ź©ź├źĖAIż╬└Łē”ż╚┼┼╬üĖ·╬©ż“Č”ż╦æųż▓ż┐Cadenceż╬AIź│źó
CadenceżŽĪóźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░Ė■ż▒ż╦ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»▒ķōQż“╣įż”IPź│źóż╦ż¬żżżŲĪóĖ·╬©żĶż»źŪĪ╝ź┐żõ─_ż▀ż“┤ų░·ż»ż│ż╚żŪĪó“£═Ķż╚Ų▒żĖ4000Ė─ż╬MAC▒ķōQźµź╦ź├ź╚żŪ╚µż┘żļż╚Īó└Łē”żŽ║ŪĮj4.7Ū▄ĪŻ┼┼╬üĖ·╬©żŽ2.3Ū▄ż╚żżż”AIź│źóż“│½╚»żĘż┐ĪŻ2018ŃQ¼Źż╦żŽØŖ─ĻĖ▄ĄęĖ■ż▒ż╦Ö┌ŠÅż¼╗Žż▐żļĪŻPublitek╝ń╠¢ż╬źßźŪźŻźóźżź┘ź¾ź╚żŪ£½żķż½ż╦żĘż┐ĪŻ
CadenceżŽĪóDSPź│źóżŪ─Ļähż╬żóż├ż┐Tensilicaż“2013ŃQ4ĘŅż╦āA╝²Īó░╩═ĶTensilicaż╬IPż“×æēäź▌Ī╝ź╚źšź®źĻź¬ż╦▓├ż©ż┐ĪŻźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╦╗╚ż”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»żŽĪóź╦źÕĪ╝źĒź¾ż╬źŪĪ╝ź┐ż╚─_ż▀ż“²Xż▒ōQżĘ’BżĘ╣ńż’ż╗żļ└čŽ┬▒ķōQĪ╩MAC: Multiply AccumulateĪ╦ż“┤╦▄ż╚ż╣żļĪŻĖ·╬©żĶż»MAC▒ķōQż“╣įżżĪóżĘż½żŌĪóøQż▀╣■ż▀▒ķōQż╚źūĪ╝źĻź¾ź░▒ķōQżŪżŽ┤ų░·ż»ż│ż╚ż“┤╦▄ż╚ż╣żļĪŻżżż½ż╦┼┼╬üĖ·╬©ż“æųż▓żļż½ż╦IJ┼└ż¼╣╩żķżņżŲżżżļĪŻ│žØ{▒ķōQżŪ─Ļähż╬żóżļNvidiaż╬ź┴ź├źūż╬Š├õJ┼┼╬üżŽ200Wż╩ż╔ż╚ĮjżŁżżĪŻż│ż╬ż┐żßź»źķź”ź╔ź┘Ī╝ź╣żŪż╬│žØ{ż╦żŽĖ■ż»ż¼Īó├╝¼Źż╬żĶż”ż╩ź©ź├źĖżŪżŽż▐ż└£pż▒Ų■żņżķżņż╩żżĪŻ
żĮż│żŪĪóź©ź├źĖżŪż╬AIżŪżŽĪó┐õébż“ź┘Ī╝ź╣ż╦ż╣żļźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░▒ķōQż¼╝ńöüż╦Ēöż’żņżŲżżżļĪŻTensilicaż¼įu┴Tż╚żĘżŲżżżļDSPżŽĪóMAC▒ķōQ└ņ├ōż╬ź▐źżź»źĒźūźĒź╗ź├źĄżŪżóżļĪŻż┐ż└żĘż│żņż▐żŪż╬DSPżŽ32źėź├ź╚▒ķōQż“┤╦▄ż╚żĘżŲż¬żĻĪó64źėź├ź╚ż╬Ū▄╗@┼┘ż╦żŌ×┤▒■ż╣żļż╩ż╔Īó╣Ō╗@┼┘▓Įż“Į╝╝┬żĄż╗żŲżŁż┐ż┐żßĪóźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╦żŽĖ■ż½ż╩ż½ż├ż┐ĪŻżĮż│żŪźŪĪ╝ź┐żŌ─_ż▀żŌźėź├ź╚┐¶ż“▓╝ż▓Īó╠ĄŠGż╩▒ķōQż“ż╗ż║ż╦Š├õJ┼┼╬üż“▓╝ż▓żļAIĖ■ż▒ż╬DSPź│źóż¼¶öĮążĘżŲżżżļ(╗▓╣═½@╬┴1)ĪŻ

┐▐1ĪĪCadence╝ęTensilica IPŗ╠ń×æēäź▐ź═źĖźßź¾ź╚├┤┼÷źĘź╦źóźŪźŻźņź»ź┐ż╬Lazaar LouisĢ■
║ŻövĪóCadenceż¼│½╚»żĘż┐ĪóTensilica DNA 100źūźĒź╗ź├źĄIPżŽĪó4000Ė─ż╬MACż“╩┬ż┘ż┐IPź│źóżŪĪó8źėź├ź╚▒ķōQż“┤╦▄ż╦żĘż┐ż╚ĪóŲ▒╝ęTensilica IPŗ╠ń×æēäź▐ź═źĖźßź¾ź╚├┤┼÷źĘź╦źóźŪźŻźņź»ź┐ż╬Lazaar LouisĢ■(┐▐1)żŽĖņż├żŲżżżļĪŻDNAżŽDeep Neural Network Acceleratorż╬ŠSżŪżóżļĪŻ
▓├ż©żŲĪóDNA 100źūźĒź╗ź├źĄżŪżŽĪóź╣ź▒Ī╝źķźųźļż╩┤ų░·żŁ╝ŖōQź©ź¾źĖź¾Ī╩Sparse Compute EngineĪ╦ż╦żĶżĻĪóDNNĪ╩źŪźŻĪ╝źūź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»Ī╦żŪ┤ų░·ż»▒ķōQż“ŠW├ōżĘżŲĪóź╝źĒż╬ŠĶōQż╬żĶż”ż╩╔įØŁ═ūż╩ź┐ź╣ź»ż“ŪėĮ³żĘż┐ĪŻż│ż╬±T▓╠Īó┼┼╬üĖ·╬©ż“æųż▓Īó▒ķōQ╬╠ż“║’žōżŪżŁż┐ĪŻź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬║Ų│žØ{ż╦żĶż├żŲź═ź├ź╚ź’Ī╝ź»ż╬┤ų░·żŁ▒ķōQż“╗\żõż╣ż│ż╚ż╦żĶżĻĪóDNA 100źūźĒź╗ź├źĄż╬┤ų░·żŁ╝ŖōQź©ź¾źĖź¾żŪ└Łē”ż“║ŪĮjĖ┬ż╦æųż▓żļż│ż╚ż¼żŪżŁż┐ĪŻż│żņż╦żĶżĻĪóResNet 50ż╦ż¬żżżŲ4K MAC╣Į└«żŪż¬żĶżĮ║ŪĮj2,550fps (źšźņĪ╝źÓźņĪ╝ź╚)Īó║ŪĮj3.4TMAC/W (16 nmźūźĒź╗ź╣) ż╚żżż”┐õéb└Łē”ż¼╝┬Š┌żŪżŁĪóDNA 100źūźĒź╗ź├źĄżŽŠ«żĄżżźóźņźżźĄźżź║żŪź╣źļĪ╝źūź├ź╚ż“║ŪĮjż╦ż╣żļż│ż╚ż¼▓─ē”ż╚ż╩ż├ż┐ĪŻ
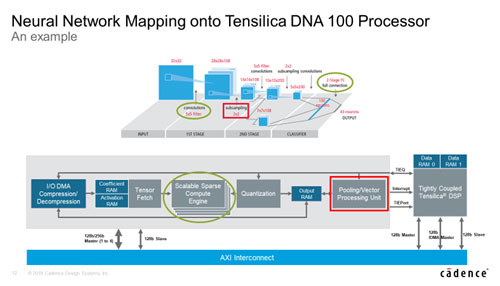
┐▐2ĪĪøQż▀╣■ż▀ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬║ŅČ╚ż“▐kż─ż╬źūźĒź╗ź├źĄIPżŪż│ż╩ż╣ĪĪĮąųZĪ¦Cadence
ż│ż╬DNA 100źūźĒź╗ź├źĄIPżŽĪóøQż▀╣■ż▀▒ķōQżŌĪóźūĪ╝źĻź¾ź░▒ķōQżŌĪó╩¼╬Ó╩¼ż▒żŌż│ż╬źūźĒź╗ź├źĄż“źļĪ╝źūż╬żĶż”ż╦╗╚ż”ż│ż╚żŪ(┐▐2)Īó╠ĄŠGż╬ż╩żż▒ķōQż“ż╣żļż│ż╚ż¼żŪżŁżļżĶż”ż╦ż╩ż├ż┐ĪŻźŪĪ╝ź┐ż╚─_ż▀▒ķōQż╬±T▓╠ż“RAMż╦╣ŌÅ]ż╦°Qżßż┐żĻĮążĘż┐żĻż╣żļż┐żßż╬128źėź├ź╚żóżļżżżŽ256źėź├ź╚źąź╣ż“─╠żĘżŲHBM2źßźŌźĻż“ż─ż╩ż░ż│ż╚ż¼żŪżŁżļĪŻż▐ż┐ĪóDNA 100źūźĒź╗ź├źĄżŽĪó│╚─ź└Łż¼żóżļż┐żßĪóČ”─╠źąź╣NoCż“─╠żĘżŲ╩┬š`ż╦└▄¶öż╣żļż│ż╚ż¼żŪżŁĪ󿥿ķż╦└Łē”ż“│╚─źż╣żļż│ż╚żŌ═Ų░ūż╦ż╩żļĪŻ
╝┬║▌ż╦żŽØ±═²┼¬ż╦4KĖ─ż╬MACż“╩┬ż┘Īó─_ż▀ż“35%┤ų░·żŁĪóźŪĪ╝ź┐ż“60%┤ų░·ż»ż│ż╚żŪ└Łē”ż“2.3Ū▄ż╦æųż▓żļż│ż╚ż¼żŪżŁżļż╚żĘżŲżżżļĪŻ16nmźūźĒź╗ź╣ż“╗╚ż├ż┐“£═Ķż╬DNNźūźĒź╗ź├źĄż¼1.5źŲźķMACs/WżŪżóżļż╬ż╦×┤żĘżŲĪó3.4źŲźķMACs/Wż¼įużķżņżŲżżżļĪŻ
║ŻövżŽCaffeźšźņĪ╝źÓź’Ī╝ź»ż“╗╚ż├ż┐ż¼Īó║ŻĖÕżŽTensorFlowżõCaffe2ż╩ż╔żŌźĄź▌Ī╝ź╚żĘżŲżżż»╝Ŗ▓ĶżŪĪó║Żövż╬8źėź├ź╚Ī”16źėź├ź╚ż╬╬╠╗ę▓Įż╦×┤żĘżŲĪó4źėź├ź╚żõźąźżź╩źĻż╩ż╔żŌĖĪŲżżĘżŲżżż»ż╚żĘżŲżżżļĪŻ
╗▓╣═½@╬┴
1. AIż╬└čŽ┬▒ķōQż╦Š«żĄż╩DSPż“┐¶╝åĖ─╩┬ż┘ż┐IPź│źóż¼¶öĪ╣┼ąŠņ (2018/07/06)

