ź╦źÕĪ╝źĒź┴ź├źū▄ć└ŌĪĪĪ┴żżżĶżżżĶ╚ŠŲ│öüż╬Įą╚ų(5-2)
ż│ż│żŪżŽĪóGoogLeNetżõResNetż╬╬╔żż┼└ż“ŲDżĻ╣■ż¾ż└ĪóSqueeze Netż╚Ō}żųźĘź¾źūźļż╩źŌźŪźļż╦ż─żżżŲĖĪŲżżĘżŲżżżļĪŻżĮż╬░ĄĮ╠Č\Įčż╦┼¼├ōżĘż┐±T▓╠żŌŠę▓żĘżŲżżżļĪŻĪ╩ź╗ź▀ź│ź¾ź▌Ī╝ź┐źļįćĮĖ╝╝Ī╦
├°ŪvĪ¦ĖĄ╚ŠŲ│öü═²╣®│žĖ”ē|ź╗ź¾ź┐Ī╝Ī╩STARCĪ╦/ĖĄ┼ņėøĪĪ╝å└źĪĪĘ╝
5.2ĪĪē|Č╦ż╬ųeżžĪ╩▐k─Ļż╬źņź┘źļżžĪ╦Ī┴źĘź¾źūźļż╩źŌźŪźļżžż╬┼¼├ōż╚NMTżžż╬·t│½
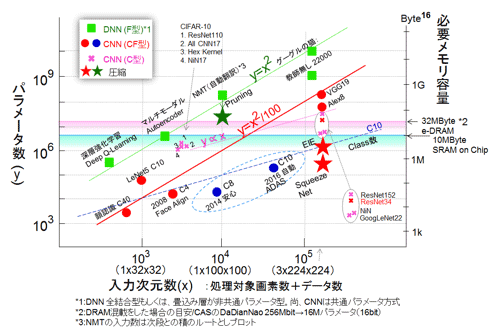
ż│ż╬┤¾ąMż¼ÅS══ż╬ų`ż╦┐©żņżļ║óż╦żŽĪóImageNet/ISLVRC2016żõNIPS2016żŌĮ¬╬╗żĘżŲżżżļż╚╣═ż©żļĪŻżĮż╬╗■ż╦ż╔ż╬żĶż”ż╦ź═ź├ź╚ź’Ī╝ź»źŌźŪźļż¼┐╩▓ĮżĘżŲżżżļż╬ż½Ążż╦ż╩żļż╚ż│żĒżŪżŽżóżļĪŻGoogLeNetż╩żĻResNetż“▒█ż©żļ┐ʿʿż╣═ż©öĄż¼żóżļż╬ż└żĒż”ż½ĪŻ╦▄£IżŪżŽĪóź═ź├ź╚ź’Ī╝ź»źŌźŪźļżĄżķż╦░ĄĮ╠Č\ĮčżŌżóżļ▐k─Ļźņź┘źļż╬Ę┴ż╦ż▐ż╚ż▐żĻż─ż─żóżļĪ╩ź┐źżź╚źļż╦żŽē|Č╦ż╚Ų■żņż┐ż¼Ī╦ż╚ż╬Ū¦╝▒ż╬ĖĄż╦ĪóĖĮėXż╬Č\Įčż╬╣Łż¼żĻż“▄ććĶżĘżŲż¬ż»ĪŻ ż▐ż║ĪóźĘź¾źūźļż╩Squeeze Netż“Šę▓żĘĪóżĮż│żžż╬░ĄĮ╠Č\Įč┼¼├ō±T▓╠ż“Šę▓ż╣żļĪŻ║ŪĖÕż╦ĪóNMTĪ╩ź╦źÕĪ╝źķźļĄĪ│Ż╦▌ŚlĪ╦żžż╬┼¼├ōż╬ėXČĘż“Įęż┘żļĪŻ
(1)ż▐ż╚ż▐ż├żŲżŁż┐ź═ź├ź╚ź’Ī╝ź»źŌźŪźļĪ╩Squeeze NetĪ╦
ŗī2ŠŽżŪ┐©żņż┐ż¼2016ŃQż╬2ĘŅż╦Arxivż╦╚»╔ĮżĄżņż┐Squeeze Netż╦┤žżĘŠę▓żĘżŲż¬ż»Ī╩╗▓╣═½@╬┴50Ī╦ĪŻ├°ŪvżŽUC Berkeleyż╬F. N. IandolaĢ■żŪżóżļĪŻDeep Compressionż╬│½╚»źĻĪ╝ź└ż╬ź╣ź┐ź¾źšź®Ī╝ź╔Įj│žż╬S. H. HanĢ■żŌČ”Ų▒╝╣╔«ŪvżŪżóżļĪŻF. N. IandolaĢ■żŽAIźėźĖź═ź╣ż“╣įż”DeepScale╝ęĪ╩╗▓╣═½@╬┴112Ī╦ż╬╝┬Č╚żŌ╣įż├żŲżżżļĪŻżĮż╬┼└ż½żķČ\ĮčŲŌ═Ųż╦Č╦żßżŲ╝┬ē»┼¬ż╩░§ō■ż“£pż▒ż┐ĪŻź¬źĻź¾źįź├ź»ĄķżŽ┴└ż├żŲżżż╩żżĪŻ▓ĶćĄŪ¦╝▒ż╬╗@┼┘ż╬ź┐Ī╝ź▓ź├ź╚ż“ź░ź├ż╚═Ņż╚żĘżŲAlexNet┼÷╗■ż╬źņź┘źļĪ╩80Ī┴85%ż╬╗@┼┘Ī╦ż╦żĘżŲżżżļĪŻĄšż╦Ė·╬©żĶż»ż’ż½żĻżõż╣ż»┴╚ż▀æųż▓Īó┴Ó║ŅżĘżõż╣ż»żĘżŲżżżļż╬ż¼ØŖ─¦ż└ĪŻ
Squeeze Netż╚ć@Øiż“¤²ż▒żŲżżżļż¼Īó├°ŪvżŌĮęż┘żŲżżżļżĶż”ż╦NINĪ╩Network in NetworkĪ╦ĪóGoogLeNetĪ󿥿ķż╦żŽResNetĪ╩╗▓╣═½@╬┴26, 27, 28Ī╦ż╬Č\Įčż╬╬╔żż┼└ż“├▒ĮŃż╦ŲDżĻ╣■ż¾żŪżżżļĪŻż┐ż└żĘĪóżĮżņżķż“æųövżļż│ż╚ż╦żóż▐żĻ┤ž┐┤żŽż╩żżżĶż”ż└ĪŻCNNż╬C0Ę┐ż╬╣Į└«ż└ĪŻ▓ĶćĄŪ¦╝▒ż“ź┐Ī╝ź▓ź├ź╚ż╚żĘżŲź▀ź├ź╔źņź¾źĖż╬╗@┼┘żŪĪó║ŪżŌ╣ŌĖ·╬©Ī╩źĄźżź║ż╚╗@┼┘Ī╦ż“ų`╗žżĘżŲżżżļĪŻ
╗▓╣═½@╬┴ż“ź┘Ī╝ź╣ż╦┐▐50ż“║Ņ└«żĘż┐ĪŻ║ĖŖõż╦Squeeze Netż╬źŌźŪźļµ£Ę╩ż“┐āżĘż┐ĪŻ▓½┐¦żŽøQ╣■ż▀┴žĪó┐Õ┐¦żŽMax Pooling┴ž(1/4)żŪżóżļĪŻźįź¾ź»┐¦ż╬ŗ╩¼ż¼│╦┐┤ż╚ż╩żļFire ModuleżŪżóżļĪŻ╣ń╝Ŗ8źŌźĖźÕĪ╝źļŲ■ż├żŲżżżļĪŻFire Moduleż╬├µ┐╚żŽīÜ┐▐ż╦·t│½żĘżŲżżżļżĶż”ż╦Īó3ż─ż╬źįź¾ź»┐¦ż╬øQ╣■ż▀┴žż½żķĘ┴└«żĄżņżŲżżżļĪŻ1Ī▀1ż╬Squeeze┴žż╚Īó1Ī▀1ż╚3Ī▀3ż¼╩┬š`ż╦╩┬żųExpand┴žż½żķż╩żļĪŻ┐¶├═żŽź┴źŃź¾ź═źļ┐¶Ī╩ØŖ─¦ź▐ź├źū┐¶Ī╦ż└ĪŻ═ŠÕiż└ż¼ĪóC0Ę┐żŽźšźŻźļź┐ż└ż▒ż¼£½┐ā┼¬ż╦Į±ż½żņżļż╬ż¼║“║Żż╬╬«żņżŪżóżļĪŻź▐ź├źūż╬źĄźżź║żŽĪóPooling┴žż╬░╠Åøż“ż▀żŲ═Ų░ūż╦╚ĮéāżŪżŁżļĪŻ
Fire Moduleż╬ĘQźųźĒź├ź»ż╬Ų»żŁż“╣═ż©żļ╗■ż╦ĪóżĮżŌżĮżŌźšźŻźļź┐ż╚żŽ▓┐ż½żŪżóżļż¼Īó1Ī▀1żŪżŽŠ╩¾ż“øQż▀╣■ż¾żŪżµż»╬üżŽ╦▄═Ķż╩żżĪŻ╝ń╠“żŽ3Ī▀3ż╬źšźŻźļź┐ż└ĪŻż└ż¼3Ī▀3ż╬źšźŻźļź┐żŪżŌŲ■╬ü96ź┴źŃź¾ź═źļĪ╩Ų■╬üż╬ØŖ─¦ź▐ź├źū┐¶Ī╦ż“─Š└▄Ų■żņżļż╚Ū³Įjż╩─_ż▀ż╬┐¶ż¼ĪóżĮżĘżŲ╝ŖōQ╬╠ż¼¾Hż»ż╩żļĪŻżĮż│żŪĪóØi├╩ż╦Squeeze┴žż╚Š╬żĘżŲ1Ī▀1ż“ÅøżŁź┴źŃź═źļ┐¶ż“╣╩żĻĪ╩SqueezeĪ╦ĪóżĮżĘżŲExpand┴žż╬ŲŌŗż╦żŽ╩┬š`ż╦1Ī▀1ż“ÅøżŁ3Ī▀3ż“ż¼ż├ż┴żĻź¼Ī╝ź╔Ī╩╝┬ä®┼¬ż╦ź┴źŃź═źļ┐¶ż“└▐╚ŠĪ╦żĘżŲāį┼┘ż╬źšźŻźļź┐║ŅČ╚Ī╩Č╦╬üź┴źŃź¾ź═źļ┐¶ż“▓╝ż▓żļĪ╦ż“żĄż╗ż╩żżżĶż”ż╦żĘżŲżżżļĪŻż╩ż¬ĪóČ\╣¬┼¬ż╦żŽĪóSqueeze┴žż╬1Ī▀1żŽNIN (Network in Network)ż╬Bottleneck┴žż╚µ£ż»Ų▒żĖż└ĪŻ
żĮżĘżŲżĖż’żĖż’ż╚1000ź┴źŃź¾ź═źļ(ź┴źŃź¾ź═źļ┐¶ż¼╗┼╩¼ż▒żļź»źķź╣┐¶)ż▐żŪż╬│¼├╩ż“æųżļĪŻ┴ž┐¶ż╚╔į╬╔╬©żŽĪóSqueeze NetżŽ18┴žżŪ15.3%ż╬╔į╬╔╬©ĪóGoogLeNetżŽ22┴ž6.7%ĪóResNetżŽ34┴ž3.57%ż╚ż╩żļĪŻŠåżżżŪ1000├╩ż╬│¼├╩ż“æųżļż╚ē”╬ü░╩æųż╦źĖźŃź¾źūż╣żļż│ż╚ż½żķ╔į╬╔╬©żŌæųż¼żļĪŻżµż├ż»żĻ┼ążņżąĪóŲDżĻż│ż▄żĘżŌŠ»ż╩żżĪŻżżż½ż╦żµż├ż»żĻ┼ążņżļż½ż¼╗@┼┘źóź├źūż╬ź▌źżź¾ź╚ż└ĪŻ
Squeeze NetĪ╩┬Šż╬NetżŌ┤╦▄żŽż½ż╩żĻŲ▒żĖż└Ī╦ż╬ĖČ═²żŽ░╩æųżŪżóżļĪŻż┐ż└żĘĪóSqueeze┴žż╬╣╩żĻż│ż▀ż¼żŁż─żżż╚Š╩¾ż¼╝Ī├╩ż╦┼┴ż’żķż╩żżĪŻżĮż╬×┤║÷ż╚żĘżŲ┼ąŠņżĘż┐ż╬ż¼┐▐50ż╦żŽĄŁ║▄żĘżŲżżż╩żżż¼źĘźńĪ╝ź╚ź½ź├ź╚źļĪ╝źūż└ĪŻŠ╩¾ż“└Ķż╦źĻĪ╝ź»żĘ┼┴├Żż╣żļĪŻźąźżźčź╣ż“żŌż─ResNetż╬źĘźńĪ╝ź╚ź½ź├ź╚źļĪ╝źūż╬ż│ż╚ż└ĪŻż╩ż¬ż│ż╬Squeezeź═ź├ź╚ż╦Ė┬żķż║µ£╚╠┼¬ż╦═²éb┼¬ż╩└Ō£½żŽżóż▐żĻż╩żżĪŻ
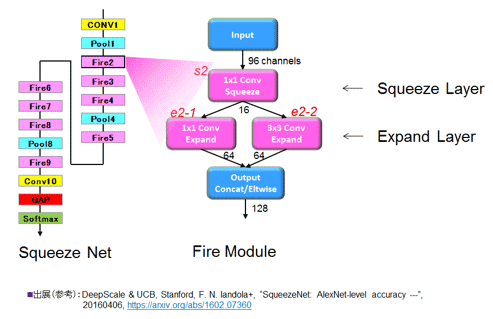
┐▐50ĪĪSqueeze Netµ£Ę╩ż╚ĪóFire Moduleż╬ŲŌŗ╣Į└« Ī╩╗▓╣═½@╬┴50ż“╗▓╣═ż╦║Ņ└«Ī╦
╔Į8ż╦ź═ź├ź╚ż“╣Į└«ż╣żļŲ■╬üźĄźżź║Īóź▐ź├źū┐¶ĪóźšźŻźļź┐źĄźżź║ĪóĮą╬üźĄźżź║Īóź▐ź├źū┐¶ż“Īóż▐ż┐ź╦źÕĪ╝źĒź¾┐¶Īó└▄¶ö┐¶ż“ĘQ┴žż┤ż╚ż╦╝ŖōQżĘ▐k═„ż╚żĘż┐╔Įż“╗▓╣═ż╚żĘżŲ┐āżĘż┐Ī╩╔«Ūvż¼╝ŖōQż“ź╚źņĪ╝ź╣żĘż┐Ī╦ĪŻźĄźżź║┼¬ż╦żŽĪó18┴žĪó1.3MĖ──_ż▀Īó8.4▓»övMAC▒ķōQĪó15.3%ź©źķĪ╝╬©ż└ĪŻ╣Įļ]ż╚żĘżŲŖZżżGoogLeNet22ż╬├═ż“┐āż╣ż╚Īó22┴žĪó7MĖ──_ż▀Īó15▓»övMACĪó6.66%ż╚ż╩żļĪŻSqueeze NetżŽźčźķźßĪ╝ź┐┐¶ż¼1/5żŪĪóżõżŽżĻź▀ź├ź╔źņź¾źĖź»źķź╣ż└ĪŻ
╔Į8żŪFire2źŌźĖźÕĪ╝źļż╬ż▀ŲŌŗż“£½┐āżĘżŲżóżĻĪóSqueeze Layer S2ĪóExpand Layer e2-1ż╚e2-2ż╬├═ż¼Ė½ż©żļżĶż”ż╦żĘżŲżóżļĪŻ┬Šż╬źŌźĖźÕĪ╝źļżŽźŌźĖźÕĪ╝źļż╬Ž┬ż╚żĘżŲ├═ż“┐āżĘż┐ĪŻż╩ż¬Īóéb╩ĖżŪżŽĘQźčźķźßĪ╝ź┐ż╬┤Č┼┘Ī╩sensitivityĪ╦żŌäh▓┴żĘżŲż¬żĻĪóŃæųtżŪż½ż─ż½ż╩żĻ─Š┤Č┼¬ż╦Ų╔żßżļż╬żŪ▐kŲ╔ż“ż¬é„żßż╣żļĪŻ
╔Į8 Squeeze Netż╦AlexNetźŌźŪźļż“┼¼├ōżĘż┐║▌ż╬ĘQ┴žż╬źčźķźßĪ╝ź┐▐k═„
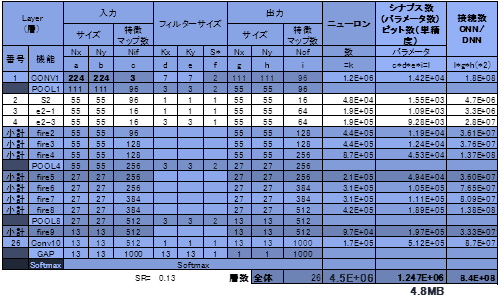
(2)░ĄĮ╠Č\Įčż“┼¼├ōż╣żļĪ┴øQ╣■ż▀┴žż└ż▒ż└ż¼Ī┴
╔Į9ż╦ĪóIandolaĢ■żķż¼Squeeze Netż╦Pruningż╚ź»źķź╣ź┐źĻź¾ź░(╬╠╗ę▓Į)ż“┼¼├ōżĘż┐║▌ż╬źčźķźßĪ╝ź┐┐¶ż╬╩č▓Įż╚Īóź┘ź¾ź┴ź▐Ī╝ź»ż╬Imagenet/ILSVRCż╬Top1ż╚Top5ż╬╗@┼┘ż╬├═ż“┼Š║▄żĘĪóŠ╩¾ż“▓├ż©żŲ╚µ│ė╔Įż╦żĘż┐ĪŻ║Ūæų├╩ż╬├═57.2%ż╚80.3%ż¼ź┘Ī╝ź╣ż╬├═ż└Ī╩ź┘ź╣ź╚ż╬├═żŪżŽż╩żżĪ╦ĪŻAlexNetż╦░ĄĮ╠Č\Įčż“┼¼├ōżĘż┐Šņ╣ńż╚ĪóSqueeze Netż╦┼¼├ōżĘż┐Šņ╣ńż╬░ĄĮ╠╬©ż╚Īó╗@┼┘ż╬╩č▓Įż“┐āżĘż┐ĪŻ╗@┼┘ż╬╩č▓ĮĪ╩╬¶▓ĮĪ╦żŽMaxżŪ0.3%ż╚Č╦żßżŲŠ«żĄżżĪŻ▐köĄĪó░ĄĮ╠╬©żŽAlexNetżŪ35Ū▄Ī╩ż│żņżŽ4.3£IżŪŠę▓żĘż┐├═ż╚Ų▒żĖĪ╦ż╦×┤żĘżŲSqueeze NetżŪżŽ10Ū▄żĘż½░ĄĮ╠żĄżņżŲżżż╩żżĪŻAlexNetżŽµ£±T╣ń┴žż“Ęeż┴ĪóżĮż╬░ĄĮ╠╬©ż¼ĮjżŁżżż½żķżŪżóżļĪŻż▐ż╚żßżļż╚Īóź═ź├ź╚ź’Ī╝ź»źŌźŪźļż╬Ė·╬©▓ĮżŪ50Ū▄Īó░ĄĮ╠Č\ĮčżŪ10Ū▄ż╬Ė·▓╠ż¼żóżĻĪó×┤AlexNet╚µ500Ū▄ż╬▓■║¤ż¼ż╩żĄżņż┐ż│ż╚ż╦ż╩żļż╚żżż”ż╬ż¼╚Óżķż╬±T▓╠żŪżóżļĪŻźßźŌźĻ═Ų╬╠żŪżŽĪó0.47MBż╚Č╦żßżŲŠ«żĄż»Īó═Ų░ūż╦SRAMź¬ź¾ź┴ź├źū▓Įż¼▓─ē”ż└ĪŻ
╔Į9ĪĪSqueezeNetż╚AlexNetż╚ż╬╚µ│ėż╚░ĄĮ╠Č\Įč┼¼├ōż╬±T▓╠
╗▓╣═½@╬┴50ż“╗▓╣═ż╦║Ņ└«
(3)░ĄĮ╠Č\Įčż╬śOŲ░╦▌ŚlĪ╩NMTĪ¦Neural Machine TranslationĪ╦żžż╬┼¼├ō
┐▐51ż╦StanfordĮj│žż╬Abigail SeeĢ■żķż¼╚»╔ĮżĘżŲżżżļNMTĪ╩╗▓╣═½@╬┴72, 73Ī╦źŌźŪźļż╬źóĪ╝źŁźŲź»ź┴źŃż“┐āżĘż┐Ī╩½@╬┴ż“╗▓╣═ż╦║Ņ└«Ī╦ĪŻźŌźąźżźļżžż╬┼ļ║▄ż“ź┐Ī╝ź▓ź├ź╚ż╚żĘĪóPruningČ\Įčż╬┼¼├ōż“ĖĪŲżżĘż┐ĪŻ╝┬äóż╬ĖĪŲżżŽżĘżŲżżż╩żżĪŻ▒čĖņż½żķźšźķź¾ź╣Ėņżžż╬ĄĪ│Ż╦▌ŚlżŪżóżļĪŻ╚Óųöżķż╬╬ŃżŪżŽ5╦³Ė─ż╚żżż”▒čĖņż╬├▒ĖņĪ╩ź▄źŁźŃźųźķźĻĪ╝┐¶Ī¦ź’ź¾ź█ź├ź╚ź┘ź»ź╚źļĪ╦ż“╗■ÅUš`┼¬ż╦╩¼Üg╔ĮĖĮĪ╩word embeddingsĪ¦├▒Ėņ┤ųż╬┤žŽó└Ł1000╝ĪĖĄ(n)ż╬ź┘ź»ź╚źļżŪ╔ĮĖĮĪ╦ż╣żļĪŻŲ▒╗■ż╦×┤ż╚ż╩żļźšźķź¾ź╣Ėņż╦żŌŲ▒══ż╬╔ĮĖĮż“╗▄żĘĪó╬ŠĖ└Ėņż╬░°▓╠┤žĘĖż“ż─ż▒│žØ{Ī╩ČĄ╗šŃ~żĻĪ╦ż╣żļĪŻźĮĪ╝ź╣ŖõĪ╩ź©ź¾ź│Ī╝ź└ŖõĪ¦▒čĖņĪ╦ż╚ź┐Ī╝ź▓ź├ź╚ŖõĪ╩źŪź│Ī╝ź└ŖõĪ¦źšźķź¾ź╣ĖņĪ╦ż“▓Żż╦└čż▀─_ż═ż┐2─_ż╬RNN (2Stacked RNN) ╣Į└«żŪżóżļĪŻ
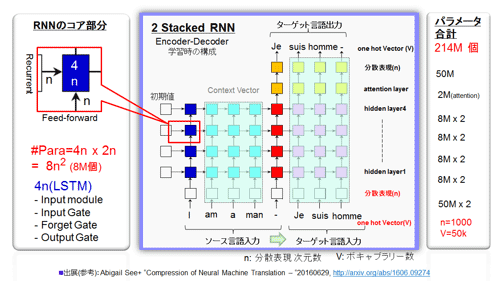
┐▐51ĪĪ2 Stacked RNN (LSTM) ╣Į└«ż½żķż╩żļNMTźŌźŪźļ Ī╩╗▓╣═½@╬┴72Īó73ż“╗▓╣═ż╦║Ņ└«Ī╦
(źó) źŌźŪźļż╬╣Į└«
│žØ{ż╬║▌ż╦żŽĪóŲ■╬üŖõżĶżĻ╩ĖŠŽĪ╩SentenceĪ¦I am a manż╚ĪóJe suis hommeĪ╦ż“Ų■╬üżĘĪóź┐Ī╝ź▓ź├ź╚Ė└ĖņĮą╬üĪ╩æųŖõĪ╦żŪż╬ĖĒ║╣Ī╩Je suis hommeż╚ż╬║╣Ī╦ż“ĖĒ║╣Ąš┼┴ś“╦ĪżŪźšźŻĪ╝ź╔źąź├ź»ż╣żļĪŻµ£żŲµ£±T╣ńżŪżóżļĪŻ
āeöĄĖ■ż╬┴ž╣Į└«Ī╩FeedforwardŖõĪ╦żŽĪó║ŪĮķż╦├▒ĖņĪ╩ź▄źŁźŃźųźķźĻĪ╝Ī╦ż“╩¼Üg╔ĮĖĮż╦╩č┤╣ż╣żļĮĶ═²┴žż¼żóżļĪŻV=50kż╚n=1000ż╬µ£±T╣ń┴žż╦żĶżĻ╩č┤╣żĄżņżļĪŻ5╦³╝ĪĖĄż½żķ1000╝ĪĖĄżžż╚░ĄĮ╠żĄżņż┐ĖÕż╦Īó╗■ÅUš`┼¬ż╬RNNż╦Ų■żļĪŻ╚Óųöż╬╣Į└«żŽāeöĄĖ■4┴žż╬▒Żżņ┴žĪ╩hidden layerĪ╦ż“żŌż─ĪŻ1000╝ĪĖĄżŪæų┴žż╦Ęęż¼żļĪŻ▒Żżņ┴žż╬æųŖõż╦żŽĪóAttention┴žĪ╩└Ō£½Š╩ŠSĪ╦ż╚╩¼Üg╔ĮĖĮż½żķ├▒Ėņż╦╠ßż╣┴žĪ╩50kĪ▀1kĪ╦ż¼żóżļĪŻ║Ūæų┴žż╦żŽ─_ż▀ż╬ż╩żżSoftmax┴žż¼żóżĻĪóµ£├▒ĖņĪ╩ź▄źŁźŃźųźķźĻĪ╦ż╬│╬╬©ż“Įą╬üż╣żļĪŻ
▓ŻöĄĖ■ż╬┴ž╣Į└«Ī╩RecurrentŖõĪ╦żŽĪóźĮĪ╝ź╣Ŗõż╬ŗī▐kš`Ī╩▒čĖņż╬IĪ╦ż¼żóżĻĪóżĮż╬ĖÕż╦╝Īż╬╗■╣’ż╦═ĶżļŗīŲ¾š`Ī╩▒čĖņż╬amĪ╦ż¼═ĶżļĪŻ"am"żŽ"I"ż╚ż╬┤žŽóĪ╩╬Ńż©żą╩Ė╦ĪĪ╦ż¼żóżļż╬żŪĪó▓ŻöĄĖ■ż╬Recurrentż╬źčź╣ż“£pż▒żļĪŻżĄżķż╦īÜŖõż╦═ĶżŲĪóźŪź│Ī╝ź└Ī╝Ŗõż╦żųż─ż½żĻźšźķź¾ź╣ĖņŖõżŪż╬╗■ÅUš`ż╬ĮĶ═²ż“╣įż”ĪŻ╝┬║▌ż╦żŽĪó┐▐ż╬źĮĪ╝ź╣Ė└ĖņŖõż╬║ĖŖõĪ╩║░┐¦ż╬š`Ī╦ż╬š`ż╚ź┐Ī╝ź▓ź├ź╚Ė└ĖņŖõż╬║ĖŖõż╬š`Ī╩śĘ┐¦ż╬š`Ī╦ż¼╝┬║▀żĘĪó╗■ÅUš`┼¬ż╦▓Š„[źóźņźżż“╣Į└«żĘ┐▐ż╬══ż╩Ę┴ż╦ż╩żļĪŻ
ź│źóŗ╩¼żŽLSTM (Long Short-Term Memory) ż½żķż╩żļĪŻ╝ĪĖĄżŽæų▓╝║ĖīÜČ”ż╦n(=1000)ż└ĪŻżĶż├żŲ4nż╬╝ĪĖĄż╚ż╩żļĪŻŲ■╬üżŽāeŖõż╬FeedforwardŖõż¼Ų▒żĖż»n(=1000)Īó▓ŻöĄĖ■ż╬RecurrentŖõż¼n(=1000)ż╚ż╩żĻĪóź│źóżŪż╬źčźķźßĪ╝ź┐┐¶żŽ4nĪ▀2n =8nĪ▀n (n=1000) ż╚ż╩żļż│ż╚ż½żķĪóź│źó┼÷ż┐żĻ8MĖ─Ęeż─ż│ż╚ż╦ż╩żļĪŻ
(źż) źčźķźßĪ╝ź┐┐¶
┐▐51ż╬īÜŖõż╦ĘQ┴žż╬źčźķźßĪ╝ź┐ż“ĄŁ║▄żĘż┐ĪŻ╗■ÅUš`·t│½ż╬▓Š„[╩¼żŽ┤▐ż▐ż╩żżĪŻ▓╝Ŗõż╬╩¼Üg╔ĮĖĮż¬żĶżė▒Żżņ┴žĪ╩µ£ŗżŪ4┴žĪ╦ż╬ŗ╩¼żŽźĮĪ╝ź╣ż╚ź┐Ī╝ź▓ź├ź╚żŪ2Ū▄ż╚ż╩żļĪŻ╣ń╝ŖżŽ216MĖ─(éb╩ĖżŪżŽ214MĖ─ż└ż¼╝ŖōQź▀ź╣ż½żŌżĘżņż╩żż)ż╚ż╩żļĪŻ╩¼Üg╔ĮĖĮżžż╬╔õęÄ▓Įż╚Ąš╔õęÄ▓Įż╬╣ń╝Ŗ150MĖ─ż¼µ£öüż╬75%ż“žéżßżļĪŻż╣ż╩ż’ż┴µ£±T╣ńż╬└U╠┐żŪżóżļż¼ź▄źŁźŃźųźķźĻż╬┐¶ż╦äėż»░═┘Tż╣żļĪŻ┐▐52ż╦NMT (śOŲ░╦▌Śl) ż╬ź▌źżź¾ź╚ż“╝{▓├żĘż┐ĪŻż╩ż¬Īóż│ż╬NMTż╦Ė┬żĻŲ■╬ü╝ĪĖĄ┐¶żŽŲ■╬üż╚Įķ├╩ż╬┴žż╬źļĪ╝ź╚╩┐ČčĪ╩10ż╬4ŠĶĪ╦ż╚żĘż┐ĪŻ
┐▐52 ź═ź├ź╚ź’Ī╝ź»źŌźŪźļż╚źčźķźßĪ╝ź┐┐¶Ī╩źßźŌźĻ═Ų╬╠Ī╦ż╚ż╬┤žĘĖĪ╩░ĄĮ╠źŌźŪźļż“╝{▓├Ī╦
(źó) ░ĄĮ╠Ī╩PruningĪ╦Č\Įčż╬┼¼├ō
Deep Compressionż╬HanĢ■żķż╚Ų▒══ż╦ĪóTraining - Pruning - Retrainingż╬Š}Įńż“║╬├ōżĘżŲżżżļĪŻż▐ż┐PruningżŽµ£źčźķźßĪ╝ź┐ż“Š«żĄżżĮńż╦╩┬ż┘ĪóżĘżŁżż├═żŪź½ź├ź╚żĘżŲżżżļĪŻżĮż╬±T▓╠Īó└Łē”ż“═Ņż╚żĄż║ż╦źčźķźßĪ╝ź┐ż“20%ż▐żŪ░ĄĮ╠ż╣żļż│ż╚ż¼▓─ē”ż└ż├ż┐ĪŻ214MĖ─ż¼42MĖ─ż╦░ĄĮ╠żĄżņż┐Ī╩╗▓╣═½@╬┴72żŪżŽź╣ź╚Ī╝źņźĖ╬╠żŪż╬ĄŁ║▄ż¼żóżļż¼Īó╦▄┤¾ąMżŪżŽźčźķźßĪ╝ź┐┐¶ż“╗╚├ōżĘż┐Ī╦ĪŻ┐▐52ż╦NMTż╬░ĄĮ╠ĖÕż╬├═ż“£uż╬└▒Ī·żŪźūźĒź├ź╚żĘż┐ĪŻAlexNetż╬62MĖ─ż╦×┤żĘżŲżŽŠ»ż╩żżż¼Īó░═─śż½ż╩żĻż╬╬╠żŪżóżļĪŻŲ▒══ż╦ĪóEIEż╚Squeeze Netż╬░ĄĮ╠ĖÕż╬├═żŌśĘżżĪ·żŪ╝{▓├żĘż┐ĪŻ
ĄĪ│Ż╦▌Ślż╬╗@┼┘ż╬╬¶▓ĮżŌż╩ż»Īó─_ż▀┐¶42MĖ─ż╚źßźŌźĻż“ź¬ź¾ź┴ź├źū▓─ē”ż╩źņź┘źļż▐żŪżŌż”▐k╩Ōż╚żżż”░§ō■żŪżóżļĪŻ▓ĶćĄŪ¦╝▒ż╦¶öżŁĪó╝┬żŽĖ└Ėņż“░Ęż”ż│ż╚ż½żķžM░ū┼┘ż¼╣ŌżżĄĪ│Ż╦▌ŚlĪ╩GNMT: Google Neural Machine Translationż╬╩¾╣Ī╩╗▓╣═½@╬┴99, 100Ī╦┤▐żßĪ╦żõĪóŲ▒¹|ż╬▓╗╠mŪ¦╝▒ż“źŲĪ╝ź▐ż╚żĘż┐LSI╝┬äóż╬ĖĪŲżż¼║ŻĖÕ▐k┴ž─_═ūż╚ż╩żļĪŻ
įćĮĖÅRĪ╦╝å└źĢ■ż╬ĖĮ║▀ż╬Ė¬Į±żŽĪóĒ×ķL╠OĮj│ž Įj│ž▒ĪŠ╩¾▓╩│žĖ”ē|▓╩ │žĮčĖ”ē|µ^żŪżóżļĪŻ

