ź╦źÕĪ╝źĒź┴ź├źū▄ć?y©ón)ŌĪĪĪ┴żżżĶżżżĶ╚ŠŲ│öüż╬Įą╚?2-3)
ŗī2ŠŽĪ¦źŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬ź╦źÕĪ╝źĒź┴ź├źūżžż╬╝┬äóĪ┴żĮż╬┤¬ĮĻżŽ!!
ż│ż╬ŗī2ŠŽż╬║ŪĖÕż╦┼÷ż┐żļ2-3żŪżŽĪóź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż“ź┴ź├źūż╦╝┬äóż╣żļŠņ╣ńż╬źßźŌźĻż╬æä╠Žż¼ż╔ż╬µć┼┘ż╦ż╩żļż½Ī󿥿ķż╦źßźŌźĻæä╠Žż“žō(f©┤)żķż╣ż┐żßż╬╣®╔ūż╩ż╔ż“Šę▓ż╣żļĪŻĪ╩ź╗ź▀ź│ź¾ź▌Ī╝ź┐źļįćĮĖ╝╝Ī╦
├°ŪvĪ¦ĪĪĖĄ╚ŠŲ│öü═²╣®│žĖ”ē|ź╗ź¾ź┐Ī╝Ī╩STARCĪ╦/ĖĄ┼ņėøĪĪ╝å└źĪĪĘ╝
2.7ĪĪĪĪźŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ĪĪĪ┴źßźŌźĻ╝┬äóż╦┤žż╣żļ╣═╗ĪĪ¦ĪĪ3ż─ż╬ź┐źżźūĪ┴
╦▄£IżŪżŽĪóCNN░╩│░żŌ┤▐żßź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬╣Į└«ż╬Ę┐ż¼3ż─ż╦╩¼ż▒żķżņżļż│ż╚ż“└Ō£½żĘĪóĘQĪ╣ż╬Ę┐ż╬źčźķźßĪ╝ź┐┐¶Īóż╣ż╩ż’ż┴źßźŌźĻż╬æä╠Žż¼Š“°Pż╦żĶżĻż╔ż╬żĶż”ż╦╩čż’żļż╬ż½ż╦ŠÆų`ż╣żļĪŻżĮż╬═²▓“ż“─╠żĘżŲĪóLSIżžż╬źßźŌźĻż╬╝┬äóż╬┤¬ĮĻż“─ŽżÓĪŻżĮż╬├µżŪĪóų`ŖWż╬┴T╠ŻżŌ┤▐żßżŲź¬ź¾ź┴ź├źūĪ╩║«║▄Ī╦ż“▐kż─ż╬Ą─ébż╬ź▌źżź¾ź╚ż╚ż╣żļĪŻż╩ż¬Ī󟬟¾ź┴ź├źūźßźŌźĻĪ╩SRAMĪ╦ż╚│░¤²ż▒źßźŌźĻĪ╩DRAMĪ╦żŪżŽźčź’Ī╝ĪóÅ]┼┘Č”ż╦2ĘÕµć┼┘░█ż╩żļĪ╩╗▓╣═½@╬┴13Ī╦ĪŻ
(1) 3ż─ż╬ź┐źżźūż╦╩¼ż▒żķżņżļ
┐▐13ż╦Įoē¶ż╬ĘQ¹|ź═ź├ź╚ź’Ī╝ź»żŌżĘż»żŽźŌźŪźļż╬ĮĶ═²×┤ō■(j©┤)Ų■╬ü┐¶Ī╩▓Ķ楿¬żĶżė├▒ĮŃźŪĪ╝ź┐Ī╦ż╚ØŁ═ūźčźķźßĪ╝ź┐┐¶ż╚ż╬┤žĘĖż“┐āżĘż┐ĪŻCNN░╩│░ż╬źóźļź┤źĻź║źÓĪ󿥿ķż╦żŽźóźūźĻź▒Ī╝źĘźńź¾żžż╬┼¼▒■ż“ż╦żķż¾ż└╝┬ź═ź├ź╚ź’Ī╝ź»ż╬├═żŌŲ■żņż┐ĪŻż▐ż┐źčźķźßĪ╝ź┐┼÷ż┐żĻż╬źėź├ź╚┐¶ż“16źėź├ź╚ż╚żĘĪóźąźżź╚┤╣ōQżĘż┐╬╠ż“?q©▒)Ü╝┤ż╦└^żĘż┐ĪŻØŁ═ūż╩źßźŌźĻ═Ų╬╠Ī╩Byte=8bitĪ╦żŪżóżļĪŻĘQźŪĪ╝ź┐ź▌źżź¾ź╚ż╦ź═ź├ź╚ć@żŌżĘż»żŽźŌźŪźļć@ż“¤²ĄŁżĘż┐Ī╩ØŁ═ūż╩Šņ╣ńż╦żŽ╗▓╣═╩ĖĖźż“╗▓Š╚Ī╦ĪŻżĄżķż╦╝ńż╦CNNż╦×┤żĘżŲżŽź»źķź╣┐¶ż“▓├ż©ż┐Ī╩╬Ńż©żąC10(Classż¼10Ī╦)ĪŻAlexNetĪóVGGNet┼∙ż╬źŌźŪźļż╬ź»źķź╣┐¶żŽ1000żŪżóżļĪŻ
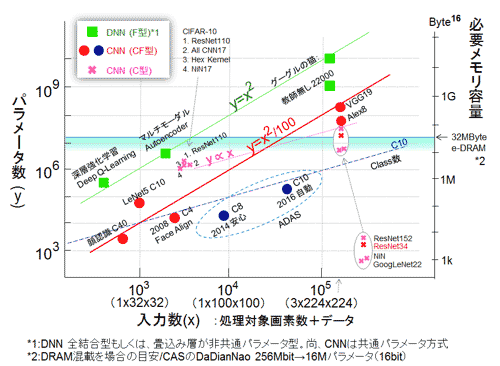
┐▐13ĪĪŲ■╬ü┐¶ż╚ØŁ═ūźßźŌźĻ═Ų╬╠ż╬┤žĘĖ
Googleż╬ŪŁĪ╩╗▓╣═½@╬┴33Ī¦ČĄ╗šż╩żĘ│žØ{Ī╦Īó2016śOŲ░Ī╩śOŲ░▒┐┼Š ╗▓╣═½@╬┴34Ī╦ĪóDeep Q-LearningĪ╩
╗▓╣═½@╬┴35Ī╦ĪóAutoencoderĪ╩ź▐źļź┴źŌĪ╝ź└źļĪ¦╗▓╣═½@╬┴36Ī╦ĪóDaDianNao(Super Leaning Machine ChipĪ¦╗▓╣═½@╬┴37)ĪŻĪĪÅR┴T┼└Ī¦CĘ┐żŽConv┴žż¼źŌźĖźÕĪ╝źļ▓ĮżĄżņżŲżżżļż│ż╚ż¼ØŖ─¦ĪŻ
ź═ź├ź╚ź’Ī╝ź»ż╬╣Į└«ż╬Ę┐ż╚żĘżŲĪóØi£Iż▐żŪż╦Šę▓żĘż┐CFĘ┐ĪóCĘ┐ż╦┐Ęż┐ż╦FĘ┐ż“▓├ż©ż┐ĪŻFĘ┐żŽ±T╣ńż¼µ£±T╣ńżŌżĘż»żŽĪóøQ╣■ż▀┴žżŪżŌØÖČ”─╠źčźķźßĪ╝ź┐Ę┐Ī╩─_ż▀Č”Ń~weight sharingżĄżņżŲżżż╩żżĪ╦ż╬ź═ź├ź╚ź’Ī╝ź»ż“╗žż╣ĪŻČĄ╗šż╩żĘ│žØ{żŪ├°ć@ż╩ź░Ī╝ź░źļż╬ŪŁż╬ź═ź├ź╚ż¼│║┼÷ż╣żļĪŻż│ż╬Ę┴ż╬ź═ź├ź╚ź’Ī╝ź»ż“DNN (Deep Neural Net) ż╚CNNż╚ČĶ╩╠ż╣żļż┐żßż╦╗╚├ōż╣żļŠņ╣ńż¼żóżĻ┐▐żŪżŌ╗╚├ōżĘż┐ĪŻ
▓Ż╝┤żŽź╦źÕĪ╝źķźļź═ź├ź╚ż¼1┼┘ż╦ź┐ź╣ź»ĮĶ═²ż“ż╣żļŲ■╬ü┐¶żŪżóżļĪŻż│ż╬┐▐ż╬šJ(r©©n)░ŽżŪCNNż╬Šņ╣ńż╦żŽ▓Ķ┴ŪĪóDNN (FĘ┐) ż╬Šņ╣ńż╦żŽĪó▓Ķ┴Ūż╦▓├ż©żŲ▓╗╠mĪóźŪĪ╝ź┐Ī╩│č┼┘Īóź╣źįĪ╝ź╔┼∙Ī╦żŌ┤▐ż▐żņżļĪŻ╗╚├ōżĘż┐Deep Q-Learning Ī╩┐╝┴žäė▓Į│žØ{ż╬żęż╚ż─Ī╦ż╬Šņ╣ńż╦żŽźŪĪ╝ź┐ż╬ż▀żŪżóżļĪŻ─╠Š’éb╩Ė┼∙ż╬╚»╔ĮżŪżŽźčźķźßĪ╝ź┐żŽżóż½żķżĄż▐ż╦ĄŁ║▄żĘż╩żżż╬żŪĪó╚Š╩¼µć┼┘żŽ├°Ūvż¼╗ŅōQżĘż┐├═żŪżóżļĪŻ╗▓╣═½@╬┴14żŌ╗▓╣═ż╦żĘż┐ĪŻ
(2) ĘQĪ╣ż╬Ę┐ż╬ØŖ─¦
ź═ź├ź╚ż╬╣Į└«ż╬Ę┐ż┤ż╚ż╦ŲŌ═Ųż“└Ō£½ż╣żļ
2-1)ĪĪFĘ┐Ī╩µ£±T╣ń╝ńöüĘ┐Ī╦Ī┴ČĄ╗šż╩żĘ│žØ{DNNĪóź▐źļź┴źŌĪ╝ź└źļAutoencoderĪóäė▓Į│žØ{D QLĪ╦
ĖĮ╗■┼└żŪżŽĪó▓Ķ楿╬ČĄ╗šż╩żĘ│žØ{Īó╩Ż┐¶¹|ż╬źŪĪ╝ź┐ż“Ų▒╗■ĮĶ═²ż╣żļź▐źļź┴źŌĪ╝ź└źļĪó║ŲĄóĘ┐RNNĪ󿥿ķż╦żŽäė▓Į│žØ{ż¼µ£±T╣ńĪ╩Fully ConnectedĪ╦ż¼╝ńöüż╬FĘ┐ż╚ż╩żļżĶż”ż└ĪŻµ£±T╣ń┴žż¼╝ńöüż╩ż╬żŪĪóŲ■╬ü╝ĪĖĄ┐¶ż╦×┤żĘżŲĪó2ŠĶżŪźčźķźßĪ╝ź┐ż¼ØŁ═ūż╚ż╩żļĪŻČĄ╗šż╩żĘżŪż╬▓ĶćĄŪ¦╝▒ż└ż╚źčźķźßĪ╝ź┐┐¶ż¼Šå╗\ż╣żļż╬żŪ×┤║÷ż¼ØŁ═ūżŪżóżļĪŻż│żņż╦×┤żĘżŲĪó║Żöv╗╚├ōżĘż┐Deep Q-learningĪ╩┐╝┴žäė▓Į│žØ{Ī╦żŪżŽĪóżĮżŌżĮżŌ▓Ķ楟ŪĪ╝ź┐ż“░Ęż├żŲżżż╩żżĪŻÅ]┼┘Īó░╠Åøż╚żżż├ż┐źŪĪ╝ź┐żŪżóżĻ╬╠┼¬ż╦żŽŠ»ż╩żżĪŻRNNż╩żĻäė▓Į│žØ{żŪ▓Ķ楊╩¾ż“░Ęż”║▌żŽĪóē¶żļšJ(r©©n)░ŽżŪżŽĄ£Øiż╦CNNżŪźŪĪ╝ź┐ż“├Ļō■(j©┤)▓ĮĪ╩╬Ńż©żą░╠Åøż╚ż½Å]┼┘ż╦╩č┤╣Ī╦żĘżŲĪóŲ■╬ü╝ĪĖĄ┐¶ż“═Ņż╚ż╣ż╬ż¼─╠Š’żŪżóżļĪŻ
2-2)CFĘ┐Ī╩CNN øQ╣■ż▀┴žĪ▄µ£±T╣ń┴žČ”┘TĘ┐Ī╦Ī¦ČĄ╗šżóżĻ▓ĶćĄŪ¦╝▒ż¼┬Õ╔Į
Ų■╬ü┐¶ż╬2ŠĶż╦╚µ╬ѿʿŲźčźķźßĪ╝ź┐┐¶żŽ╗\▓├żĘśĘżż╝┬└■æųż╦║▄żļĪŻ224x224ż╚▓“ćĄ┼┘ż╬Įj(lu©░)żŁżß▓Ķ楿╬Šņ╣ńż╚32x32ż╚Š«żĄżż▓Ķ楿╬Šņ╣ńż¼╝ńż╦źūźĒź├ź╚żĄżņżŲżżżļĪŻź»źķź╣┐¶żŽżĮżņżŠżņ1000ż╚10ż╚Č╦├╝ż╦░Ńż”ĪŻśĘżż╝┬└■ż╦ŠĶżļż╚ż╣żļż╩żķżąĪóź═ź├ź╚ź’Ī╝ź»ż¼║Ū┼¼▓ĮżĄżņżļż╚ĪųŲ■╬ü┐¶(X)ż╚ź»źķź╣┐¶Ī╩CĪ╦ż╬╚µżŽ▐k─Ļ├═ż╦═Ņż┴ŠÆż»Īūż│ż╚ż“┴T╠Żż╣żļĪŻX/C=100ż╬┴T╠Żż╣żļż╚ż│żĒżŽĪų1ź»źķź╣┼÷ż┐żĻ10x10ż╬▓Ķ┴Ūż¼ØŁ═ūĪūż╚ż╬▓“łį(ji©Īn)żŌżŪżŁżļĪŻż│ż╬ĖČ═²ż╬ē|£½żŽ║ŻĖÕż╬▓▌¼öżŪżóżļĪŻ┐▐ż╬×EżżĪ¹żŪ┐āżĘż┐Class10ż╬ź═ź├ź╚ź’Ī╝ź»żŽśĘżż╝┬└■żĶżĻżŌ▓╝Ŗõż╦źūźĒź├ź╚żĄżņżŲżżżļĪŻź»źķź╣┐¶ż╦×┤żĘżŲāįŠĻż╬▓“ćĄ┼┘ż“Ęeż├ż┐Ų■╬ü▓Ķ楿“╗╚├ōżĘżŲżżżļż╚╣═ż©żķżņżļĪŻż│ż╬±T▓╠ż╬żęż╚ż─żŽNVIDIAż╬śOŲ░▒┐┼Š(End to end learning for Self-Driving CarsĪ¦╗▓╣═½@╬┴34)ż╦╗╚├ōżĄżņżŲżżżļź═ź├ź╚ź’Ī╝ź»żŪżóżļĪŻ▓┐ż½┬Šż╬┴T┐▐ż¼żóżļż╬ż½żŌżĘżņż╩żżĪŻż╩ż¬ĪóźĘź╣źŲźÓż╬ŲŌ═ŲżŽŗī3ŠŽ░╩æTżŪ└Ō£½ż╣żļĪŻ
2-3)CĘ┐Ī╩CNN øQ╣■ż▀┴ž╝ńöüĪ╦Ī¦ źŌźĖźÕĪ╝źļ▓Į
Class1000ż╬GoogLeNet22ż╚ResNet34/152ż“┐▐13ż╦▓├ż©żŲżóżļĪŻ▓“ćĄ┼┘ż¼─Ńżżź▒Ī╝ź╣żŽĪóØi£IżŪŠę▓żĘż┐MSRAż╬ResNet110 (110┴ž) ż╬CIFAR-10 (3x32x32) żŪż╬ź┘ź¾ź┴ź▐Ī╝ź»ż╬±T▓╠ż“źūźĒź├ź╚żĘż┐ĪŻżĄżķż╦╗▓╣═½@╬┴14ż╦║▄ż├żŲżżż┐░╩▓╝ż╬3ż─ż╬źŌźŪźļż“┐▐13ż╦Ų■żņżŲżóżļĪŻżĮżņżķżŽAll-CNN(╗▓╣═½@╬┴54)ĪóHex Kernel(╗▓╣═½@╬┴55)ĪóżĮżĘżŲNiN (Network in Network) ż╬CIFAR╚ŪżŪżóżļĪŻźčźķźßĪ╝ź┐┐¶żŽ100Ī┴170╦³Ė─ż╚3x32x32ż╬▓“ćĄ┼┘ż╦żĘżŲżŽż½ż╩żĻ¾HżżĪŻäė░·ż╦±Tżųż╚Ī╩┼Ē┐¦ż╬Ū÷żż└■Ī╦ż╚’łżŁż¼1żŪźčźķźßĪ╝ź┐ż╚▓“ćĄ┼┘żŽ╚µ╬Ń┤žĘĖż╦żóżļĪŻż½ż╩żĻ═╦Įż└ż¼ĪóøQ╣■ż▀┴žż╬Šņ╣ńż╦żŽĪóŲ■╬üż╬ÅRų`▓Ķ┴ŪĪ╩Ę▓Ī╦ż╬ŖZšfżŪż╬ØŖ─¦├ĻĮąż╬└čż▀─_ż═ż╩ż╬żŪĪóżóż╩ż¼ż┴Ų■╬üż╬╝ĪĖĄ┐¶ż╦╚µ╬Ńż╣żļż╚ż▀żļż╬żŌ┤ų░Ńż├żŲżŽżżż╩żżĪŻż│ż╬┘ćżĘżż┤žĘĖż╚ĖČ═²ż╬ē|£½żŌ║ŻĖÕż╬▓▌¼öżŪżóżļĪŻ
ż▐ż╚żßżļż╚źčźķźßĪ╝ź┐┐¶Ī╩yĪ╦żŽŲ■╬ü┐¶Ī╩xĪ╦ż╦×┤żĘżŲĪóżĮżņżŠżņż╬Ę┐╝░żŪ
FĘ┐Ī╩µ£±T╣ń┴žĘ┐Ī╦ Ī”Ī”Ī” y=x2
CFĘ┐Ī╩Č”┘TĘ┐Ī╦ Ī”Ī”Ī” y=x2/100
CĘ┐Ī╩øQ╣■ż▀┴žĘ┐Ī╦ Ī”Ī”Ī” yóńxĪĪĪĪĪ╩ż┐ż└żĘĪóźŌźĖźÕĪ╝źļ▓ĮĪ╦
(3) źßźŌźĻż╬╝┬äóż╦┤žż╣żļ╣═╗Ī
┐▐13ż╬īÜ╝┤ż╦├µ╣±▓╩│ž▒ĪCASż¼2014ŃQ¼Źż╦╚»╔ĮżĘż┐DaDianNaoż╬║«║▄DRAM┼ļ║▄╬╠ż“┐āżĘż┐ĪŻ256Mźėź├ź╚Ī╩8.2mm│čĪ╦Īó32Mźąźżź╚żŪżóżļĪŻ2014ŃQ8ĘŅ╚»╔Įż╬IBMż╬TrueNorthżŌŲ▒żĖż»SRAMż╬║«║▄żŪ═Ų╬╠żŽ256Mźėź├ź╚(25x17mm2)żŪżóżļĪŻČ”ż╦28nmżŪż╬║«║▄żŪżóżļż│ż╚ż½żķ┼÷ĀCż╬ų`ŖWż╦ż╩żļĪŻ
3-1) FĘ┐Ī╩µ£±T╣ńĘ┐Ī╦
µ£±T╣ń╝ńöüżŪżóżļż│ż╚ż½żķźßźŌźĻżžż╬źóź»ź╗ź╣ż¼╔č╚╦ż╦╣įż’żņżļĪŻźßźŌźĻż╬║«║▄żŽČ╦żßżŲĖ·▓╠┼¬żŪżóżļĪŻżĘż½żĘ256Mźėź├ź╚/32Mźąźżź╚ż“║«║▄ż╬ų`ŖWż╚ż╣żļż╚Īó▓ĶćĄ▒■├ōżŪżŽæä╠Ž┼¬ż╦ż½ż╩żĻż½ż▒▀`żņżŲżżżļĪŻ▓Ķ楿“░Ęż”║▌ż╦żŽ│ū┐Ę┼¬ż╩Č\Įčż¼┬į╦ŠżĄżņżļĪŻ
3-2) CFĘ┐Ī╩Č”┘TĘ┐Ī╦
Ų■╬üż╬▓Ķ┴Ū┐¶żŽ═Š═Ąż“Ęeż┐ż╗żļż╚100x100Ī┴150x150▓Ķ┴Ūµć┼┘ż¼źßźŌźĻ║«║▄ż╬Ė┬─cż╚╣═ż©żķżņżļĪŻČ”┘TĘ┐ż╚żŽĖ└ż©Īóµ£±T╣ńŗż¼└Łē”ż╬90%ØiĖÕż“žéżßżļż│ż╚ż½żķ║«║▄żĘż┐║▌ż╬Š├õJ┼┼╬üĪóź╣źįĪ╝ź╔▓■║¤ż╬Ė·▓╠żŽĮj(lu©░)żŁżżĪŻźßźŌźĻźóź»ź╗ź╣żžż╬Ū█╬Ėż¼─_═ūżŪżóżļĪŻ
3-3) CĘ┐(øQ╣■ż▀╝ńöüĘ┐)
Ų■╬üż╬▓Ķ┴Ū┐¶ż¼3x224x224Ī╩1000ź»źķź╣Ī╦╩┬ż▀ż╬ź═ź├ź╚ź’Ī╝ź»żŌźßźŌźĻ║«║▄ż¼╝o(j©¼)µćŲŌż╦Ų■ż├żŲżŁż┐ĪŻŠ░ĪóøQ╣■ż▀┴žżŪżŽŲ▒żĖźčźķźßĪ╝ź┐ż“Ę½żĻ╩ųżĘ╗╚├ōż╣żļĄ£ż½żķĪ╩╩┐Čč200övµć┼┘Īó2.6£IżŪ└Ō£½Ī╦źßźŌźĻżžż╬źóź»ź╗ź╣żŽ╣®╔ūż╦żĶżĻĮj(lu©░)╔²ż╦Ę┌žō(f©┤)żĄżņżļĪŻź©ź├źĖĪ”źŌźąźżźļÅUżžż╬źŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╬┼¼├ōż¼ż½ż╩żĻĖĮ╝┬┼¬ż╦ż╩ż├żŲ═Ķż┐ĪŻżĮż╬æųżŪĪóż╔ż╬µć┼┘─ŃŠ├õJ┼┼╬ü▓Įż“╝{Ąßż╣żļż½ż¼ź▌źżź¾ź╚ż╚ż╩żļĪŻ
(4) ResNet34ż“LSIż╦╝┬äóżĘżŲż▀żļ
Š»żĘ┐▐13ż½żķ▀`żņżŲĪóLSIż╦╝┬äóżĘż┐║▌ż╦ż╔ż╬żĶż”ż╦ż╩żļż½į~├▒ż╦╗ŅōQżĘżŲż▀żļĪ╩╔Į3ż╬16źėź├ź╚ż╬ź▒Ī╝ź╣Ī╦ĪŻźŌźŪźļżŽ║“ŃQ¼Źż╬╚»╔Įż½żķ║ŪŖZ(2016ŃQ7ĘŅ╗■┼└)ż▐żŪż╬╚ŠŃQ┤ųżŪż½ż╩żĻż╬╝{ĖĪŠ┌Ī”·t│½ĖĪŠ┌╝┬└ė╩¾╣Ī╩رöüĖĪē¶ĪóRecurrent NNż╚ż╬╩Ż╣ń/┬ŠĄĪ┤ž╩¾╣┤▐żßĪ¦╗▓╣═½@╬┴29Ī╦ż╬żóżļResNetĪó┴ž┐¶ż╚żĘżŲżŽŠ}║óż╩34┴žż“┬ō(li©ón)┘IżĘż┐ĪŻ╔Į1żĶżĻØŁ═ūż╩źßźŌźĻż╬æä╠Žż╚żĘżŲżŽĪó352Mźėź├ź╚Ī╩źčźķźßĪ╝ź┐┼÷ż┐żĻ16źėź├ź╚Ī╦ż¼ØŁ═ūżŪżóżļĪŻĖĮ╗■┼└żŪżŽØiĮęż╬TrueNorth/DaDianNaoź»źķź╣ż╬256Mźėź├ź╚ż¼║«║▄ż╬╝┬└ėż╚ż╣żļż╚żĮżņżĶżĻĮj(lu©░)żŁż»Īó║ŻĖÕż╬╚∙║┘▓Įż“Øi─¾ż╚żĘżŲżŌ═Š═Ąż¼żóżļż╚żŽĖ└ż©ż╩żżĪŻżĘż½żĘĪóź©ź├źĖ▒■├ōż“╣═ż©żļż╚źßźŌźĻ╝┬äóż╦ż½ż╩żĻż╬śOĮy(t©»ng)┼┘ż¼Įąż┐ż╚╣═ż©żļż│ż╚ż¼żŪżŁżļĪŻ└Łē”ż╦┤žżĘżŲżŽĪóżóż»ż▐żŪ├▒ĮŃ╗ŅōQż└ż¼Īó36.4▓»övż╬MAC▒ķōQż¼ØŁ═ūżŪżóżļż│ż╚ż½żķ3.64msecżŪ1▓ĶćĄĪ╩źšźņĪ╝źÓĪ╦ż╬Ū¦╝▒ĮĶ═²ż¼▓─ē”ż╩źņź┘źļżŪżóżļ(16źėź├ź╚▓ĮżŪÅ]ż»ż╩żļż¼╣═╬Ėż╗ż║)ĪŻ▓Šż╦10Ū▄ęÆż»żŲżŌ36msecżŪ30fps(frame per sec)ż╦żŽ×┤▒■żŪżŁżļźņź┘źļżŪżóżļĪŻż┴ż╩ż▀ż╦Øi─¾ż╚żĘżŲ1TFLOPS/s(MAC┤╣ōQ)ż“╗╚├ōżĘż┐ż¼Īóż½ż╩żĻźņź┘źļż¼╣ŌżżĪŻ
ResNet┼∙CĘ┐ż╬CNNż╬┼ąŠņż╦żĶżĻź©ź├źĖÅUżŽżŌż╚żĶżĻż½ż╩żĻźŌźąźżźļżžż╬·t│½ż¼ĖĮ╝┬╠Żż“┬ėżėżŲżŁż┐ĪŻż╩ż¬ĪóźĘź╣źŲźÓ▒■├ōż╬Šņ╣ńż╦żŽŲ■╬üż╬▓“ćĄ┼┘Īó╩┬š`ź┐ź╣ź»┐¶ĪóźčźķźßĪ╝ź┐ż╬źėź├ź╚┐¶Īó┴ž┐¶Ī╩34┴žżŪżżżżż╬ż½Ī®Ī╦Ī󟻟ķź╣┐¶Īóź©źķĪ╝ż╬ß×═ŲšJ(r©©n)░ŽĪóŽó¶öżŪĮĶ═²ż╣żļ╩Ż╣ńĄĪē”┼∙ĪóźĘź╣źŲźÓ╣Į└«ż╬Š╩¾ż“▓├╠Żż╣żļØŁ═ūż¼żóżļĪŻŗī3ŠŽ░╩æTżŪÉ║öü┼¬ż╩╬Ńż“├ōżżżŲ▓─ē”ż╩Ė┬żĻźĘź╣źŲźÓźżźßĪ╝źĖż╦┌ģżļ═Į─ĻżŪżóżļĪŻ
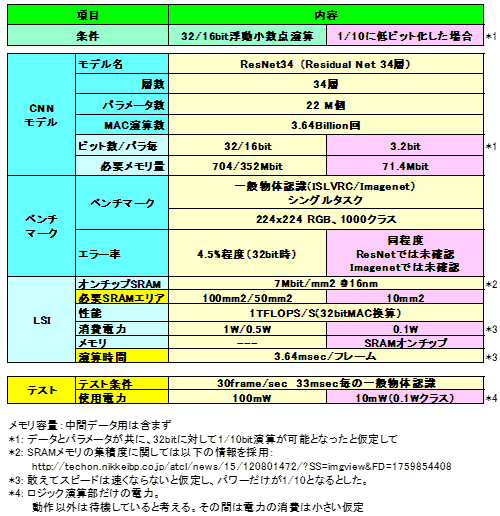
╔Į3 źßźŌźĻ═Ų╬╠ż╚▒ķōQ╗■┤ųż╬├▒ĮŃ╗ŅōQ
2.8ĪĪĪĪźŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ĪĪĪ┴źßźŌźĻ╬╠Ś„žō(f©┤) źĄźų0.1WżŌĪ¬ źŌźąźżźļż╦źĒź├ź»ź¬ź¾Ī┴
(1) źčźķźßĪ╝ź┐Ī”źŪĪ╝ź┐─Ńźėź├ź╚▓Į/░ĄĮ╠ż╬Ų░żŁż╚żĮż╬Ė·▓╠
╔Į4ż╦║ŪŖZż╬źßźŌźĻ╬╠║’žō(f©┤)ż╦─Š±Tż╣żļźčźķźßĪ╝ź┐Ī”źŪĪ╝ź┐─Ńźėź├ź╚▓Į/░ĄĮ╠ż╬Ų░Ė■ż“▐k═„ż╚żĘżŲ┐āż╣ĪŻźčźķźßĪ╝ź┐Ī”źŪĪ╝ź┐żŽ─╠Š’żŽĪó32źėź├ź╚ż╬╔ŌŲ░Š«┐¶┼└▒ķōQż“ź┘Ī╝ź╣ż╦Ė”ē|│½╚»ĪóĮj(lu©░)Š}IT┤ļČ╚ż╬źŪĪ╝ź┐ź╗ź¾ź┐Ī╝żŪż╬╝┬├ōż¼┐╩żßżķżņżŲżżżļĪŻżĘż½żĘĪóż█ż╚ż¾ż╔ż╬ż│ż╬╩¼╠Ņż╦┤žż’żļöĄ(sh©┤)żŽ32źėź├ź╚żŌżżżķż╩żżż╬żŪżŽż╚╗ūż”Ī╩ØŖż╦╝┬╣į╗■żŽĪ╦ĪŻ32źėź├ź╚ż╚╣Ō╗@┼┘▓Įż╣żļż│ż╚ż╚ĪóØŖ─¦├ĻĮąż╬║▌ż╦×┤ō■(j©┤)ż“├Ļō■(j©┤)▓ĮĪ╩╔į═ūż╩رż“żĮż«═Ņż╚żĘżŲĪ╦ż╣żļż│ż╚ż¼Ąš╣įżĘżŲżżżļż½żķżŪżóżļĪŻ
┐ČżĻ╩ųżļż╚2012ŃQ░╩ØiżĶżĻ╔w─Ļ┼D┐¶Īó8źėź├ź╚▓Įż╬ĖĪŲż┼∙ż¼ż╩żĄżņżŲżżż┐Ī╩╗▓╣═½@╬┴38Ī╦ĪŻ2013Ī┴2014ŃQż╦żŽźšźŻźļź┐ż“╣įż╚š`ż╦╩¼│õżĘżŲ╝┬╣į╗■ż╬╝ŖōQ╬╠ż“2Ī┴3Ū▄µć┼┘║’žō(f©┤)ż╣żļSeparable Filter (╗▓╣═½@╬┴39Īóź╦źÕĪ╝źĶĪ╝ź»Įj(lu©░)│žż╚Facebook AI Researchż╬╩¾╣)ż╩ż╔ż╬ź═ź├ź╚ż╬░ĄĮ╠╦Īż╬╩¾╣ż¼żóż├ż┐ĪŻżĄżķż╦2014ŃQż╦żŌź│źĒź¾źėźóĮj(lu©░)│žż╬Soudryżķż╬─_ż▀ż“Ī▐1ż╚ż╣żļŠ}╦Ī(Expectation BackpropagationĪ¦╗▓╣═½@╬┴40) ┼∙ż╬╩¾╣żŌżóż├ż┐ĪŻżĘż½żĘĪó╔Į4ż╦┐āż╣żĶż”ż╦║“ŃQż╬11ĘŅĪ╩║“ŃQ12ĘŅż╬NIPS)ż╬Binary Connectż╬╚»╔Į (╗▓╣═½@╬┴41) ż╬║óżĶżĻ─ŠŖZż╬▓▌¼öż╚żĘżŲżĶżĻÅRų`żĄżņĮążĘĪóż▐ż┐LSI╝┬äóż╦ŖZżżĘ┴żŪż╬╚»╔ĮżŌ╗\ż©żŲżŁż┐ĪŻØŖ╔«ż╣ż┘żŁżŽĘQ╚»╔Įż¼Īóź©ź├źĖż╬├µżŪżŌ┼ļ║▄ż¼ęÆżżż└żĒż”ż╚„[─ĻżĄżņżŲżżż┐źŌźąźżźļĄĪ▀_(d©ó)żžż╬Įj(lu©░)æä╠Žź═ź├ź╚ź’Ī╝ź»ż╬┼ļ║▄ż“┐╚ŖZż╩رż╚żĘżŲż”ż┐ż├żŲżżżļ┼└żŪżóżļĪ╩GoogleżŌŲ▒══ż╦źŌźąźżźļż“╗žĖ■ĪŻżĘż½żĘż▐ż║żŽĪó─ŠŖZż╬▓▌¼öżŪżóżļźŪĪ╝ź┐ź╗ź¾ź┐Ī╝żŪż╬╝┬║▌ż╬▒┐├ōż¼└Ķż╚╗ūż’żņżļĪ╦ĪŻ
źčźķźßĪ╝ź┐Ī”źŪĪ╝ź┐ż╬─Ńźėź├ź╚▓Į/░ĄĮ╠ż╬Ė·▓╠żŽĪó╣ŌÅ]▓Įż╚Ų▒╗■ż╦Š├õJ┼┼╬üżŌ▓■║¤żĄżņĪó2ŠĶż╬Ė·▓╠ż¼żóżĻČ╦żßżŲ╠ź╬ü┼¬żŪżóżļĪŻżĄżķż╦ż”ż▐ż»╣įż▒żąSRAMż╬ź¬ź¾ź┴ź├źū▓ĮżŌ▓─ē”ż╚ż╩żĻ╬╔żżż│ż╚żąż½żĻżŪżóżļĪŻŪ¦╝▒╬©ż╬─Ń▓╝ż¼Ę³Ū░żĄżņżļż¼ĪóCNN┼∙żŪĖ½żļĖ┬żĻżŽż▄ż▄╠Ążżż½żŌżĘż»żŽŠ«żĄżżż╚ż╬±T▓╠ż¼╩¾╣żĄżņżŲżżżļĪŻ
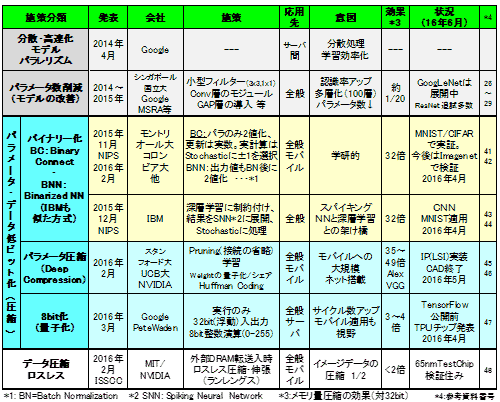
╔Į4ĪĪźčźķźßĪ╝ź┐Ī”źŪĪ╝ź┐ż╬─Ńźėź├ź╚▓Į/░ĄĮ╠ż╬Ų░Ė■
(2) ─Ńźėź├ź╚▓Į/░ĄĮ╠öĄ(sh©┤)╦Īż╬╩¼╬Ó
ĘQČ\Įčż╬Š▄║┘ż“Įęż┘żļĪŻ╔Į4ż╬źčźķźßĪ╝ź┐Ī”źŪĪ╝ź┐ż╬─Ńźėź├ź╚▓Į/░ĄĮ╠żŽ3ż─ż╦╩¼╬ÓżĄżņżļĪŻ
2-1) źąźżź╩źĻĪ╝▓ĮĪ╩1źėź├ź╚▓ĮĪ╦Ī¦
Ī▐1ż╬2├═(1źėź├ź╚)żŪ▒ķōQż“╣įż”ĪŻźąźżź╩źĻĪ╝ź│ź═ź»ź╚żŪżŽźčźķźßĪ╝ź┐ż└ż▒ż“Īóźąźżź╩źķźżź║ź╚ź═ź├ź╚ź’Ī╝ź»żŪżŽ▓├ż©żŲźąź├ź┴Ī”ź╬Ī╝ź▐źķźżź╝Ī╝źĘźńź¾ĖÕż╬Įą╬ü├═ż“2├═▓Įż╣żļĪŻż╩ż¬Īó╗@┼┘ż¼ØŁ═ūż╩│žØ{╗■ĖĒ║╣Ąš┼┴ś“╦Īż╬źčźķźßĪ╝ź┐╚∙─┤╗■żŽĪó╩▌ĘeżĘżŲżżżļźčźķźßĪ╝ź┐ż╬╝┬┐¶ż“╗╚├ōżĘżŲ├═ż“śŗ(g©░u)┐Ęż╣żļĪŻMNIST/CIFARĪ╩ź┘ź¾ź┴ź▐Ī╝ź»ż╬¹|╬ÓĪ╦żžż╬┼¼├ōżŪ╬╔żż±T▓╠ż¼įużķżņżŲż¬żĻĪó║ŻĖÕżŽImagenet┼∙ż╬Įj(lu©░)æä╠Ž▓Ķ楿Ūż╬ĖĪŠ┌ż“╣įż”┼∙·t│½ż╬╔²ż“╣Łż▓żļż╚ż╬ż│ż╚Ī╩2016ŃQ4ĘŅĪ¦╗▓╣═½@╬┴42Ī╦żŪżóżļĪŻĖÕŪvż╚ō¶ż┐öĄ(sh©┤)╦Īż“IBMż¼TrueNorthż╬ź┴ź├źūźóĪ╝źŁźŲź»ź┴źŃż╦┼¼├ōżĘżŲĪóĘ³░ŲżŪżóż├ż┐┐╝┴ž│žØ{ż½żķź╣źčźżźŁź¾ź░ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»żžČČż“▓═ż▒żļż│ż╚ż╦└«Ė∙żĘżŲżżżļĪŻ┐╝┴ž│žØ{żŪż╬└«▓╠ż“ź╣źčźżźŁź¾ź░ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╦ŠŲżŁ─ŠżĘź╦źÕĪ╝źĒźŌźļźšźŻź├ź»źóĪ╝źŁźŲź»ź┴źŃæųżŪ╝┬╣įżŪżŁżļĪŻŲ▒żĖż»ĖĮ╗■┼└żŪżŽMNIST/CIFAR(CNN)żžż╬┼¼▒■żŪżóżļĪŻŠ▄║┘żŽŗī3ŠŽżŪ└Ō£½═Į─ĻżŪżóżļĪŻ
2-2) źčźķźßĪ╝ź┐ż╬░ĄĮ╠Ī╩Deep CompressionĪ╦Ī¦
źčźķźßĪ╝ź┐ż╬░ĄĮ╠ż“│žØ{ż½żķ╝┬╣įż╦ż½ż▒żŲ╔Įż╬3ż─ż╬╗▄║÷ż“├ōżżżŲ╣įż”ĪŻĖ·▓╠żŽĮj(lu©░)żŁżżĪŻ╩Ż╗©ż╣ż«żŲ▓─£å└Łż¼ĄKżżż╚ż╬╗ž╝~żŌ£pż▒żŲżżżļĪŻż▐ż┐ĪóCĘ┐Ī╩øQ╣■ż▀┴ž╝ńöüĪ╦ż╬CNNźŌźŪźļżžż╬┼¼├ō±T▓╠ż¼┬įż┐żņżļ┼∙ĪóČ\Įčż╬Į└Ų└Łż¼ż╔ż╬µć┼┘żóżļż½ż“ē¶żĻż┐żżĪŻ
2-3) źėź├ź╚┐¶ż╬║’žō(f©┤)Ī╩╬╠╗ę▓ĮĪ╦Ī¦
▒ķōQĪ╩└čŽ┬▒ķōQĪóīÖ└Ł▓Į▒ķōQĪóźūĪ╝źĻź¾ź░Īó┘ćæä▓Įż█ż½Ī╦ż└ż▒ż“8źėź├ź╚┼D┐¶(0-255)żŪĮĶ═²ż╣żļĪŻźµĪ╝źČĪ╝żŽ“£═Ķ─╠żĻ32źėź├ź╚╔ŌŲ░Š«┐¶┼└▒ķōQż╬źķźżźųźķźĻĪ╝ż¼ż█ż▄żĮż╬ż▐ż▐╗╚ż©żļĪ╩ż╚═²▓“żĘżŲżżżļĪ╦ĪŻŲ■╬üŖõż╚Įą╬üŖõżŪźŪĪ╝ź┐ż╬╬╠╗ę▓ĮĪ╩32ó¬8źėź├ź╚Ī╦ż╚╚┐╬╠╗ę▓Įż“╣įż”ż¼Īó╩č┤╣╗■ż╬źķź”ź¾ź╔ĮĶ═²ż╬ŲDżĻ░ĘżżżŪÅR┴Tż¼ØŁ═ūż╬żĶż”żŪżóżļĪŻ2-1)Ī┴2-3)ż╚żŌČ”─╠ż╦źŽĪ╝ź╔żŌ║Ū┼¼▓ĮżĘż╩żżż╚100%ż╬Ė·▓╠ż¼░·żŁĮąż╗ż╩żżĪŻ1Ī┴2ŃQ²Xż▒żŲTPU (Tensor Processing Unit)ż╩żļź½ź╣ź┐źÓź┴ź├źūż“│½╚»żĘż┐ż│ż╚ż“Googleż¼5ĘŅż╦Įo╔ĮżĘż┐ĪŻźŪĪ╝ź┐Ī”źčźķźßĪ╝ź┐ż╬─Ńźėź├ź╚▓Įż╬Ė·▓╠żŽź¬Ī╝źąĪ╝źžź├ź╔╩¼ż¼żóżĻĪóÅ]┼┘Ī╩źĄźżź»źļ┐¶Ī╦▓■║¤ż¬żĶżėźßźŌźĻ╬╠║’žō(f©┤)żŽĘQĪ╣3Ī┴4Ū▄ż╚┐õ▒Rż╣żļĪŻźčź’Ī╝żŌŲ▒══żŪĪó±T▓╠źčź’Ī╝Ė·╬©▓■║¤ż╚żĘżŲżŽ10Ū▄µć┼┘ż╚ż╩żļĪŻ▐k╚╠źµĪ╝źČĪ╝żŽē¶żķż╩żżż”ż┴ż╦Īó8źėź├ź╚┼D┐¶ĮĶ═²ż╬źŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż“żĘżŲżżżļż│ż╚ż╦ż╩żļĪŻżŌż┴żĒż¾Īó╗@┼┘żŽ═Ņż┴ż╩żżż│ż╚ż¼Øi─¾żŪżóżļĪŻGoogleż╦ż╚ż├żŲżŽźŪĪ╝ź┐ź╗ź¾ź┐Ī╝ż╬źŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░╝┬╣įź│ź╣ź╚ż¼1/3Ī┴1/4ż╦ż╩żĻĪóż½ż╩żĻż╬źżź¾źčź»ź╚ż╚═Į„[ż╣żļĪŻźčź’Ī╝żŌžō(f©┤)żļĪŻż│ż╬ź┐źżź▀ź¾ź░żŪż╬źėź├ź╚┐¶ż╬║’žō(f©┤)ż╬╗▄║÷ż╬·t│½żŽĪóŗī1ŠŽ╦┴Ų¼żŪĮęż┘ż┐żĶż”ż╦ĪóĪųźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╬źŌźŪźļźķźżźųźķźĻĪ╝żžż╬·t│½ż╣ż╩ż’ż┴źŪĪ╝ź┐ź╗ź¾ź┐Ī╝·t│½ż╬╗ž┐¶┤ž┐¶┼¬└¬żżĪūż“ܦż©żļż┐żßż╬Ą╩Ōgż╬▓▌¼öż╚ż▀żļż│ż╚żŌĮą═ĶżļĪŻ
żĮż╬┬ŠĪó╔Į4ż╦┐āż╣żĶż”ż╦Ų■╬üĪ”├µ┤ųźŪĪ╝ź┐ż╬│░ŗźßźŌźĻż╚ż╬┼Š┴„╗■ż╦źĒź╣źņź╣░ĄĮ╠ż“╗╚ż”Č\Įčż╬╩¾╣ż¼ISSCC2016żŪMIT/NVIDIAż½żķżóż├ż┐Ī╩╗▓╣═½@╬┴48Ī╦ĪŻźŽĪ╝ź╔ż╬╩čśŗ(g©░u)żŽØŁ═ūżŪĪóĖ·▓╠żŽŠ«żĄżżż¼│╬╝┬żŪżóżļĪŻ
(3) źŌźąźżźļżžż╬╝┬äóż╬▓─ē”└ŁżŽ?!
Googleż╬Ų░żŁż╦Ė½żķżņżļżĶż”ż╦Īó┘Jż╦╝┬╣įźšź¦Ī╝ź║żŪżŽ┼D┐¶8źėź├ź╚żŽŪ¦ē¶żĄżņż─ż─żóżļĪŻ4Ū▄╝Õż╬▓■║¤żŽ│╬╝┬Ī󿥿ķż╦─Ńźėź├ź╚▓Įż¼┐╩żßżą▓■║¤żŽ32Ū▄ż▐żŪ┤³┬įżŪżŁżļĪŻ║ŻĖÕĪóĮj(lu©░)╗©Ū─ż╦10Ū▄µć┼┘ż╬
źčźķźßĪ╝ź┐ż╬─Ńźėź├ź╚▓Į/░ĄĮ╠ż¼ż╩żĄżņżļż╚▓Š─ĻżĘżŲĪóż╔ż╬µć┼┘LSI╝┬äóż╦Ė·▓╠ż¼żóżļż╬ż½ResNet34(22.0MźčźķźßĪ╝ź┐)ż“╗╚├ōżĘżŲ╗ŅōQżĘżŲż▀żļĪŻ
3-1) ØŁ═ūźßźŌźĻ?du©¼)C└迎Ī®
Øi£Iż╦╗╚├ōżĘż┐╔Į3ż╬║ŪīÜš`Ī╩źįź¾ź»┐¦ż╬Ž╚Ī╦ż╦├═ż“▓├ż©żŲżóżļĪŻ32źėź├ź╚ż╦×┤żĘżŲ1/10ż╬Ė·▓╠ż╚ż╣żļż╚Īó├╝┐¶żŪĖĮ╝┬┼¬żŪżŽż╩żżż¼3.2źėź├ź╚/źčźķźßĪ╝ź┐ż╚ż╩żļĪŻ┴ĒźßźŌźĻźėź├ź╚┐¶żŽĪó22Mx3.2=71.4Mźėź├ź╚ĪŻ║ŪŖZĮo╔ĮżĄżņżŲżżżļŠ╩¾(╗▓╣═½@╬┴49)ż½żķĪóSRAMż╬ź¬ź¾ź┴ź├źūżŪż╬ĀC└迎Īó7Mbit/mm2 @16nm ż╚ż╣żļĪŻØŁ═ūź©źĻźóĀC└迎10mm2@16nm (3mm│čäėż╬źĄźżź║)ż╚ż╩żļĪŻĪ╩152┴žż╬ResNet152ż└ż╚56MźčźķźßĪ╝ź┐żŪĪó25.5mm2ż╚ż╩żļĪŻż│żņż└ż╚żĄż╣ż¼ż╦Įj(lu©░)żŁżżĪ╦ĪŻResNet34ż└ż╚ż½ż╩żĻż╬═Š═Ąż“Ęeż├żŲSRAMż╬ź¬ź¾ź┴ź├źūźßźŌźĻ▓ĮĪ╩║«║▄Ī╦ż¼▓─ē”ż╚ż╩żļĪŻ±T▓╠Īó┐▐13ż╬║Ėż╬╝┤ż╬22MźčźķźßĪ╝ź┐░╩▓╝Ī╩ż█ż╚ż¾ż╔e-DRAM DaDianNaoż╬źķźżź¾ż╬Š»żĘæųĪ╦ż╬ōļ░ĶżŽź½źąĪ╝żŪżŁżļĪŻ╗─żļż╬żŽĪóż½ż╩żĻĮj(lu©░)żŁż╩▓“ćĄ┼┘ż╬رĪ╩Įj(lu©░)▓ĶĀCĪ╦ĪóżŌżĘż»żŽź▐źļź┴ź┐ź╣ź»ĮĶ═²ĪóČĄ╗šż╩żĘ│žØ{┼∙ż╚ż╩żļĪŻ
3-2) └čŽ┬▒ķōQż╬źčź’Ī╝żŽż╔ż╬ż»żķżżż╬źņź┘źļĪ®
źŌźąźżźļ┼ļ║▄ż“╣═ż©żļż╚Ążż╦ż╩żļ┼└ż└Ī¬Ų▒══ż╦ĪóImagenetż╬▓ĶćĄŪ¦╝▒ż“30 frames/secżŪ╣įż├ż┐Šņ╣ńż╬źčź’Ī╝ż“╗ŅōQżĘżŲż▀ż┐ĪŻŠ“°PżŽØi£IżŪ╗╚ż├ż┐żŌż╬ż╚Ų▒żĖżŪĪóLSIż╚żĘżŲżŽ1TFLOPS/Wż╬└Łē”ż¼Įąż╗żļż│ż╚ż“Øi─¾ż╚żĘżŲżżżļĪŻŲ▒żĖż»╔Į3ż╦ż▐ż╚żßż┐ĪŻ32źėź├ź╚ż╦×┤żĘżŲĪóżĮż╬10╩¼ż╬1ż╬ĮĶ═²╬╠żŪ╬╔żżż╬żŪ1/10ż╬Š├õJ┼┼╬üĪó100mWż╚ż╣żļĪŻ3.6msecżŪ1▓Ķ楟šźņĪ╝źÓż╬Ū¦╝▒ż¼Į¬ż’żļż╬żŪ╝Īż╬źšźņĪ╝źÓż¼═Ķżļ30msecµćżŽź╣ź┐ź¾źąźżėX▌åż╦ż╩żļĪŻ├▒ĮŃż╦1/10ż╬╔nŲ»╬©ż╚╣═ż©żļż╚Īó10mWµć┼┘ż╬└čŽ┬▒ķōQŠ├õJźčź’Ī╝ż╚ż╩żļĪŻź¬ź¾ź┴ź├źūSRAMż╬źčź’Ī╝┼∙Ī╣ż“▓├ż©żļż╚ĪóżŌż”Š»żĘ╗\ż©żļĪŻżĘż½żĘ░═─śż½ż╩żĻż╬źĒĪ╝źčź’Ī╝żŪźŌźąźżźļżžż╬┼ļ║▄żŌØ▓╩¼▓─ē”ż╩źņź┘źļżŪżóżļĪ╩ż╩ż¬1TFLOPS/Wż¼ż½ż╩żĻĖʿʿżż¼Ī╦ż│ż╚ż¼ż’ż½żļĪŻ
ż▐ż└Īóżżż»ż─ż½ż╬▓▌¼öżŌżóżļż¼ĪóSRAMź¬ź¾ź┴ź├źūżŪźĄźų0.1Wµć┼┘żŽĖ½╣■żßżļėXČĘż╚╣═ż©żķżņżļĪŻź©ź├źĖÅUżŽżŌż╚żĶżĻĪóźŌźąźżźļÅUżŌ╝o(j©¼)µćŲŌżŪźĒź├ź»ź¬ź¾żĄżņżŲżżżļėX▌åżŪżóżļĪŻźčźķźßĪ╝ź┐Ī”źŪĪ╝ź┐ż╬─Ńźėź├ź╚▓Į/░ĄĮ╠ż╦┤žżĘżŲ╦▄£Iż╬żżż»ż─ż½ż“ŗī3ŠŽżŪŠ»żĘŲ¦ż▀╣■ż▀Šę▓ż╣żļĪŻ
ż▐ż╚żß
║ŻĖÕż╬CNNż╬źŌźŪźļż╬┐╩▓Įż╦┤žżĘżŲżŽĪóNiNĪóGoogLeNetĪ󿬿ĶżėResNetż¼żŌż┐żķżĘż┐źŌźĖźÕĪ╝źļĘ┴╝░ż╬▓■╬╔żŪ┐╩ż¾żŪ╣įż»ż╚╣═ż©ż┐żżĪŻż│ż│╚ŠŃQż█ż╔ż╬┤ųż╦┴Ē│ń┼¬ż╩Squeeze Net(╗▓╣═½@╬┴50)ĪóENet(╗▓╣═½@╬┴52)ż╩żļźŌźŪźļż╬╚»╔ĮżŌżóżļĪŻ║ŻŃQż╬ImageNet(9ĘŅĪ┴10ĘŅ)ż¬żĶżėNIPS(12ĘŅ)żŪ║ŻĖÕż╔ż╬żĶż”ż╩┐╩▓Įż╬öĄ(sh©┤)Ė■└Łż“┐āż╣ż╬ż½ČĮ╠Ż┐╝żżĪŻżĮż╬żĶż”ż╩ź═ź├ź╚ź’Ī╝ź»źŌźŪźļż╬┐╩▓Įż╚╝²╠Jż╬╬«żņż╦▓├ż©żŲĪó╝┬║▌ż╬źóźūźĻź▒Ī╝źĘźńź¾ż╦ż╔ż╬źŌźŪźļż“ż╔ż╬żĶż”ż╦╗╚├ōż╣żļż╬ż½ż╚żżż├ż┐╝┬éz┼¬Īó╩±│ń┼¬ż½ż─ČĄ┐ā┼¬ż╩ÅBżŌ║ŻĖÕĮążŲż»żļż╚═Į„[żĘżŲżżżļĪŻŲ■╬üż╬╝ĪĖĄ┐¶ż╚Įą╬üż╬ź»źķź╣┐¶ĪóżĮżĘżŲß×═ŲĖĒ║╣šJ(r©©n)░ŽżŌ═Ēż¾żŪż»żļż╚╣═ż©żļĪŻ╗▓╣═½@╬┴51ż╬├°ŪvĪ╩PurdueĮj(lu©░)ż╬Eugenio CulurcielloČĄĶbĪóTeraDeep╝ęż╬CTOżŪLeCunĢ■ż╬ČĄż©╗ęĪ╦żŽż▐ż╚żßżļż│ż╚ż“┐ā║ȿʿŲżżżļż╬żŪ┤³┬įżĘż┐żżĪŻ
LSI▓Įż╬┤¬ĮĻż╚żĘżŲĪóŠ▄║┘ż“Ė½Č╦żßżļż▐żŪż╦żŽ╗Ļż├żŲżżż╩żżż¼Īóżóżļµć┼┘ż╬öĄ(sh©┤)Ė■└Łż“╦▄ŠŽżŪĮęż┘ż┐ĪŻ
ĪĪĪ”╣Ō└Łē”▓Įż╚╩Ż╣ńĄĪē”▓Į(źĘź╣źŲźÓ▓Į)Ī”Ī”Ī”2ż─ż╬Įj(lu©░)żŁż╩╬«żņ
ĪĪĪ”┤╦▄╣Į└«Ī╩øQ╣■ż▀┴žĪóµ£±T╣ń┴žĪóīÖ└Ł▓Į┤ž┐¶ĪóźūĪ╝źĻź¾ź░Ī”Ī”Ī”Īó│žØ{╗■ż╬Č\╦ĪĪ╦żŽ╝²╠Jżž
ĪĪĪ”źŌźŪźļż╬┐╩▓ĮĪ╩CFĘ┐ż½żķCĘ┐żžż╬öĪ╣įĪ╦Ī”Ī”Ī”CĘ┐ż¼╝ń╬«ż╦ż╩żĻż─ż─żóżļ
ĪĪĪ”CĘ┐ż╬źŌźĖźÕĪ╝źļż¼─_═ū
ĪĪĪ”┴ž┐¶ż╚ź©źķĪ╝╬©▓■║¤Ī╩źŪźŻĪ╝źū▓ĮżžĪ╦Ī”Ī”Ī”100┴ž░╩æų▓─ē”
ĪĪĪ”└čŽ┬▒ķōQ┐¶ż╚źčźķźßĪ╝ź┐┐¶Ī╩źßźŌźĻĪ╦ż╬┤žĘĖĪ”Ī”Ī”200Ī┴300Ū▄
ĪĪĪ”źŌźŪźļż╬ź┐źżźūĪ╩F,CF,CĘ┐Ī╦ż╚▒ķōQ┐¶Ī”źčźķźßĪ╝ź┐ż╚ż╬┤žĘĖ
ĪĪĪ”źčźķźßĪ╝ź┐Ī”źŪĪ╝ź┐ż╬─Ńźėź├ź╚▓Į/░ĄĮ╠ż╬Ų░Ė■Ī”Ī”Ī”ż│ż│╚ŠŃQżŪ┐╩▓Į
ĪĪĪ”ź©ź├źĖĪ”źŌźąźżźļÅUżžż╬┼¼├ōż╬▓─ē”└ŁĪ”Ī”Ī”╝o(j©¼)µćŲŌżŪźĒź├ź»ź¬ź¾
╦▄ŠŽż╬║ŪĖÕż╦▌ö’Bż╣żļĪŻLSIż╬╝┬äó┼¬ż╩╩¼╠ŅżŪĪóMITĪóStanfordĮj(lu©░)│žĪóżĮżĘżŲUCB┼∙ż╬īÖŲ░ż¼īÖ╚»żŪżóżļĪŻżĮż╬├µż╦źŪźĖź┐źļLSIż╬└▀╝Ŗ╩¼╠ŅżŪ├°ć@ż╩StanfordĮj(lu©░)│žż╬HorowitzČĄĶbż╬ź░źļĪ╝źūżŌć@ż“Žóż═żŲż¬żĻ(╗▓╣═½@╬┴46, 53, 13)ÅRų`żĄżņżļĪŻżĮżņż╦żŌ╗\żĘżŲĪóż½ż╩żĻż╬╔č┼┘żŪĮj(lu©░)│žż╬éb╩Ėż╦NVIDIAż¼ć@ż“Žóż═żŲżżżļ(źŽĪ╝ź╔ż╬GPUż╚źĮźšź╚CuDNN┼∙ż╬SDKż╬źĄź▌Ī╝ź╚)┼└ż¼Ążż╦ż╩żļĪŻ╝ĪŠŽ░╩æTĪó╦▄ŠŽż╬éb┼└ż“Ų¦ż▐ż©ĪóźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░LSIż╬övŽ®źóĪ╝źŁźŲź»ź┴źŃż¬żĶżė╝┬▒■├ōźĘź╣źŲźÓżžż╬╝┬äóż╦┌ģżļĪŻ
╗▓╣═½@╬┴ (1Ī┴32ż▐żŪżŽØiöv░╩Øi)
- Q. V. Le, and A. Y. Ng., "Building High-level Features Using Large Scale Unsupervised Learning", In International Conference on Machine Learning, June 2012. 20120626. ź░Ī╝ź░źļż╬ŪŁ.
- Mariusz Bojarski+, "End to End Learning for Self-Driving Cars", 2016ŃQ4ĘŅ25Ų³. 2016ADAS(┐▐13), CNNż╦żĶżļśOŲ░▒┐┼Š.
- ŠŠĖĄ ▒├▐k, Īų╩¼Üg┐╝┴žäė▓Į│žØ{żŪźĒź▄ź├ź╚öU(ku©░)ĖµĪū, Preferred Research (Preferred Infrastructure Inc,), 2015ŃQ6ĘŅ10Ų³ Ī╩║ŲĘŪĪ¦┐▐13ż╬źčźķźßĪ╝ź┐├═żŽ╔«Ūvż╬╗ŅōQ├═Ī╦
- Noda, , Hiroaki Arie , Yuki Suga , Tetsuya Ogata, "Multimodal integration learning of robot behavior using deep neural networks", Robotics and Autonomous Systems, Volume62, Issue6, 721-736╩Ū, 2014ŃQ6ĘŅ. ź▐źļź┴źŌĪ╝ź└źļ
- Yunji Chen, Tao Luo1,3, Shaoli Liu1, Shijin Zhang1, Liqiang He2,4, Jia Wang1, Ling Li1, Tianshi Chen1, Zhiwei Xu1, Ninghui Sun1, Olivier Temam2, "DaDianNao: A Machine-Learning Supercomputer", in Proceedings of the 47th IEEE/ACM International Symposium on Microarchitecture(MICROĪŪ14), IEEE, 2014. DaDianNaoĪó20141213.
- Vincent Vanhoucke, Andrew Senior, Mark Z. Mao, "Improving the speed of neural networks on CPUs", Įķ┤³ż╬─Ńźėź├ź╚▓ĮĖĪŲżż╬éb╩Ė
- Emily Denton, Wojciech Zaremba, Joan Bruna, Yann LeCun, Rob Fergus, "Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation", 2014ŃQ6ĘŅ9Ų³. Separable Filter.
- Daniel Soudry, Itay Hubara, Ron Meir, "Expectation Backpropagation: Parameter-Free Training of Multilayer Neural Networks with Continuous or Discrete Weights", 2014ŃQ12ĘŅ, ź╦źÕĪ╝źĒź¾ż╚╔ķ▓┘ż“Ī▐1Ī╩Binary▓ĮĪ╦.
- Matthieu Courbariaux, Yoshua Bengio, Jean-Pierre David, "BinaryConnect: Training Deep Neural Networks with binary weights during propagations", 2016ŃQ4ĘŅ18Ų³(ver3). Binary Connect.
- Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran El-Yaniv, Yoshua Bengio, "Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1", 2016ŃQ3ĘŅ13Ų³(v3). Binarized NN
- Steve K. Esser, Rathinakumar Appuswamy, Paul Merolla, John V. Arthur, and Dharmendra S. Modha, "Backpropagation for Energy-Efficient Neuromorphic Computing", Advances in Neural Information Processing Systems 28 (NIPS 2015), 2015ŃQ12ĘŅNIPS2015.SNNżžBP┼¼├ō.
- Steven K. Esser, Paul A. Merolla, John V. Arthur, Andrew S. Cassidy, Rathinakumar Appuswamy, Alexander Andreopoulos, David J. Berg, Jeffrey L. McKinstry, Timothy Melano, Davis R. Barch, Carmelo di Nolfo, Pallab Datta, Arnon Amir, Brian Taba, Myron D. Flickner, Dharmendra S. Modha, "Convolutional Networks for Fast, Energy-Efficient Neuromorphic Computing", 2016ŃQ5ĘŅ24Ų³(V2).ź╣źčźżźŁź¾ź░NNżžż╬CNN/BP▒■├ō.
- Song Han, Huizi Mao, William J. Dally, "Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding", 2016ŃQ2ĘŅ15Ų³(V5).Deep Compression.
- Song Han, Xingyu Liu, Huizi Mao, Jing Pu, Ardavan Pedram, Mark A. Horowitz, William J. Dally, "EIE: Efficient Inference Engine on Compressed Deep Neural Network", 2016ŃQ5ĘŅ3Ų³(V2). Deep Compression IP▓Į.
- Pete Warden, "How to quantize Neural Networks with TensorFlow", źųźĒź░, 2016ŃQ5ĘŅ3Ų³, ▒ķōQż╬╬╠╗ę▓ĮĪ╩32bitó¬8bitĪ╦
- Yu-Hsin Chen, Tushar Krishna, Joel Emer, Vivienne Sze, "Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks", 2016 IEEE International Solid-State Circuits Conference, Session 14.5, p262-264, 2016ŃQ2ĘŅ Eyeriss CNNż╬║Ū┼¼övŽ®(ISSCC2016)
- Ų³ĘąźŲź»ź╬źĒźĖĪ╝ź¬ź¾źķźżź¾ĪĪ"źļź═źĄź╣Īó16nmFinFETĖ■ż▒źŪźÕźóźļź▌Ī╝ź╚ļm╣■ż▀SRAMż“│½╚»", 2015ŃQ12ĘŅ8Ų³. SRAMż╬ĀC└č
- Forrest N. Iandola, Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, Kurt Keutzer, "SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and &llt;0.5MB model size", 2016ŃQ4ĘŅ6Ų³Ī╩V3Ī╦, Squeeze Net.
- Eugenio Culurciello, "Neural Network Architectures", źųźĒź░, 2016ŃQ6ĘŅ4Ų³ ║ŲĘŪ, Neural Network Architectureż╬źĄź▐źĻ.
- Adam Paszke, Abhishek Chaurasia, Sangpil Kim, Eugenio Culurciello, "ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation", ENet, 2016ŃQ6ĘŅ7Ų³. źĻźóźļź┐źżźÓż╬Semantic Segmentation.
- Xuan Yang, Jing Pu, Blaine Burton Rister, Nikhil Bhagdikar, Stephen Richardson, Shahar Kvatinsky, Jonathan Ragan-Kelley, Ardavan Pedram, Mark Horowitz, "A Systematic Approach to Blocking Convolutional Neural Networks", 2016ŃQ6ĘŅ14Ų³. ź╣ź┐ź¾źšź®Ī╝ź╔Įj(lu©░)│ž ź█źĒźėź├ź─ČĄĶb┤žŽó.
- Jost Tobias Springenberg, Alexey Dosovitskiy, Thomas Brox, Martin Riedmiller, "Striving for Simplicity: The All Convolutional Net", 2014ŃQ12ĘŅ21Ų³. All-CNN(CĘ┐)
- Zhun Sun, Mete Ozay, Takayuki Okatani, "Design of Kernels in Convolutional Neural Networks for Image Classification", 2015ŃQ11ĘŅ30Ų³. Hex Kernels(CĘ┐).

