AIżžĮjżŁż»┬╔ż“└┌ż├ż┐nVidia
ź░źķźšźŻź├ź»ź╣ICżŪżóżļGPUż¼įu┴Tż╩nVidiażŽĪó▓ĶćĄŪ¦╝▒Īó▓╗╠mŪ¦╝▒ż╩ż╔źčź┐Ī╝ź¾Ū¦╝▒ż╦Īóź▐źĘź¾źķĪ╝ź╦ź¾ź░żõźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╩ż╔ż╬AIĪ╩┐═╣®ē¶ē”Ī╦ż“īÖ├ōżĘżŲżżżļż¼ĪóżĮż╬└¬żżż“ż▐ż╣ż▐ż╣▓├Å]żĘżŲżżżļĪŻŲ▒╝ę╝ń╠¢ż╬Č\Įč▓±Ą─GTC 2016żŪżĮż╬öĄĖ■ż“£½żķż½ż╦żĘż┐ĪŻ

┐▐1ĪĪnVidiaż╬CEOżŪżóżļJen-Hsun HuangĢ■
GPUĪ╩ź░źķźšźŻź├ź»ź╣źūźĒź╗ź├źĄĪ”źµź╦ź├ź╚Ī╦żŽż│żņż▐żŪ3╝ĪĖĄ▓Ķ楿“ķWżŁĪóĖ„ż╬▒ó▒Ųż╩ż╔ż─ż▒żŲżĶżĻ└^┐┐ż╦ŖZż┼ż▒żļż╚żżż├ż┐ź▓Ī╝źÓ▒■├ōż¼╝ńż╩├ō²ŗż└ż├ż┐ĪŻżĮżņż¼CPUż“▌ö║┤ż╣żļ╣Ō└Łē”ź│ź¾źįźÕĪ╝źŲźŻź¾ź░Ī╩HPCĪ╦ż╦GPUż“╗╚ż”żĶż”ż╦ż╩żĻĪ󿥿ķż╦żĮż╬├ō²ŗż“AIż╬źčź┐Ī╝ź¾Ū¦╝▒ż╚żĮż╬│žØ{ż╦▒■├ōż╣żļżĶż”ż╦ż╩ż├ż┐ĪŻ║ŻŃQż╬GTCĪ╩GPU Technology ConferenceĪ╦żŽAI▐k┐¦ż└ż├ż┐ĪŻŲ▒╝ęCEOż╬Jen-Hsun HuangĢ■(┐▐1)ż╬┤─┤╣ų▒ķż╬ź┐źżź╚źļżŽĪųźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░Ī¦AI│ū╠┐Īūż╚¼öżĘżŲż¬żĻĪóżĮż╬══╗ęż“żĶż»╔ĮżĘżŲżżżļĪŻ
nVidiażŽ├▒ż╦GPUż╬▒■├ōšJ░Žż“ź▓Ī╝źÓż½żķź│ź¾źįźÕĪ╝źŲźŻź¾ź░Č\ĮčżõAIżžż╚╣Łż▓żŲżŁż┐ż└ż▒żŪżŽż╩żżĪŻżÓżĘżĒAIż╦╗╚ż”źŪźąźżź╣ż╚żĘżŲīÖ├ōż╣żļöĄż¼░ę╬üż“╚»Ä¦ż╣żļż│ż╚ż¼ż’ż½ż├żŲżŁż┐ż│ż╚ż╦żĶżļĪŻ╬Ńż©żąĪó▓╗╠mŪ¦╝▒ż╦īÖ├ōż╣żļż╚Īó“£═Ķż╬Ė└±äżõ╩Ė╠«ż╬ØŖ─╣├ĻĮąż“├ōżżż┐ź│ź¾źįźÕĪ╝ź┐źóźļź┤źĻź║źÓżŪ╝ŖōQżĘżŲżżż┐öĄ╦Īż╚╚µż┘żŲĪóĖĒŪ¦╝▒╬©ż¼▓╝ż¼ż├ż┐ż╚żżż”źŪĪ╝ź┐ż¼ĮążŲżŁż┐ĪŻ2016ŃQ9ĘŅ16Ų³ż╦ź▐źżź»źĒźĮźšź╚ż¼╚»╔ĮżĘż┐ĪóAIż“╗╚ż├ż┐▓╗╠mŪ¦╝▒ż╬ĖĒŪ¦╝▒╬©żŽ“£═Ķż╬10%░╩æųż½żķ2%µć┼┘ż╦ĮjżŁż»▓╝ż¼ż├żŲżżżļĪ╩┐▐2Ī╦ĪŻ
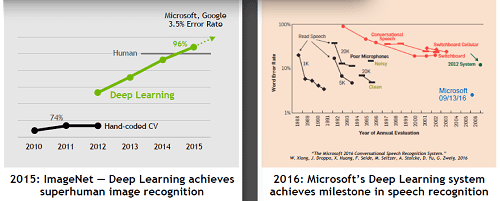
┐▐2ĪĪ▓╗╠mŪ¦╝▒żŽźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╦żĶżĻĖĒŪ¦╝▒╬©żŽ2%ż╦ĪĪĮąųZĪ¦nVidiaĪĪMicrosoftż╬źŪĪ╝ź┐ż“░·├ō
─╠Š’ż╬▓±ÅBż“żĘżŲżżżļż╚ĪóĪųżóĪ╝Īūż╚ż½Īųż©Ī╝Īūż╚ż½┴T╠Żż╬ż╩żżĖ└±äż¼¾Hż»ĪóżĮż╬żĶż”ż╩╠ĄŠGż╩Ė└±äż“Ū¦╝▒ż╣żļż┐żßż╬źóźļź┤źĻź║źÓżŽØŁ═ūż¼ż╩żżżŽż║ĪŻżĘż½żĘ“£═Ķż╬ź│ź¾źįźÕĪ╝ź┐źóźļź┤źĻź║źÓżŽµ£żŲż╬Ė└±äż“Ū¦╝▒ż╣żļżĶż”ż╦┼žżßżŲżŁż┐ĪŻż│żņż╦×┤żĘżŲĪóAIżŪżŽĪóĪųżóĪ╝ĪūżõĪųż©Ī╝ĪūżŽ┴T╠Żż╬ż╩żżĖ└±äż└ż╚╚ĮéāżĘżŲ└┌żĻ╝╬żŲżņżążĶżżĪŻĪųżóĪ╝ĪūżõĪųż©Ī╝Īūż“┤▐żßż┐▓╗╠mż╬╩Ż╗©ż╩źčź┐Ī╝ź¾ż½żķźčź┐Ī╝ź¾żĮż╬żŌż╬ż╬ØŖ─╣ż“├ĻĮążĘĪó╬Óō¶└Łż╩ż╔ż½żķ┴T╠Żż┼ż▒│žØ{ż“╣įż”ż│ż╚ż╦żĶż├żŲĪóŪ¦╝▒╬©żŽæųż¼ż├ż┐ĪŻAIżŪżŽĪó▓┐╗hövĪ”▓┐╦³övż╚│žØ{żĘżŲ│ąż©ż┐źčź┐Ī╝ź¾ż“╗▓Š╚źčź┐Ī╝ź¾ż╚żĘżŲ╗╚żżĪóō¶ż┐żĶż”ż╩źčź┐Ī╝ź¾ż¼ĖĮżņż┐żķĪó╗▓Š╚źčź┐Ī╝ź¾ż╚╚µ│ėżĘ╚Įéāż╣żļż╬żŪżóżļĪŻ
nVidiaż╬AIźĘźšź╚żŽĪ󟻟ļź▐ż╬└ż─cż╦żŌ╣Łż¼ż├żŲżŁżŲżżżļĪŻżŌż╚żŌż╚nVidiażŽĪó5ŃQż█ż╔Øiż½żķź»źļź▐ż╦GPUż“┼ļ║▄żĘĪóź└ź├źĘźÕź▄Ī╝ź╔ż╦ķ]ŠĮźčź═źļż“Ų│Ų■żĘĪóżĮż│ż╦ķWż»ź╣źįĪ╝ź╔źßĪ╝ź┐żõź┐ź│źßĪ╝ź┐ż“Ī󿣿ņżżż╩▓Ķ楿Ū╔ĮĖĮż╣żļż│ż╚ż“ų`┼¬ż╚żĘżŲżżż┐ĪŻź└ź├źĘźÕź▄Ī╝ź╔żžż╬ŠW├ōż╦żĶżļź╔źķźżźąĪ╝ܦ▐qż¼ų`┼¬ż└ż├ż┐ĪŻ╗─Ū░ż╩ż¼żķż│ż╬├ō²ŗżŽĪó▐kŗż╬ź»źļź▐źßĪ╝ź½Ī╝ż╦żĘż½║╬żĻŲ■żņżķżņż╩ż½ż├ż┐ĪŻżŌż┴żĒż¾Ī󟻟ļź▐żžż╬ķ]ŠĮźčź═źļż╬║╬├ōżŽż▐ż└┐╩ż¾żŪżżż╩żżĪŻ
ż╚ż│żĒż¼ĪóśOŲ░▒┐┼Š┘Zż¼ÅRų`ż“ĮĖżßżļżĶż”ż╦ż╩ż├żŲż»żļż╚Īóź╔źķźżźąĪ╝ܦ▐qż╬źŲź»ź╬źĒźĖĪ╝żŽ▐k╩čżĘż┐ĪŻź╔źķźżźąĪ╝ż╬ØiöĄż╦żóżļ×┤ō■رż¼ź»źļź▐ż╩ż╬ż½Īó┐═ż╩ż╬ż½ĪóśO┼Š┘Zż╩ż╬ż½Ī󟻟ļź▐żŪżŌź╚źķź├ź»ż╩ż╬ż½ĪóŠĶ├ō┘Zż½Īó┐═┤ųż╬┤Ńż╚Ų▒żĖźņź┘źļ░╩æųż╬└Łē”ż¼ĄßżßżķżņżļżĶż”ż╦ż╩ż├ż┐ĪŻż╣żļż╚źčź┐Ī╝ź¾Ū¦╝▒Č\Įčż¼Č╦żßżŲ─_═ūż╦ż╩ż├żŲż»żļĪŻżĮż│żŪAIż╬┼ąŠņĪóż╚żżż”źĘź╩źĻź¬ż¼ĮążŲżŁż┐ĪŻ
AIż╦GPUż“╗╚ż”═²ĮyżŽĪóAIĪóØŖż╦źŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░żŪżŽź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬Š}╦Īż╚▐k├ūż╣żļż½żķż└ĪŻż│ż│żŪżŽ┐└Ęą║┘╦”ż“ż▐ż═ż┐╣Įļ]ż╬Š╩¾┼┴├ŻźĘź╣źŲźÓż“ŠW├ōż╣żļĪŻź╦źÕĪ╝źĒź¾Ī╩┐└Ęą║┘╦”Ī╦1Ė─żŽĪó£å┐└Ęążõ▓╗╠mż╩ż╔ż╬¾H┐¶ż╬Ų■╬ü┐«ęÄż¼╦N║┘╦”ż╦Ų■żļż╚Īó║ŪĮķż╬╦N║┘╦”żŪżŽĪóŲ■ż├żŲżŁż┐ż╣ż┘żŲż╬Ų■╬ü┐«ęÄ(x1Ī┴xn)ż╦─_ż▀Ī╩a1Ī┴anĪ╦ż“²Xż▒ĪóżĮżņżķż“’BżĘ╣ńż’ż╗żļĪŻ║ŪĖÕż╦╝ŖōQżĘż┐±T▓╠ż“yż╚żĘżŲĮą╬üż╣żļĪŻż│żņżŽĪóGPUż¼įu┴Tż╩└čŽ┬▒ķōQżĮż╬żŌż╬ż└ĪŻż│ż╬─_ż▀ż“│žØ{ż╦żĶż├żŲ╩čż©żŲżżż»ż╚ĪóĮą╬üyżŌ╩čż’żļĪŻ┐└Ęą║┘╦”żŽŠ«╦Nż└ż▒żŪ1000▓»Ė─żóżļż╚żżż’żņżŲżżżļż┐żßĪó┼┼╗ęövŽ®żŪżŽĪóż│ż╬żĶż”ż╩║┘╦”ż“żŪżŁżļż└ż▒¾H┐¶├ō┴TżĘżŲĪó┐└Ęąź═ź├ź╚ź’Ī╝ź»ż“╣Į└«żĘżŲżżż»ĪŻ
źŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╬▒■├ō╩¼╠ŅżŽĪó▓ĶćĄŪ¦╝▒żõ▓╗╠mŪ¦╝▒ż╩ż╔ż╬źčź┐Ī╝ź¾Ū¦╝▒Č\ĮčĪŻżĮżņżķż“ź┘ź¾ź┴ź▐Ī╝ź»ż╚żĘżŲĪónVidiaż╬ź│źóČ\ĮčżŪżóżļGPUż╬└Łē”Ė■æųżŌ▓├Å]żĘżŲżżżļĪŻ2016ŃQż╦╚»╔ĮżĘż┐GPUżŪżóżļPascalżŽĪó3ŃQØiż╦╚»╔ĮżĘż┐GPUż╬Keplerż╬65Ū▄ż╬└Łē”ż“Ęeż─ĪŻ16nm FinFETČ\Įčżõ3D-ICČ\ĮčżŪżóżļHMB2źßźŌźĻż╩ż╔ż╬└Ķ├╝Č\Įčż“├ōżżżŲżżżļĪŻPascalżŽżŌżŽżõź╣Ī╝źčĪ╝ź│ź¾źįźÕĪ╝ź┐ż“╣Į└«ż╣żļ─_═ūż╩Č\ĮčżŪżŌżóżļĪŻ

┐▐3ĪĪ2016ŃQż╦╚»╔ĮżĘż┐┐ĘGPUĪųPascalĪūĪĪ16nm FinFETżõTSVźßźŌźĻż╩ż╔└Ķ├╝Č\Įčż╬ōĮż└ĪĪĮąųZĪ¦nVidia
GPUżŽź░źķźšźŻź├ź»ź╣Īóż╣ż╩ż’ż┴Īųż¬│©ż½żŁĪū└ņ├ōż╬źūźĒź╗ź├źĄżŪżóżļĪŻ│©ż“Į±ż»Šņ╣ńż╬źŪź├źĄź¾ż╦┴Ļ┼÷ż╣żļż╬ż¼Š«żĄż╩įÆ│čĘ┴Ī╩ź╚źķźżźóź¾ź░źļĪ╦ż“ż─ż╩ż«╣ńż’ż╗żŲżżż»Īóż╚żżż”║ŅČ╚żŪżóżļĪŻżĮż╬æųż╦┐¦ż“┼╔żļĪ╩źņź¾ź└źĻź¾ź░Ī╦ż╚żżż”║ŅČ╚ż“ĘążŲ│©ż“┤░└«żĄż╗żļŚlż└ż¼Īó╝┬żŽźņź¾ź└źĻź¾ź░║ŅČ╚ż“ĮjżŁż╩▓ĶĀCż╬▐kŗżŪżŽĪóō¶ż┐żĶż”ż╩┐¦ż“▓┐┼┘żŌ┼╔ż├żŲżżżļ║ŅČ╚ż╦Ė½ż©żļĪŻ╝┬║▌Īó1ĮŚż╬źšźņĪ╝źÓæųżŪżŽĪó▓ĶĀCż“╩¼│õżĘĪó┐¦ż“│╩Ū╝żĘżŲżżżļźßźŌźĻż½żķźŪźŻź╣źūźņźżæųż╦┐¦ż“─źżĻ¤²ż▒żļ║ŅČ╚żĮż╬żŌż╬ż“żĘżŲż¬żĻĪóż▐żĄż╦╩┬š`ĮĶ═²żĘżŲżżżļż│ż╚ż╦┼∙żĘżżĪŻCPUżŽĪó╩¼┤¶╠┐╬ßż╦żĶżĻ══Ī╣ż╩║ŅČ╚ż“├┤ż’ż╩ż▒żņżąż╩żķż╩żżż┐żßĪó├▒ĮŃż╩╩┬š`ĮĶ═²żŽĖ■ż½ż╩żżĪŻ├▒ĮŃż╩╩┬š`ĮĶ═²ż│żĮĪóGPUż¼║ŪżŌįu┴Tż╚ż╣żļ║ŅČ╚żŪżóżļĪŻż│ż╬║ŅČ╚żŽĪóō¶ż┐żĶż”ż╩▓Ķ楿õ▓╗╠mż╩ż╔ż╬źčź┐Ī╝ź¾ż“▓┐┼┘żŌ│ąż©╣■ż▐ż╗żļĪų│žØ{Īūż╚ō¶żŲżżżļĪŻż└ż½żķGPUżŽĪóź▐źĘź¾źķĪ╝ź╦ź¾ź░ĪóźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╦Ė■żżżŲżżżļż╚żżż”Ślż└ĪŻ
źŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░żŪżŽĪóIoTżõź╣ź▐Ī╝ź╚źŪźąźżź╣ż╩ż╔ż½żķż╬źŪĪ╝ź┐ż“│žØ{żĘĪóź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»żŪ▓┐┼┘żŌĘ½żĻ╩ųżĘĪó┐õébż“╣įżżĪóIoTż╦źšźŻĪ╝ź╔źąź├ź»ż╣żļĪ╩┐▐4Ī╦ĪŻGPUżŽż│ż╬├µżŪ│žØ{ż╚┐õébż“├┤ż├żŲżżżļĪŻ╬Ńż©żąĪó┐õéb├ōż╬źóź»ź╗źķźņĪ╝ź┐żŪżóżļTesla P4/P40żŽĪóCPUż╚╚µż┘żŲĪóP4żŽź©ź═źļź«Ī╝Ė·╬©ż¼40Ū▄ĪóP40żŽ└Łē”ż¼40Ū▄ż╚żżż”ĪŻżĄżķż╦Īó║Ū┐Ęż╬GPUźŌźĖźÕĪ╝źļż╚żĘżŲĪó┐õébź©ź¾źĖź¾ż“║Ū┼¼▓Įż╣żļ└Łē”ż“Ęeż─TensorRTĪó┴╚ż▀╣■ż▀ź╣Ī╝źčĪ╝ź│ź¾źįźÕĪ╝ź┐ż╬Jetson TX1ż╩ż╔╣Ō└Łē”ż╬┐Ę×æēäż“HuangĢ■żŽŠę▓żĘż┐ĪŻ
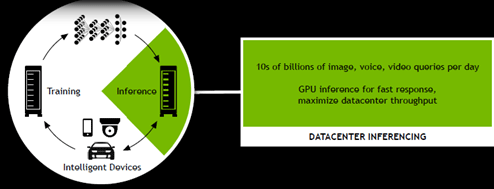
┐▐4ĪĪAIżŪżŽIoTż½żķ│žØ{Īóź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»Īó┐õébź▐źĘź¾ż╚żżż”źĄźżź»źļż“▓┐┼┘żŌĘ½żĻ╩ųż╣ĪĪĮąųZĪ¦nVidia
Ų³╦▄żŪżŽĪó╣®Šņ├ōźĒź▄ź├ź╚ż╬źšźĪź╩ź├ź»ż╚─¾Ę╚żĘż┐ĪŻźšźĪź╩ź├ź»ż╬╣®Šņż╦nVidiaż╬AI├ōGPUźŌźĖźÕĪ╝źļż“Ų│Ų■żĘĪóźĒź▄ź├ź╚ż“ĖŁż»ż╣żļż│ż╚ż╦żĶż├żŲĪóźµĪ╝źČĪ╝ż╬Ö┌ŠÅĖ·╬©ż“æųż▓żĶż”ż╚żżż”┴└żżż¼żóżļĪŻ
ØiĮężĘż┐żĶż”ż╦ĪóAIż“╗╚ż├ż┐źčź┐Ī╝ź¾Ū¦╝▒żŽĪ󟻟ļź▐ż╬śOŲ░▒┐┼Šż╦żŌĖ■żżż┐Č\ĮčżŪżóżļĪŻź»źļź▐ż╬ØiöĄż╦żóżļżŌż╬ż“Ū¦╝▒żĘĪóövķcż╣żļż╬ż½Īó─õż▐żļż╬ż½Īóż╚żżż”╚ĮéāżŌ╣įż”ĪŻź»źļź▐ż¼╣ŌÅ]╠OŽ®ż½▐k╚╠╠Oż½Ī󟻟ļź▐ż╬╝■░Žż╦żóżļżŌż╬Īóż╩ż╔żŌŪ¦╝▒ż╣żļĪŻżĄżķż╦×┤ō■رż¼ż║ż├ż╚Øiż½żķżóż├ż┐ż╬ż½ĪóŲ═─śĮążŲżŁż┐żŌż╬ż½Īóż║ż├ż╚╝{╦_żĘżŲżżżļżŌż╬ż½Īóż└ż├ż┐żķż╔ż╬żĶż”ż╦ż╣ż┘żŁż½Īóż╩ż╔ż“╚Įéāż╣żļĪŻ╚Įéāż¼żŪżŁż┐żķĪóźųźņĪ╝źŁż“ż½ż▒żļż╬ż½īÜżž┤¾żļż╬ż½Īóż╩ż╔ż╬źóź»źĘźńź¾ż“ż╚żļĪŻźóź»źĘźńź¾żŽöUĖµÅUż╬ź▐źżź│ź¾ż“┤▐żÓECUĪóźóź»ź┴źÕź©Ī╝ź┐żŪ╣įż”ĪŻźóź»źĘźńź¾░╩│░żŽAIżŪŠ╩¾ĮĶ═²ż╣żļż│ż╚ż¼żŪżŁżļĪŻ
ż│żņż▐żŪż╬śOŲ░▒┐┼ŠżŽĪ󟻟ļź▐ż╬ĖĪĮąĪ”Ū¦╝▒Ī󿥿ķż╦żŽŪ“└■ĖĪĮąż╩ż╔ż“╣įżżĪ󟥟ķź”ź¾ź╔ĖĪĮążŌ▓├ż©żŲżżż┐ĪŻżõżŽżĻų`░§ż╚ż╩żļŪ“└■ż╩ż╔ż╬×┤ō■رż¼ØŁ═ūż└ż├ż┐ĪŻ×┤ō■رż¼»éż▐żņżąĪóAIż“╗╚ż’ż╩ż»żŲżŌź│ź¾źįźÕĪ╝ź┐╝ŖōQż└ż▒żŪżŌŠ╩¾ĮĶ═²żŽżŪżŁż┐ĪŻżĘż½żĘĪóų`░§ż╬ż╩żżĪó╬Ńż©żąæčż╬├µż╬Īųż▒żŌż╬ż▀ż┴Īūż“┴÷żļżĶż”ż╩źŽź¾ź╔źļ┴Ó║Ņż╚ż╩żļż╚ĪóĪųöĄµć╝░żŽż╩żżĪŻźŽź¾ź╔źļ┴Ó║ŅżŽ╝ŖōQżŪżŽż╩ż»╣įŲ░Ī╩BehaviorĪ╦żŪżóżļĪŻż└ż½żķĪóĘą┘xż“└čż¾ż└│žØ{Īóż╣ż╩ż’ż┴AIż¼ØŁ═ūż╩ż╬ż└Īūż╚HuangĢ■żŽ╣ų▒ķżŪĮęż┘żŲżżżļĪŻ
ż┐ż└ĪóGPUż╬³cżŁĮĻżŽĪóŠ├õJ┼┼╬üż¼ż▐ż└ĮjżŁżżż│ż╚ż└ĪŻż│żņż▐żŪżĶżĻżŽŠ»ż╩ż»ż╩ż├ż┐ż╚żŽżżż©Īóż▐ż└┐¶Ø▓WżŪżŽLSIż╚żĘżŲĮjżŁżżĪŻżĄżķż╦▓╝ż▓żļż┐żßż╬╗Ņż▀ż╚żĘżŲIBMż╬TrueNorthź┴ź├źūżõGoogleż╬TPUĪ╩Tensor Processing UnitĪ╦ż╩ż╔AI└ņ├ōż╬źūźĒź╗ź├źĄż¼┼ąŠņżĘżŲżżżļĪŻż│ż│ż╦Ų³╦▄ż╬╚ŠŲ│öüźßĪ╝ź½Ī╝ż╦żŌź┴źŃź¾ź╣ż¼żóżļĪŻ

