16nm FinFETźūźĒź╗ź╣ż╬FPGAż“╬╠ŠÅżž
16nm FinFETźūźĒź╗ź╣ż¼żżżĶżżżĶFPGAż“Š}╗Žżßż╦╬╠ŠÅż¼╗Žż▐żļĪŻ║“ŃQĮą▓┘żĄżņż┐Intelż╬┐ʿʿżźūźĒź╗ź├źĄĪųBroadwellĪūż╦żŌ14nm FinFETźūźĒź╗ź╣ż¼╗╚ż’żņż┐ż¼ĪóÖ┌ŠÅ╣®Šņż¼źčźżźĒź├ź╚Ö┌ŠÅ╣®ŠņżŪżóżĻĪó╬╠ŠÅ╣®ŠņżŪżŽż╩ż½ż├ż┐ĪŻż│ż╬ż█ż╔Xilinxż¼Įą▓┘ż╣żļ16nm FinFETźūźĒź╗ź╣ż╬UltraScale+źšźĪź▀źĻ(┐▐1)ż¼╬╠ŠÅź┴ź├źūż╚żżż©żĮż”ż└ĪŻ

┐▐1ĪĪXilinxż╬┐ĘFPGAĪóUltrascale+źóĪ╝źŁźŲź»ź┴źŃż╬×æēäĪĪĮąųZĪ¦Xilinx
XilinxżŽĪóTSMCż¼×æļ]ż╣żļFinFETż╚żżż”3╝ĪĖĄźūźĒź╗ź╣ż“Ņ~╗╚ż╣żļź╚źķź¾źĖź╣ź┐ż“╗╚żżĪó2.5Dż╬źżź¾ź┐Ī╝ź▌Ī╝źČż╦żĶżļź┴ź├źū╝┬äóż“║╬żĻ╣■żÓż│ż╚żŪĪó║Żövż╬Č\Įčż“3D-on-3Dż╚Ō}ż¾żŪżżżļĪŻFinFETżŽź▓Ī╝ź╚─Š▓╝ż╬ȧĒś┴žż“3öĄĖ■ż½żķ╩─żĖż│żßżļČ\ĮčżŪżóżļż┐żßĪóŠ├õJ┼┼╬üż¼─Ńżżż│ż╚ż¼ØŖ─╣ż╚ż╩ż├żŲżżżļĪŻź╔źķźżźųē”╬üż“æųż▓żļż╦żŽĪóźšźŻź¾ż╬┐¶ż“╗\żõż╗żążĶżżĪŻźšźŻź¾ż╬┐¶żŽWĪ╩ź┴źŃź¾ź═źļ╔²Ī╦ż╦┴Ļ┼÷ż╣żļż┐żßĪóźšźŻź¾ż“╗\żõż╣ż│ż╚żŪWż“ĮjżŁż»ż╣żļĪŻ
16nm FinFETźūźĒź╗ź╣żŪ×æļ]żĄżņżļUltrascale+źšźĪź▀źĻżŽĪó3D IC(┘ć│╬ż╦żŽźżź¾ź┐Ī╝ź▌Ī╝źČæųżŪ╩Ż┐¶ż╬ź┴ź├źūż“╩┬ż┘żŲ└▄¶öż╣żļ2.5D)ż“ŠW├ōż╣żļVirtexźĘźĻĪ╝ź║ż╚ĪóØÖ×┤Š╬ź▐źļź┴ź│źóż“┼ļ║▄ż╣żļZynqźĘźĻĪ╝ź║Ī󿥿ķż╦╣ŁżżźßźŌźĻ┬ė░Ķ╔²ż“Ęeż─Kintexż╬3źĘźĻĪ╝ź║ż¼żóżļĪŻż│ż╬ŲŌĪó║ŻövżŽVirtexż╚Zynqż“╚»╔ĮżĘż┐ĪŻ
16nm FinFETźūźĒź╗ź╣ż╬└Łē”ż“īÖż½ż╣ż┐żßĪó║ŪĮj432Mźėź├ź╚ż╬źßźŌźĻż“ĮĖ└čż╣żļż╚Ų▒╗■ż╦ĪóSmartConnectż╚Ō}żųŪ█└■Č\Įčż“║╬├ōżĘż┐(┐▐2)ĪŻ“£═ĶĪóź╚źķź¾źĖź╣ź┐ż╬Øó╦Īż“╚∙║┘▓ĮżŪżŁżŲżŌŪ█└■żŽ╚∙║┘▓ĮżŪżŁż╩ż½ż├ż┐ĪŻź©źņź»ź╚źĒź▐źżź░źņĪ╝źĘźńź¾Īóź╣ź╚źņź╣ź▐źżź░źņĪ╝źĘźńź¾ż╩ż╔┐«═Ļ└Łż╬╠õ¼öż¼żóżļż½żķż└ĪŻż│ż╬ż┐żßĪóź╚źķź¾źĖź╣ź┐ż╬└Łē”żŽæųż¼ż├żŲżŌLSIż╚żĘżŲż╬└Łē”żŽæųż¼żķż╩żżż╚Ė└ż’żņżŲżżż┐ĪŻ
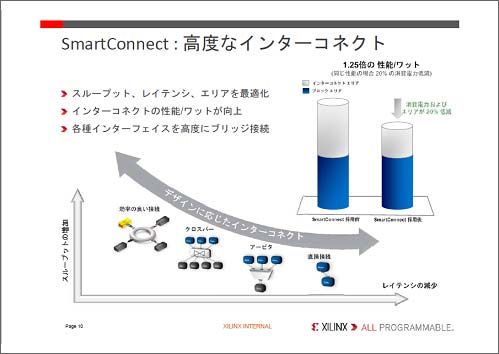
┐▐2ĪĪźņźżźóź”ź╚żõŪ█└■ż╦żĶż├żŲ║Ū┼¼▓Įż╣żļSmartConnectČ\ĮčĪĪĮąųZĪ¦Xilinx
Xilinxż¼║╬├ōżĘż┐Č\Į迎Īó║┘ż»żŪżŁż╩żżŪ█└■ęÆūāż╦żĶżļ▒Ųūxż“Į³ĄŅż╣żļż┐żßĪóŪ█└■ż“─╣ż»ż╗ż║└┌żĻü÷ż©żļöĄ╝░ż╬ź»źĒź╣źąĪ╝ź╣źżź├ź┴żõźąź╣Ēö╣ńż“ķcż▒żļż┐żßż╬źóĪ╝źėź┐Īóź╣ź╚źĻĪ╝źÓźķźżź¾ź╔źčź▒ź├ź╚▓Įż╩ż╔Īóźņźżźóź”ź╚źŪźČźżź¾ż╦żĶż├żŲŪ█└■ż“╗╚żż╩¼ż▒żŲżżżļĪŻövŽ®ż╬ź╣źļĪ╝źūź├ź╚ż╚źņźżźŲź¾źĘż╬╗┼══ż╦żĶż├żŲĪóż╔ż╬ź╣źżź├ź┴ż“╗╚ż”ż╬ż¼║Ū┼¼ż╩ż╬ż½ż“»éżßżļĪŻźżź¾ź┐Ī╝ź▌Ī╝źČż“▓żĘżŲ2.5D╝┬äóż╣żļŠņ╣ńżŽĪóźżź¾ź┐Ī╝ź▌Ī╝źČż╦żŌź╣źżź├ź┴övŽ®ż“└▀ż▒żļĪŻż│ż╬SmartConnectż╦żĶż├żŲĪóŲ▒żĖ└Łē”ż╩żķŠ├õJ┼┼╬üżŽ20%║’žōżĄżņż┐ż╚żĘżŲżżżļĪŻ
Ų▒╝ęż¼║╬├ōżĘż┐żŌż”▐kż─ż╬Č\Į迎źßźŌźĻż╬═Ų╬╠ż“╗\żõżĘż┐ż│ż╚ż└ĪŻFPGAź└źżæųżŪżŽ“£═ĶĪó╩┬š`└▄¶öżĄżņż┐└§żżFIFOĪ╩First-in First-outĪ╦źßźŌźĻżõźĘźšź╚źņźĖź╣ź┐ż╩ż╔┐¶Kźėź├ź╚źßźŌźĻż“╗╚ż├żŲżżż┐ĪŻ┐¶╝åMźėź├ź╚═Ų╬╠ż╬źßźŌźĻżŽ│░ŗźßźŌźĻż╚żĘżŲżżż┐ĪŻż│żņżŪżŽ╣ŌÅ]Ų░║ŅżŽ┤³┬įżŪżŁż╩żżĪŻ║ŻövżŽ┐¶Ø▓Mźėź├ź╚ż╬ĮjżŁż╩źßźŌźĻĪ╩UltraRAMĪ╦ż“FPGAź┴ź├źūż╦ĮĖ└čż╣żļż│ż╚żŪźßźŌźĻż╬źęź├ź╚╬©ż¼ĮjżŁż»æųż¼żĻĪóźņźżźŲź¾źĘż¼ø]ż»ż╩ż├ż┐ĪŻ
żĄżķż╦ARMż╬ź▐źżź»źĒźūźĒź╗ź├źĄź│źóż“ĮĖ└čżĘż┐SoCźĘź╣źŲźÓżŪżŽĪó╣ŌÅ]ż╬źóźūźĻź▒Ī╝źĘźńź¾źūźĒź╗ź├źĘź¾ź░ż╦64źėź├ź╚ż╬Cortex-A53ź»ź’ź├ź╔ź│źóż╚ĪóźĻźóźļź┐źżźÓŲ░║Ņ├ōż╦32źėź├ź╚ż╬Cortex-R5źŪźÕźóźļź│źóż“ĮĖ└čżĘż┐(┐▐3)ż█ż½Īóź░źķźšźŻź├ź»ź│źóż╚żĘżŲARMż╬Mali-400MPżõĪóź╗Ī╝źšźŲźŻ&ź╗źŁźÕźĻźŲźŻövŽ®ĪóźßźŌźĻĪóźčź’Ī╝ź▐ź═źĖźßź¾ź╚övŽ®ż╩ż╔ż“ĮĖ└čżĘż┐ĪŻżŌż┴żĒż¾FPGAövŽ®żŌĮĖ└čĪóżĮż╬├µż╦övŽ®źųźĒź├ź»ż╚żĘżŲĪóH.265źėźŪź¬ź│Ī╝źŪź├ź»ż╚Īó╣ŌÅ]źżź¾ź┐źšź¦Ī╝ź╣övŽ®Īóź╚źķź¾źĘĪ╝źąövŽ®ĪóUltraRAMż“ĮĖ└čżĘż┐ĪŻ
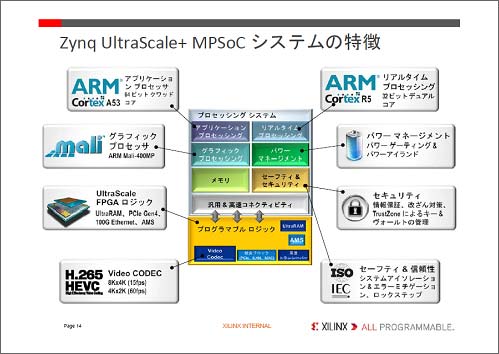
┐▐3ĪĪźžźŲźĒż╬ź▐źļź┴ź│źóż“ĮĖ└čżĘż┐SoCĪóZynqĪĪź½ź╣ź┐ź▐źżź║ŗ╩¼ż╬ż▀FPGAż“╗╚ż”ĪĪĮąųZĪ¦Xilinx
XilinxżŽ“£═Ķż╬28nmż╬7źĘźĻĪ╝ź║ż╚Īó║Żövż╬16nm FinFETČ\Įčż╬SoCż╚ż“╚µ│ėżĘż┐ĪŻż│ż╬UltraRAMż╚SmartConnectż╬╬ŠöĄż“├ōżżż┐Šņ╣ńĪóPCIeźŌźĖźÕĪ╝źļżŪż╬▓ĶćĄĮĶ═²żŪżŽŲ▒żĖŠ├õJ┼┼╬üżŪ└Łē”żŽĪó“£═Ķż╬525Operations /╔├ż¼1880Operations /╔├ż╚3.6Ū▄ż╦æųż¼ż├ż┐ĪŻ▐köĄżŪĪóUltrascale+źóĪ╝źŁźŲź»ź┴źŃż“ĮĖ└čżĘż┐MPSoCż╬ź┘ź¾ź┴ź▐Ī╝ź»żŪżŽĪó1080pż╬źšźļHD▓Ķ楿“4K2Kż╦╩č┤╣ż╣żļźėźŪź¬▓±Ą─ż╬▒■├ōżŪżŽĪó1ź’ź├ź╚┼÷ż┐żĻ5Ū▄ż╬└Łē”ĪóĮoČ”ŖWµ£╩³┴„ż╬źĮźšź╚ź”ź©źó╠Ą└■ż╬▒■├ōżŪżŽ1ź’ź├ź╚┼÷ż┐żĻ4.8Ū▄ż╬└Łē”ż“żĮżņżŠżņįużŲżżżļż╚żżż”ĪŻż│ż╬Ultrascale+źóĪ╝źŁźŲź»ź┴źŃżŪżŽ2015ŃQż╦╣ń╝Ŗ50╦▄░╩æųż╬źŪźČźżź¾ż¼źŲĪ╝źūźóź”ź╚żĄżņżļ═Į─Ļż└ż╚żĘżŲżżżļĪŻ

