╚żĄżņżļĪ╩ĖĮ║▀żŽ╝┬ĖĮżĘżŲżżż╩żżĪóżŌżĘż»żŽż▐ż└└Ķż╚╣═ż©żķżņżŲżżżļżŌż╬Ī¦┐▐├µż╬śĘżż╠░§ż╦öĄĖ■└ŁĪ╦ż╬żŽĪóśOżķ┤─ČŁż“źļĪ╝źļ▓ĮżĘżŲśOć·┼¬ż╦═Į▒Rż╣żļż┐żßż╬Č\ĮčĪóżĮż╬ż┐żßż╬ČĄ╗š╠ĄżĘ│žØ{ż╬Į╝╝┬Ī󿥿ķż╦żŽ▄ćŪ░ż“Ę┴└«żŪżŁżļśO─śĖ└ĖņĮĶ═²ż╬┐╩╩Ōż╚Ė└ż’żņżŲżżżļĪŻż│żņżķż╬Š»żĘżŪżŌ▓├ż’żļż╚ż½ż╩żĻē¶┼¬źņź┘źļż¼æųż¼ż├żŲż»żļż╚═²▓“żĘżŲżżżļĪŻĖĮ║▀żŽĪóæųĮęż╬Īų(2)żŪ┐═ż╚żĘżŲŪ¦╝▒Ī╩CNNĪ╦Īūż╚Į±żżżŲżżżļż¼╝┬żŽĪóĄ£Øiż╦│žØ{żĘż┐├µż╚żżż”Č╣żżšJ░ŽżŪرöüAżŌżĘż»żŽź»źķź╣Aż╚╝▒╩╠żĘżŲżżżļż└ż▒żŪżóżļĪŻ
╦▄ŠŽżŪŲDżĻ░Ęż”ż╬żŽĪó┐▐8ż╬Īų╣Ō└Łē”▓ĮĪūż╬├µż╬ĪŃ╣Į└«Īõż╚ĪŃ╣ŌÅ]▓ĮĪ”ź│ź¾źčź»ź╚▓ĮĪõż╬2ż─żŪżóżļĪŻ╝ĪövżŽCNNż╬┬Õ╔Į┼¬ź═ź├ź╚ź’Ī╝ź»źŌźŪźļżŪżóżļAlexNetż½żķGoogLeNetĪóResNetż╬└Ō£½ż“─╠żĘżŲĪóLSI╝┬äóż╬┤¬ĮĻż“├ĄżļĪŻ
ż╩ż¬Īó╝ĪŠŽĪ╩ŗī3ŠŽĪ╦░╩æTżŪżŽĮoē¶ż╬Š╩¾ż“┤ż╦Ū¦╝▒Ą┌żė╗■ÅUš`ĮĶ═²├ōź╦źÕĪ╝źĒź┴ź├źū/LSIż╬övŽ®źóĪ╝źŁźŲź»ź┴źŃż“└Ō£½ż╣żļĪŻż▐ż┐żĮżņżķż╬└Ō£½ż“─╠żĘżŲ▓─ē”ż╩šJ░ŽżŪĘQźóźļź┤źĻź║źÓĪ”źŌźŪźļż╬źóźūźĻź▒Ī╝źĘźńź¾żžż╬╝┬äóźóĪ╝źŁźŲź»ź┴źŃżŌ▄ć└Ōż╣żļĪŻ
╗▓╣═½@╬┴
1Ī┴9ż▐żŪżŽĪóĪųź╦źÕĪ╝źĒź┴ź├źū▄ć└ŌĪĪĪ┴żżżĶżżżĶ╚ŠŲ│öüż╬Įą╚ų(1-1)Īūż“╗▓Š╚
10Ī┴13ż▐żŪżŽĪóĪųź╦źÕĪ╝źĒź┴ź├źū▄ć└ŌĪĪĪ┴żżżĶżżżĶ╚ŠŲ│öüż╬Įą╚ų(1-2)Īūż“╗▓Š╚
- ŃK├½ šQŪĘ, Īų▓ĶćĄŪ¦╝▒ż╬ż┐żßż╬┐╝┴ž│žØ{ż╬Ė”ē|Ų░Ė■ ĪĪĪ▌øQż▀╣■ż▀ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╚żĮż╬ŠW├ō╦Īż╬╚»·tĪ▌Īū, ┐═╣®ē¶ē”│ž▓±╗’ 31┤¼2ęÄ(2016ŃQ3ĘŅ), 169-179╩Ū.
- WikiPedia, Ī╚īÖ└Ł▓Į┤ž┐¶Ī╔
- Y. LeCun, Y. Bengio, G. Hinton Ī╚Review: Deep LearningĪ╔, Nature 521, 436-444 (28 May 2015), ┐╝┴ž│žØ{ż╬3ČĄ┴─ż╦żĶżļReviewżŪżóżļĪŻ
- ╦_Ę┴ ┼»╠ķ, ĪųźĒź▄źŲźŻź»ź╣ż╚┐╝┴ž│žØ{Īū, ┐═╣®ē¶ē”│ž▓±╗’ 31┤¼2ęÄ(2016ŃQ3ĘŅ), 210-215╩Ū.
- ŃK├½ šQŪĘ, Īų┐╝┴ž│žØ{Īū, 111-130╩Ū, ŗī7ŠŽĪų║ŲĄóĘ┐ź╦źÕĪ╝źķźļź═ź├ź╚Īū Ī╩ĄĪ│Ż│žØ{źūźĒźšź¦ź├źĘźńź╩źļźĘźĻĪ╝ź║Ī╦Īó╣ųÕi╝ęĪó2015ŃQ4ĘŅ8Ų³ (║ŲĘŪ).
- ŠŠĖĄ ▒├▐k, Īų╩¼Üg┐╝┴žäė▓Į│žØ{żŪźĒź▄ź├ź╚öUĖµĪū, Preferred Research (Preferred Infrastructure Inc,), 2015ŃQ6ĘŅ10Ų³
- Īųź╝źĒż½żķDeepż▐żŪ│žżųäė▓Į│žØ{Īū, Qiita, 2016ŃQ6ĘŅ7Ų³
- Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, Ī╚Faster R-CNN: Towards Real-Time Object Detection with Region Proposal NetworksĪ╔, 2016ŃQ1ĘŅ6Ų³Ī╩ver.3Ī╦.
- Kyuho J. Lee+, Ī╚A 502GOPS and 0.984mW Dual-Mode ADAS SoC with RNN-FIS Engine for Intention Prediction in Automotive Black-Box SystemĪ╔, 2016 IEEE International Solid-State Circuits Conference, Session 14.2, p256-259, 2016ŃQ2ĘŅ.
- Alex Krizhevsky, Geoffrey E. Hinton, University of Toronto, Ī╚ImageNet Classification with Deep Convolutional Neural NetworksĪ╔, (Advances in Neural Information Processing Systems 25 (NIPS 2012)), 20121210.

