ź╦źÕĪ╝źĒź┴ź├źū▄ć?y©ón)ŌĪĪĪ┴żżżĶżżżĶ╚ŠŲ│öüż╬Įą╚?4-2)
ź╦źÕĪ╝źĒź┴ź├źūż╬┬Õ╔Į╬Ńż╚żĘżŲĪóĪ╩4-2Ī╦żŪżŽDNNĪ╩źŪźŻĪ╝źūź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»Ī╦ż╬│½╚»2╬Ńż“Šę▓ż╣żļĪŻ├µ╣±▓╩│ž▒Īż╬DaDianNaoź┴ź├źūż╚Īó▄f╣±KAISTż╬DL/DIĪ╩Deep Learning/Deep InferenceĪ╦ź┴ź├źūż“Šę▓żĘżŲżżżļĪŻĪ╩ź╗ź▀ź│ź¾ź▌Ī╝ź┐źļįćĮĖ╝╝Ī╦
├°ŪvĪ¦ĖĄ╚ŠŲ│öü═²╣®│žĖ”ē|ź╗ź¾ź┐Ī╝Ī╩STARCĪ╦/ĖĄ┼ņėøĪĪ╝å└źĪĪĘ╝
4.2ĪĪ┬Õ╔Į┼¬ź┴ź├źūĪ╩DNN├ōź┴ź├źūĪ╦Ī┴DRAM║«║▄żŌżĘż»żŽ│žØ{ĄĪē”
╦▄£IżŪżŽĪóČ╣▒Iż╬DNNĪ╩ØÖC(j©®)NNĪ╦├ōż╬ź┴ź├źūż╬└Ō£½ż“ż╣żļĪŻµ£±T╣ń┴ž╝ńöüż╬╣Į└«ż“Ū░Ų¼ż╦Īó│žØ{ĄĪē”ż“Ę¾ż═×óż©ż┐ź┴ź├źūżŪżóżļĪŻżĘż½żĘövŽ®╣Į└«ż▐żŪŠ▄żĘż»ĄŁĮężĘż┐╬ŃżŽŠ»ż╩żżĪŻ╦▄ŠŽżŪżŽCASĪ╩├µ╣±▓╩│ž▒ĪĪ╦ż╬DaDianNaoż╚KAISTż╬DL/DIĪ╩Deep Learning/Deep InferenceĪ╦ż╬2ź┴ź├źūż“└Ō£½ż╣żļĪŻØiŪvżŽ2014ŃQ12ĘŅż╬Micro47żŪĪóĖÕŪvżŽ2015ŃQ2ĘŅż╬ISSCC2015żŪ╚»╔ĮżĄżņż┐ĪŻČ”ż╦źšźļź┌Ī╝źčĪ╝ż╬éb╩ĖĪ╩╗▓╣═½@╬┴37, 86Ī╦ż¼ĮążĄżņż┐ĪŻ
DaDianNaożŽĪó│╚─ź└Łż“Ęeż─ź¬Ī╝źļź▐źżźŲźŻĪ╝ż╩ź╣Ī╝źčĪ╝ź┴ź├źūżŪżóżļĪŻDl/DIżŽDBNż╬ź═ź├ź╚ź’Ī╝ź»źŌźŪźļż╦øQ╣■ż▀┴žż╬═ū┴Ūż“Ų■żņż┐żŌż╬żŪżżż’żµżļCDBNĪ╩Convolutional Deep Brief NetworkĪ╦×┤▒■ż╬ź┴ź├źūżŪżóżļĪŻż╣ż╩ż’ż┴RBMż╦żĶżļ│žØ{ż“ŲDżĻŲ■żņż┐╦▄│╩┼¬ż╩└ņ├ōź┴ź├źūżŪżóżļ┼└ż╦ÅRų`żĘżŲ═▀żĘżżĪŻż╩ż¬Īóµ£±T╣ńż╬źŌźŪźļżŪżóżļRNNż╚RL(Reinforcement LearningĪ¦äė▓Į│žØ{)ż╦┤žżĘżŲżŽ│õ░”żĘż┐ĪŻ
(1)DaDianNao (CAS) Ī┴ A Machine-Learning Supercomputer
ż│ż╬ź┴ź├źūżŽĪó2014ŃQ¼Źż╬Micro47Ī╩The 47th International Symposium on Microarchitecture)żŪBest Paper Awardż“£pŠ▐żĘż┐ź┴ź├źū(CAD╝┬äóż▐żŪ)żŪżóżļĪ╩╗▓╣═½@╬┴37Ī╦ĪŻź┐źżź╚źļż╦Ī╔A Machine-Learning SupercomputerĪ╔ż╚¤²ż▒żķżņżŲżżżļżĶż”ż╦“£═Ķż╬GPUż╬└Łē”ż“Å]┼┘żŪ50Ī┴100Ū▄Īóź©ź═źļź«Ī╝Ė·╬©żŪ1000Ū▄µć┼┘▓■║¤żĘż┐żŌż╬żŪżóż├ż┐ĪŻ1ŃQ╚Š░╩æųĘąż─ż¼Īóź’ź¾ź┴ź├źūż╚żĘżŲ╝┬䮿╬Å]┼┘żŪĪó5.6 TOPS (Tera Operations Per Second)ż╬└Łē”ż“Ėžż├żŲżżżļĪ╩ĖÕĮęż╣żļEIEż¼Īó░ĄĮ╠Č\Įčż“├ōżż╝┬Ė·└Łē”żŪDaDianNaoż“æų?j©½n)vż├żŲżżżļĪ¦╔Į6Ī╦ĪŻČ”Ų▒├°Ūvż╬╩®InriaĪ╩źšźķź¾ź╣╣±╬®Š╩¾│žśOŲ░öU(ku©░)ĖµĖ”ē|ĮĻĪ╦ż╬Č\ĮčŪvż“źĻĪ╝ź└ż╚żĘżŲ»dżŁ│½╚»ż“┐õ┐╩żĘż┐ĪŻ2014ŃQ¼Źż╬┼÷╗■żŌĖĮ║▀żŌ│žØ{ż╬╗■┤ųż“żżż½ż╦ø]Į╠Ī╩▒ķōQż╬╣ŌÅ]▓ĮĪ╦ż╣żļż½ż¼Ą╩Ōgż╬▓▌¼öżŪżóż├ż┐ż│ż╚ż½żķĪóĪ╩AlexNetż╬│žØ{ż╬╬ŃżŌżóżļż¼Īó┼÷╗■żŽ▓┐żŪżóżņ│žØ{ż╦1ĮĄ┤ųżŽż½ż½żļż╚Ė└ż’żņżŲżżż┐Ī╦źóźļź┤źĻź║źÓż╬Ė”ē|ŪvżõźóźūźĻź▒Ī╝źĘźńź¾źĄźżź╔ż╬öĄ(sh©┤)ż╚ż╬▓±ÅBżŪżĶż»ÅB¼öż╦æųżĻĪóż½ż─┤³┬įż╬Įj(lu©░)żŁż½ż├ż┐ź┴ź├źūżŪżóż├ż┐ĪŻ
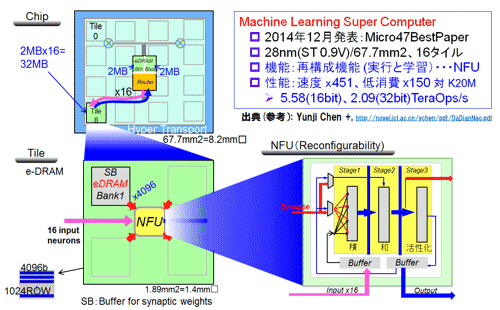
┐▐31ĪĪDaDianNao(CAS)ż╬▄ć═ū╗┼══ Ī╩╗▓╣═½@╬┴37ż“╗▓╣═ż╦║Ņ└«Ī╦
Ī╩źóĪ╦ź┴ź├źū╣Į└«
éb╩ĖżŽĪóCNN/DNNż╩żĻAlexNet┼∙ź═ź├ź╚ź’Ī╝ź»źŌźŪźļż╬ē¶╝▒ż¼ż╩żżż╚Ų╔ż▀ż┼żķżżż¼ĪóLSIżŌżĘż»żŽDRAM║«║▄ź┴ź├źūż╚żĘżŲż▀żļż╩żķżąŲŌ═ŲżŽ├▒ĮŃż└ĪŻźßźŌźĻż╬│╩Ū╝żŽĪó│░ż½żķŲ■ż├żŲż»żļŲ■╬üĪ”Įą╬üźąź├źšźĪ├ōĪ󿬿Ķżė─_ż▀Ī╩źĘź╩źūź╣├═Ī╦ż╬│╩Ū╝żŽDRAM║«║▄żŪĪóżĮżĘżŲ├µ┤ųźŪĪ╝ź┐ż╬▐k╗■│╩Ū╝żŽSRAMżŪ╣įż├żŲżżżļĪŻ┐▐31ż╬║Ėæųż╬┐▐ż¼Ū█Åøż└ĪŻ32MBż“─_ż▀ż╦ĪóŲ■Įą╬üźąź├źšźĪ├ōż╦4MBż“│õżĻ┐Čż├ż┐ĪŻØiŪvżŽź┐źżźļėXż╬16ź§ĮĻż╦Ū█ÅøżĄżņĪóĖÕŪvżŽ├µ┐┤ż╦Ū█ÅøżĄżņż┐ĪŻ╝■╩š╗═öĄ(sh©┤)ż╦Hyper Transportż╬─╠┐«├ōźżź¾ź┐Ī╝źšź¦Ī╝ź╣ż“Ū█ÅøżĘż┐ĪŻźšźĪź”ź¾ź└źĻż╚żĘżŲSTMicroelectronicsż╬28nmźūźĒź╗ź╣ż“„[─ĻżĘżŲżżżļĪŻź┴ź├źūźĄźżź║żŽĪó8.2mm│čż└ĪŻ
ź┴ź├źūż╬├µ┐┤ż╬źąź├źšźĪż╚ź┐źżźļż╚żŽĪóģ╬ż├ż┐ź╚ź▌źĒźĖĪ╝Ī╩Fat Tree╣Į└«(16źėź├ź╚)Ī╦żŪ─╠┐«ż“╣įż├żŲżżżļĪŻżĮż╬▐kż─ż╬ź┐źżźļĪ╩TileĪ¦║Ė▓╝)żŽĪó4Ė─ż╬eDRAMż╬źąź¾ź»ż╦╩¼ż½żņżļĪŻźąź¾ź╔╔²żŽ4,096źėź├ź╚/źąź¾ź»ż╚ż½ż╩żĻĮj(lu©░)żŁżżĪŻź┐źżźļż╬├µ┐┤ż╦NFUĪ╩Neural Function UnitĪ╦ż“Ń~ż╣żļĪŻźąź¾ź»ż½żķ─_ż▀Ī╩źĘź╩źūź╣├═Ī╦ż“Ų╔ż▀╣■ż▀Īó║Ėż½żķŲ■żļŲ■╬üźŪĪ╝ź┐ż╚żŪ▒ķōQĮĶ═²ż“NFUż¼╣įż”ĪŻīÜ▓╝ż╦NFUŲŌŗ╣Į└«ż“┐āżĘż┐ĪŻźįź¾ź»└■ż¼Ų■╬üźŪĪ╝ź┐Ī╩Ų■╬üØŖ─¦ź▐ź├źūżŌżĘż»żŽŲ■╬üźżźßĪ╝źĖĪ╦Īó×E└■ż¼Įą╬üźŪĪ╝ź┐Ī╩Įą╬üØŖ─¦ź▐ź├źūĪ╦ż“Ī󿥿ķż╦śĘ└■ż¼─_ż▀Ī╩źĘź╩źūź╣├═Ī╦ż╬╬«żņż“┐āż╣ĪŻ
Ī╩źżĪ╦NFU (Neural Function Unit)
16Ų■╬üĪ╩16ź╦źÕĪ╝źĒź¾Ī╦ż¬żĶżė16Įą╬üĪ╩16ź╦źÕĪ╝źĒź¾Ī╦ż¼Ų▒╗■ż╦░Ęż©żļĪŻśĘżż╠░§żŽĪóźĘź╩źūź╣├═Ī╩─_ż▀Ī╦ż╬Ų╔ż▀╣■ż▀źčź╣żŪżóżļĪŻĘQźųźĒź├ź»żŽĪó└čĪóŽ┬Īó┘ćæä▓Į┤ž┐¶/īÖ└Ł▓Į┤ž┐¶ĮĶ═²Ī╩Transfer┤ž┐¶Ī╦ĪóĮą╬üĪó├µ┤ų├═źąźżźčź╣ĮĶ═²Ī╩żĮż╬ż┐żßż╦ØiĮężĘż┐żĶż”ż╦8KBż╬SRAMż“ŲŌē┼Ī╦ż“£pż▒Ęeż─ĪŻ
16x16=256źĘź╩źūź╣Ī╩─_ż▀Ī╦ż¼źóź»ź╗ź╣▓─ē”żŪżóżļĪŻ256Ė─ż╬MACĮĶ═²ż¼╩┬╣įżŪŲ▒╗■ż╦╣įż©żļĪŻ256 MACĪ▀2 Ī▀16TileĪ▀0.606 GHz = 5.0 TOPSż╬ĮĶ═²ē”╬üż“Ń~ż╣żļ(╝┬║▌żŽżŌż”32 MAC╩¼▒ķōQż¼▓─ē”żŪ5.6 TOPS)ĪŻ│žØ{╗■ż╦żŽź╗źņź»ź┐żŪŠ╩¾ż╬źčź╣ż“║Ų╣Į└«żĘźšź¦Ī╝ź║ż╬╩čśŗ(g©░u)ż╦×┤▒■ż╣żļĪŻźšźŻĪ╝ź╔źąź├ź»├═Ī╩gradientĪ╦ż“Ų■╬üż╣żļźčź╣Īóż▐ż┐╚∙─┤┼DĖÕż╬źĘź╩źūź╣├═Ī╩Updated SynapseĪ╦ż“e-DRAMż╦│╩Ū╝ż╣żļźčź╣ż“║Ų╣Į└«ż╣żļĪŻ
Ī╩ź”Ī╦ź│ź¾źšźŻź«źÕźķźėźĻźŲźŻ Ī╩║Ų╣Į└«Ī╦
┐▐32ż╦┴žĪ󿬿Ķżėźšź¦Ī╝ź║Ī╩│žØ{ż╚╝┬╣įĪ╦ż╬└┌żĻü÷ż©ż╬╬«żņż“┐āżĘż┐ĪŻéb╩Ėż“╗▓╣═ż╦¾HŠ»┐õ▒Rż“Ų■żņżŲ║Ņ└«żĘż┐ĪŻ┐▐31ż╬īÜ▓╝┐▐ż╬NFU(Neuron Function Unit)ż╬źčźżźūźķźżź¾ż╬ź╣źŲĪ╝źĖĪ╩Stage 1/2/3Ī╦ż“└┌żĻü÷ż©żļż│ż╚ż╦żĶżĻĪóøQ╣■ż▀┴ž/µ£±T╣ń┴ž/źūĪ╝źĻź¾ź░┴ž/┘ćæä▓Į┤ž┐¶żóżļżżżŽīÖ└Ł▓Į┤ž┐¶ż╬ĘQĮĶ═²ż“║Ų╣Į└«ż╣żļĪŻżŌż┴żĒż¾ĪóźĘź╩źūź╣ż╬Ų■╬üż╬Ń~╠ĄżŌ┤žŽóż╣żļĪŻźūĪ╝źĻź¾ź░┴žż╩żķźĘź╩źūź╣ż╬Ų■╬üżŽ╔į═ūż└ĪŻź═ź├ź╚ź’Ī╝ź»ż╬ĮĶ═²ż¼┐╩ż▀Īó┴žż¼╩čż’żļĪ╩╬Ńż©żąøQ╣■ż▀┴žż½żķźūĪ╝źĻź¾ź░┴žĪ╦ź┐źżź▀ź¾ź░żŪź└źżź╩ź▀ź├ź»ż╦└┌żĻü÷ż©żļĪŻż▐ż┐╝┬╣įźŌĪ╝ź╔ż½żķ│žØ{źŌĪ╝ź╔żŌŲ▒══ż╦└┌żĻü÷ż©żļż¼ĪóØiĮężĘż┐źĘź╩źūź╣ż╬źóź├źūźŪĪ╝ź╚ż╬źčź╣żŌ╣Į├█ż╣żļØŁ═ūż¼żóżļĪŻĮń┼┴ś“Ī╩Forward PropagationĪ╦ż╚Ąš┼┴ś“Ī╩Backward PropagationĪ╦ż╬└┌ü÷ż©ż╦żĶżĻ│žØ{ż“╣įż”öU(ku©░)╠¾ź▄źļź─ź▐ź¾ź▐źĘź¾Ī╩RBMĪ¦Restricted Boltzmann Machine)ż╬Š}╦Īż“├ōżżż┐│žØ{ż╬ĄŁĮęż¼Ń~żĻ┼¼├ōżĘżŲżżżļ╠Ž══ż└Ī╩Š▄║┘ż╬└Ō£½żŽż╩żżĪ╦ĪŻ
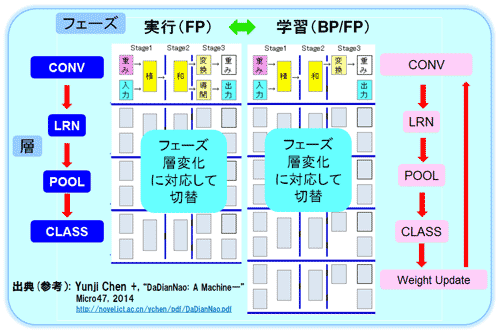
┐▐32 ║Ų╣Į└«ż╬└┌żĻü÷ż©ż╬╬«żņż╬▄ćŠS┐▐ĪĪĪ╩╗▓╣═½@╬┴37ż“╗▓╣═ż╦║Ņ└«Ī╦
Ī╩ź©Ī╦±T▓╠Ī¦└Łē”
Š├õJ┼┼╬üĪ¦┐▐33ż╦źĘź▀źÕźņĪ╝źĘźńź¾ż╦żĶżļŠ├õJ┼┼╬üż╬╩¼╔█ż“┐āżĘż┐ĪŻź┴ź├źūµ£öüżŪ16Wż╚╗ŅōQżĄżņżŲżżżļĪŻżĮż╬ż”ż┴ź┴ź├źū┤ų─╠┐«ż“╣įż”╣Ō└Łē”┼┴┴„övŽ®Ī╩HTĪ¦Hyper TransportĪóPoint to Point╝░ż╬└@├ō└▄¶öČ\ĮčĪ╦ż╬Š├õJ┼┼╬üż¼╚Š╩¼ż“žéżßż┐ĪŻ├°ŪvżķżŌĮęż┘żŲżżżļż¼║ŻĖÕ╣®╔ūż¼ØŁ═ūż╩┼ōĮĻż└ĪŻż╩ż¬Īó╦▄ź┴ź├źūżŽźĄĪ╝źą├ōż╩ż╬żŪĪó¾Hź┴ź├źūżŪż╬·t│½ż“£å╠Ņż╦Ų■żņżļż│ż╚ż¼ØŁ┐▄ż└ĪŻ┤║ż©żŲ├▒öüżŪż╬╗╚├ōż“Ū░Ų¼ż╦Åøż»ż╚Ī╩╬Ńż©żąź©ź├źĖÅU▒■├ōĪ╦Īóµ£öüż╚żĘżŲżŽ10W░╠ż╬Š├õJ┼┼╬üż╚ż▀ż╩ż╗ĪóŲŌŗRAMźóź»ź╗ź╣ż╦6Wż“═ūżĘżŲżżżļĪŻŲŌē┼ż╚żŽżżż©ĪóDRAMżŪżŽŠ├õJ┼┼╬üż¼żõżŽżĻĮj(lu©░)żŁżżĪŻ
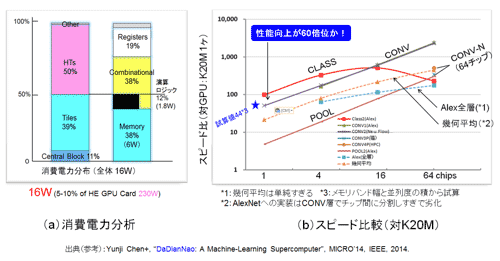
┐▐33ĪĪDaDianNaoż╬Š├õJ┼┼╬ü╩¼└Žż╚ź╣ź▒Ī╝źķźėźĻźŲźŻ╚µ│ėĪĪĪ╩╗▓╣═½@╬┴37ż“╗▓╣═ż╦║Ņ└«Ī╦
ĮąųZĖĄĪ¦STARCż╬─┤Øh╩¾╣Į±żĶżĻ┼Š║▄
ź╣źįĪ╝ź╔Ī¦┐▐33ż╦éb╩Ėż╬źŪĪ╝ź┐ż“╗▓╣═ż╦║Ņ└«żĘż┐ź╣źįĪ╝ź╔ż╬źŪĪ╝ź┐ż“┐āżĘż┐ĪŻāe╝┤żŽNVIDIAż╬GPU K20Mż╚ż╬┴Ļ×┤ź╣źįĪ╝ź╔╚µż└ĪŻ▓Ż╝┤żŽ╩┬š`Ų░║ŅżĄż╗ż┐┐¶Ī╩ź╣ź▒Ī╝źķźėźĻźŲźŻĪ╝Ī╦ż└ĪŻź┴ź├źūż“╗\żõż╣╦Ķż╦└Łē”ż¼ź╣ź▒Ī╝źļźóź├źūż╣żļż½Ī╩─Š└■ż¼╦Šż▐żĘżżĪ╦ż“╚ĮéāżŪżŁżļĪŻżżż»ż─żŌż╬└■ż¼żóżļż¼ĪóøQ╣■ż▀┴ž(CONV┴ž)ĪóźūĪ╝źĻź¾ź░┴žĪ╩Pool┴žĪ╦┼∙ż╬ź╣ź▒Ī╝źĻź¾ź░└Łē”ż“┐āżĘż┐ĪŻµ£öüż╦1ź┴ź├źūżŪ10Ī┴100Ū▄ż╬╣ŌÅ]└Łż“┐āżĘżŲżżżļĪŻź╣źįĪ╝ź╔CONV┴žż╚CLASS┴žĪ╩µ£±T╣ń┴žĪ╦żŪ»éż▐żļż│ż╚ż½żķżĮż╬├µ┤ų├═ż╚ż▀żŲĪóź’ź¾ź┴ź├źūż╬Šņ╣ńż╦żŽ60Ū▄µć┼┘ż╬▓■║¤ż¼Ė½żķżņżļĪŻ
GPU K20Mż╬╗┼══źŪĪ╝ź┐ż╚DaDianNaoż╬övŽ®╣Į└«ż½żķź╣źįĪ╝ź╔└Łē”╚µ│ėż“į~├▒ż╦╗ŅōQżĘż┐ĪŻźßźŌźĻźąź¾ź╔╔²ż╚MACż╬┐¶ż“├▒ĮŃż╦²Xż▒ż┐żŌż╬żŪ╚µ│ėż╣żļż╚ĪóDaDianNaożŽ44Ū▄ż╬└Łē”ż¼├▒öüĪ╩ź’ź¾ź┴ź├źūĪ╦żŪĮążļż│ż╚ż¼ż’ż½żļĪŻDaDianNaoż╚K20Mż╚ż╬É║öü┼¬ż╩┐¶├═ż“┐āż╣ż╚Īóźąź¾ź╔╔²ż¼5TB/s×┤Īó208GB/sżŪ24Ū▄ĪóMAC┐¶ż¼9kĖ─×┤5kĖ─żŪ1.8Ū▄ż╚ż╩żĻĪó╬ŠöĄ(sh©┤)ż“²Xż▒╣ńż’ż╗żļż╚╠¾44Ū▄ż└ĪŻäh▓┴├═ż╚ż█ż╚ż¾ż╔╩čż’żķż╩żżĪŻ
ź▌źżź¾ź╚żŽź╣ź▒Ī╝źķźėźĻźŲźŻż└ż¼CONV┴žżŽż█ż▄─Š└■ż└Ī╩╣{ĻJ═Ņż┴żļż╬żŽŲ■╬üź▐ź├źūż╬╝■╩šż╬ĮĶ═²ż╬▒Ųūxż¼ĮążļĪ╦ĪŻ─_═ūż╩ż╬żŽµ£±T╣ńż╬CLASS┴žż└ż¼Ī󿥿╣ż¼ż╬DaDianNaożŪżŌ16ź┴ź├źū░╩æųżŪ└Łē”ż¼╬¶▓ĮżĘżŲżżżļĪŻCONV┴žż└ż╚Ų╚╬®żĘżŲżżżļż╬żŪ╩¼Ū█ż╦żĶżļĄK▒ŲūxżŽŠ«żĄżżĪŻż╚żŽżżż©ĪóCONV┴žż╚CLASS┴žż╬╩┐ČčżŪĖ½żļż╚16ź┴ź├źūż½żķ64ź┴ź├źūż╬┤ų░╠ż▐żŪżŽź╣ź▒Ī╝źķźėźĻźŲźŻż¼żóżĻĪóżĮż╬╚µ╬©żŽ800Ū▄µć┼┘ż╬╣ŌÅ]▓Įż¼Ė½╣■żßżļĪ╩×┤K20Mżęż╚ż─ż╚ż╬╚µ│ėżŪżóżļ┼└ÅR┴Tż¼ØŁ═ūż└ż¼Īó┼÷─śGPUż╬ź╣ź▒Ī╝źķźėźĻźŲźŻżŽČ╦żßżŲ─ŃżżżŽż║ż└Ī╦ĪŻ
┬Šź┴ź├źūż╚ż╬╚µ│ėĪ¦Eyrissż╚ż╬╚µ│ėż“ż╣żļĪŻ╔Į6żŪĪóĀC└čĖ·╬©(GOPS/mm2)ż╚źŪźČźżź¾źļĪ╝źļż╚╝■āS┐¶ż“╩┬ż┘żļż╚ĪóDaDianNao (82.7 GOPS/mm2, 28nm, 606MHz) vs Eyriss (6.23 GOPS/mm2, 65nm, 200MHz)ż╚ż╩żļĪŻEyrissż“DaDianNao╩┬ż▀ż╦ż╣żļż╚Īó102 GOPS/mm2ż╚ż╩żļĪŻIoEżŪżŌŲ▒══żŪżóżļĪŻEyeriss/IoEż¼øQ╣■ż▀┴ž├ōż╬ź┴ź├źūżŪżóżļż│ż╚ż½żķĪóDaDianNao/DRAM║«║▄ż¼źßźŌźĻźóź»ź╗ź╣ć·Å]ż╬µ£±T╣ńżŌżĘż»żŽ│žØ{├ōż╬ź┴ź├źūż╚żĘżŲĮķżßżŲØŖ─¦ż¼Įążļż│ż╚ż“▓■żßżŲŪ¦╝▒żŪżŁżļĪŻ
(2)DL/DI (Deep Learning/Deep Inference) (KAIST)Ī┴DBNż“╦▄│╩╝┬äó
2015ŃQż╬ISSCCżŪ▄f╣±KAISTżĶżĻ╚»╔ĮżĄżņż┐Ī╩╗▓╣═½@╬┴86Ī╦ĪŻČĄ╗š╠ĄżĘ│žØ{ż¼▓─ē”ż╩ź┴ź├źūż└ĪŻDaDianNaoż╚░█ż╩żĻ│žØ{ż╚╝┬╣įż╬ĘQĪ╣ż╬övŽ®ż“Ęeż─ĪŻDL/DIż╬Ō}Š╬żŽ╔«Ūvż¼éb╩Ėż╬ź┐źżź╚źļżĶżĻŲDż├ż┐ĪŻDaDianNaoż¼źĄĪ╝źąż“╝ńź┐Ī╝ź▓ź├ź╚ż╚żĘż┐ż╬ż╦×┤żĘĪóDL/DIżŽźšźĒź¾ź╚ź©ź¾ź╔Ī╩ź©ź├źĖĪ╦żŌżĘż»żŽź╦źóź©ź¾ź╔Ī╩źšź®ź░źĄźżź╚Ī╦ż“ź┐Ī╝ź▓ź├ź╚ż╚żĘżŲżżżļĪŻ╚»╔ĮżŪżŽź»źķź”ź╔Ŗõż╬źŪĪ╝ź┐│╩Ū╝/─╠┐«ż╬╔ķ├┤║’žō(f©┤)ż╬ż┐żßż╦ź╦źóź©ź¾ź╔ż╦│žØ{ĄĪē”ż“Ęeż┐ż╗żļ┼└ż╦─_żŁż“ż¬żżżŲ╣ų▒ķż“╣įż├żŲżżżļż¼Īóż█ż▄1ŃQĖÕż╬źšźļź┌Ī╝źčĪ╝żŪżŽĪóźŌźąźżźļżŪż╬│žØ{ĄĪē”┼ļ║▄ż▐żŪź┐Ī╝ź▓ź├ź╚ż“╣Łż▓żŲéb╩Ėż“╣Į└«żĘżŲżżżļĪŻ0.2Wµć┼┘żŪĪóź©ź═źļź«Ī╝Ė·╬©żŽ1.93 TOPSż╚ż½ż╩żĻ╣Ōżżż│ż╚ż½żķ┼¼├ōšJ(r©©n)░ŽżŽ╣ŁżżĪŻ
Ī╩źóĪ╦│žØ{ĄĪē”Ī”Ī”Ī”ČĄ╗š╠ĄżĘ│žØ{
┐▐34ż╦éb╩Ėż“╗▓╣═ż╦║Ņ└«żĘż┐ź┴ź├źūż╬źųźĒź├ź»╣Į└«ż“┐āżĘż┐ĪŻ╝┬╣įź©ź¾źĖź¾Ī╩Deep Inference EngineĪ╦ż╚Īó│žØ{ź©ź¾źĖź¾Ī╩Deep Learning EngineĪ╦Ī󿥿ķż╦żŽź░źĒĪ╝źąźļż╩═┐¶╚»Ö┌övŽ®Ī¦TRNG (True Random Number Generator) ż╬3ż─ż╬╣Į└«ż½żķż╩żļĪŻ│žØ{ź©ź¾źĖź¾żŽ4ż─ż╬ź│źóĪ╩DLź│źóĪ╦ż½żķż╩żļĪŻŠ▄║┘ż╩└Ō£½żŽ│õ░”ż╣żļż¼Īó4ż─ż╬ź╣źŲĪ╝źĖż½żķż╩żļźčźżźūźķźżź¾╣Į└«ż╚ż╩ż├żŲżżżļĪŻż½ż─ź▌źĖźŲźŻźųż╚ź═ź¼źŲźŻźųż╬Ų¾─_ź╣źņź├ź╔öĄ(sh©┤)╝░ż“║╬├ōżĘżŲżżżļĪŻDBN (Deep Neural NetworkĪ¦╗▓╣═½@╬┴78, 80) ż╦ż¬ż▒żļRBM (Restricted Boltzmann Machine 76,77) żŪż╬Negative/PositiveöĄ(sh©┤)Ė■ż╬│žØ{Š}Įńż“Ė·╬©żĶż»╝┬ĖĮż╣ż┘ż»╣Į└«żĄżņżŲżżżļż╚ż▀żŲżżżļĪŻ
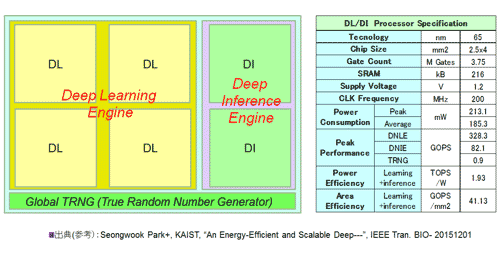
┐▐34 DL/DIż╬▄ć═ū╗┼══ĪĪ(╗▓╣═╩ĖĖź86ż“╗▓╣═ż╦║Ņ└«)
Ī╩źżĪ╦═┐¶╚»Ö┌▀_(d©ó)ż¬żĶżėżĮż╬ČĪĄļźĘź╣źŲźÓĪ╩ź═ź├ź╚ź’Ī╝ź»Ī╦
┐▐34ż╦┐āżĘż┐żĶż”ż╦Īó│žØ{Ī╩DLĪ╦ż¬żĶżė╝┬╣įĪ╩DIĪ╦ż╦ØŁ═ūż╩═┐¶╚»Ö┌▀_(d©ó)żŽ▒ķōQź©ź¾źĖź¾ż╦×┤żĘżŲĪóĖ─Ī╣ż╦Ęeż─öĄ(sh©┤)╝░żŪżŽż╩ż»ĀC└čĖ·╬©ż╬╬╔żżź░źĒĪ╝źąźļĪ╩GlobalĪ╦ż╩öĄ(sh©┤)╝░ż“║╬├ōĪ╩┐▐ż╬TRNGĪ╦żĘż┐┼└ż¼µ£öüźóĪ╝źŁźŲź»ź┴źŃż╬Įj(lu©░)żŁż╩ź▌źżź¾ź╚żŪżóżļż╚╚ÓżķżŽ╝ń─źżĘż┐ĪŻźŪĪ╝ź┐ż¼╠®ĮĖż╣żļż│ż╚ż“╦╔ż░ż┐żßż╦Īó═┐¶ż╬Ū█┐«ż╚│žØ{/╝┬╣įż╬źŪĪ╝ź┐┴„┐«ż╬źčź╣ż“┤░µ£ż╦Ų╚╬®żĄż╗żļźóĪ╝źŁźŲź»ź┴źŃż¼żĮż╬ŲŌ═Ųż└ĪŻ
Ī╩ź”Ī╦±T▓╠Ī¦└Łē”
╚ÓżķżŽCDBN (Convolutional Deep Brief Network:╗▓╣═½@╬┴80)ź═ź├ź╚źŌźŪźļżŪż╬ČĄ╗š╠ĄżĘ│žØ{ż“32Ī▀32 RGB Š}Ę┴ėXż╬Ū¦╝▒ż╦┼¼├ōżĘż┐ĪŻLSIż╚żĘżŲż╬└Łē”ż“┐▐34ż╬╔Įż╦┐āżĘż┐ĪŻ│žØ{żŪż╬źįĪ╝ź»└Łē”żŽ328.3 GOPSż╚ż½ż╩żĻ╣ŌżżĪŻżĮż╬±T▓╠ż╚żĘżŲ1.93 TOPS/Wż╚żżż”ż│żņżŌ╣Ōżżź©ź═źļź«Ī╝Ė·╬©├═ż“ųÖżŁĮążĘżŲżżżļĪŻ╚µ│ėż“ż╣żļ╩¾╣ż¼ż█ż½ż╦¾Hż»ż╩żżż│ż╚Īóż▐ż┐éb╩ĖżŪ└Łē”ż╦┤žżĘżŲ└LĀCż“¾Hż»│õżżżŲżżż╩żżż│ż╚ż½żķ1.93 TOPS/Wż╬╬╔żĘĄKżĘż“╚Įéāż╣żļż╬żŽžMżĘżżż¼Īóż½ż╩żĻż╬└Łē”ż╦żŽĖ½ż©żļĪŻż╩ż¬Īó╝┬╣įĪ╩DIĪ¦Deep InferenceĪ╦żŪżŽ3.1£IżŪĮęż┘ż┐╩┬š`ĮĶ═²ż╦▓├ż©żŲĪóź┐ź╣ź»źņź┘źļĪó┴žĪ╩LayerĪ╦źņź┘źļżŪż╬╩┬š`ĮĶ═²ż“▓├ż©żŲ╣ŌÅ]▓ĮżĘż┐ĪŻ
įćĮĖÅRĪ╦╝å└źĢ■ż╬ĖĮ║▀ż╬Ė¬Į±żŽĪóĒ×ķL╠OĮj(lu©░)│ž Įj(lu©░)│ž▒ĪŠ╩¾▓╩│žĖ”ē|▓╩ │žĮčĖ”ē|µ^żŪżóżļĪŻ

