ĪųźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░│žØ{ż╦żŽź”ź¦Ī╝źŽæä╠Žż╬ĄĮjż╩ź┴ź├źūż¼ØŁ═ūĪū
ż½ż─żŲĪ󟔟¦Ī╝źŽź╣ź▒Ī╝źļLSIĪ╩WSIĪ╦ż╚Ō}żążņżļĄĮjż╩ź┴ź├źūż¼żóż├ż┐ĪŻAI╗■┬Õż╦Ų■żĻĪóźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╬│žØ{├ōż╦1├¹2000▓»ź╚źķź¾źĖź╣ź┐ż“ĮĖ└čżĘż┐ĄĮjż╩źĘźĻź│ź¾ź┴ź├źūż¼┼ąŠņżĘż┐Ī╩╗▓╣═½@╬┴1Ī╦ĪŻä▌ź╣ź┐Ī╝ź╚źóź├źūCerebras╝ęż¼╗Ņ║ŅżĘż┐ż│ż╬ź┴ź├źūżŽWSEĪ╩Wafer Scale EngineĪ╦ż╚Š╬ż╣żļ21.5cm│čż╬ĀC└čż╬źĘźĻź│ź¾ż“300mmź”ź¦Ī╝źŽżŪ║Ņ×æżĘż┐ĪŻ
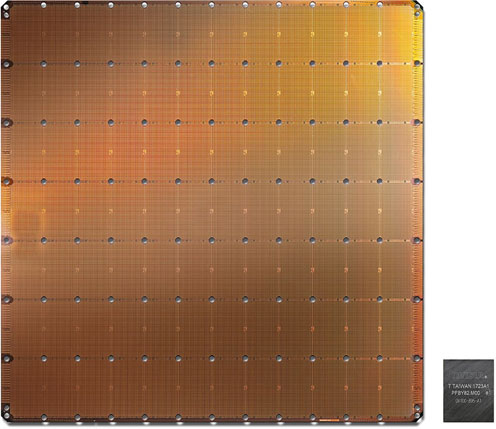
┐▐1ĪĪCerebras╝ęż¼│½╚»żĘż┐ź”ź¦Ī╝źŽź╣ź▒Ī╝źļż╬ĄĮjż╩źĘźĻź│ź¾ź┴ź├źūĪĪīÜ▓╝ż╬ź┴ź├źūżŽż│żņż▐żŪż╬Nvidiaż╬GPUĪĪĮąųZĪ¦Cerebras╝ęź█Ī╝źÓź┌Ī╝źĖż½żķ
ż│ż╬ź”ź¦Ī╝źŽæä╠Žż╬ź┴ź├źūż╬ĀC└迎46,225mm2ż╚ĄĮjżŪĪóż│żņż▐żŪ║ŪĮjż╬GPUĪ╩ź░źķźšźŻź├ź»ź╣źūźĒź╗ź├źĄĪ╦ż¼211▓»ź╚źķź¾źĖź╣ź┐ż“ĮĖ└čżĘż┐815mm2ż╬ź┴ź├źūĀC└čż└ż½żķĪóż╩ż¾ż╚żĮż╬56.7Ū▄żŌĮjżŁżżĪŻ300mmź”ź¦Ī╝źŽż½żķ1ĮŚżĘż½ŲDżņż╩żżź”ź¦Ī╝źŽź╣ź▒Ī╝źļż╬AIź┴ź├źūż└ĪŻ
Cerebras╝꿎ĪóAIź┴ź├źūż╦ż╚ż├żŲ║Żż¼źÓĪ╝źóż╬╦Īō¦░╩æųż╦AI▒ķōQż╬ęŖ═ūż¼3.5ź§ĘŅż┤ż╚ż╦2Ū▄ż╦╣Ōż▐żļĪóż╚żżż”┐Ę╦Īō¦ż╬╗■┬Õż“Ę▐ż©ż┐ż╚Ė½żŲżżżļĪŻż│ż╬ĄĮjż╩AIź┴ź├źūżŽĪóTSMCż╬16nmźūźĒź╗ź╣żŪ║ŅżķżņżŲż¬żĻĪóżĮżņżŪżŌźņź┴ź»źļźĄźżź║ż“╣═╬ĖżĘżŲµ£öüżŪ▐kż─ż╬▒ķōQ▀_ż“║Ņż├ż┐ż╬żŪżŽż╩ż»Īó▒ķōQźųźĒź├ź»ż“12Ī▀7Ė─Īß84Ė─╔▀żŁĄ═żßżŲżżżļĪŻ▐kż─ż╬źųźĒź├ź»ż╬├µż╦AIź│źóż“╠¾4762Ė─ĮĖ└čżĘż┐żĶż”żŪĪóAIź│źó┐¶ż“40╦³Ė─ĮĖ└čżĘż┐ż╚╔ĮĖĮżĘżŲżżżļĪŻ
AIĪóØŖż╦źŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░żŪż╩ż╝Īóż│żņż█ż╔¾Hż»ż╬▒ķōQź│źóż¼ØŁ═ūż╩ż╬ż½ĪŻź╦źÕĪ╝źĒź¾1Ė─ż╬źŌźŪźļĪ╩źčĪ╝ź╗źūź╚źĒź¾źŌźŪźļĪ╦żŽĪó¾HŲ■╬ü1Įą╬üż╬▒ķōQ▀_Ī╩ź╣źŲź├źū┤ž┐¶Ī╦żŪżóżĻĪóŲ■╬üż╦żŽ┐¶Ø▓Ė─ż╬źŪĪ╝ź┐ż╚ĪóżĮżņżŠżņż╦─_ż▀ż“²Xż▒Īó▒ķōQ▀_żŪ▒ķōQż╣żļĪŻ┐▐2żŽźóź╩źĒź░övŽ®żŪ╔ĮĖĮżĘż┐ż¼ĪóźŪźĖź┐źļövŽ®żŪżŌ╔ĮĖĮżŪżŁżļĪŻż─ż▐żĻĪóΣAiĪ▀Biż╚żżż”MACĪ╩└čŽ┬▒ķōQĪ╦żŪżóżļĪŻźŪĪ╝ź┐ż“Aiż╚ż╣żļż╚Īó─_ż▀żŽBiżŪ╔ĮĖĮżĄżņĪóżĮżņżķż“²Xż▒ōQżĘż┐±T▓╠ż“▒ķōQ▀_ż╦Ų■╬üż╣żļĪŻĮą╬üżŽ1ż½0żŪżóżļĪŻż│ż╬▒ķōQ▀_ż¼╩┬š`ż╦ż║żķżĻż╚╩┬ż¾żŪżżżļż╬ż¼ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż└ĪŻ
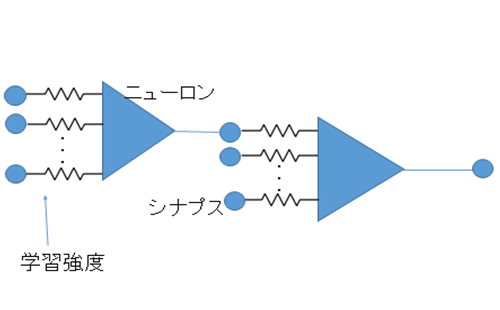
┐▐2ĪĪź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬┤╦▄┼¬ż╩ź╦źÕĪ╝źĒź¾źŌźŪźļ
ż│ż╬▒ķōQ▀_ż“¾H┐¶╩┬ż┘Īó║ŪĮ¬┼¬ż╦Įą╬üżĄżņż┐źŪĪ╝ź┐ż“╝Īż╬ź╦źÕĪ╝źĒź¾Ī╩▒ķōQ▀_Ī╦ż╦Ų■╬üż╣żļĪŻŪŁż“Ū¦╝▒ż╣żļŠņ╣ńż╦żŽĪóŪŁż½żĮż”żŪżŽż╩żżż½ż“┘ć▓“ż╬źŪĪ╝ź┐ż╚╚µ│ėżĘżŲ╚Įéāż╣żļż¼Īó╔į┘ć▓“ż╩żķĄš┼┴╚┬ż╚żżż’żņżļźąź├ź»źūźĒźąź▓Ī╝źĘźńź¾Š}╦Īż“╗╚żżĪóĮą╬üŖõż½żķŲ■╬üŖõż╦╠ßżĻż╩ż¼żķ─_ż▀ż“╩čż©żŲżżżŁĪóżŪżŁżļż└ż▒ŪŁż╚żżż”┘ć▓“ż╦ŖZ¤²ż»ż▐żŪ┴Ó║Ņż“Ę½żĻ╩ųż╣ĪŻ
ĘQź╦źÕĪ╝źĒź¾ż╦┴Ļ┼÷ż╣żļĮj╬╠ż╬▒ķōQ▀_żŽĮą╬üżĘż┐źŪĪ╝ź┐ż“źßźŌźĻż╦╩▌┘TżĘżŲż¬żŁĪó╝Īż╬▒ķōQ▀_ż╦Ų■╬üż╣żļ╗■ż╦Ų╔ż▀ĮążĘżŲ└čŽ┬ż“║Ų┼┘╝ŖōQż╣żļż┐żßĪóźŪźĖź┐źļövŽ®ż╚żĘżŲżŽMACż╚źßźŌźĻĪ╩DRAMĪ╦ż“żĮżąż╦ÅøżŁĪó▐kż─ż╬ź╦źÕĪ╝źĒź¾ż“▒ķōQżĘż┐ĖÕĪó▒ķōQ±T▓╠ż“źßźŌźĻż╦╩▌┘TżĘĪó╝Īż╬ź╦źÕĪ╝źĒź¾żžżĮż╬źßźŌźĻŲŌ═Ųż“Ų■╬üżĘżŲż▐ż┐▒ķōQż“╣įż”ĪŻżĘż½żŌ╩┬š`żŪ▒ķōQż╣żļĪŻż│ż╬ż┐żßĪóMACż╚źßźŌźĻż“×┤ż╚żĘżŲĘeż─╣Į└«ż¼AIź┴ź├źūż╬┤╦▄╣Į└«ż╚ż╩żļĪŻż│ż╬╗┼┴╚ż▀żŪżŽĪó▒ķōQż╚ĪóżĮż╬±T▓╠ż“╝Īż╬▒ķōQ▀_ż╦┼┴ż©żļ─╠┐«ĘąŽ®Īóż¼─_═ūż╩övŽ®═ū┴Ūż╚ż╩żļĪŻ╣ŌÅ]źßźŌźĻż╚▒ķōQź│źóżŽĖ▀żżż╦żĮżąż╦ÅøżŁĪóż│ż╬×┤ż“źóźņźżėXż╦«Ć╩┬š`ż╦Ū█Åøż╣żļĪŻ
Cerebrasż╬WSEż╦żŽ40╦³Ė─ż╬AIź│źóż“ĮĖ└čżĘżŲż¬żĻĪóżĮżņżķżŽ╣įš`└«╩¼ż╦0ż¼¾HżżšÅ╣įš`Ī╩sparse matrixĪ╦ż╚ż╩ż├żŲżżżļż┐żßĪóSLAĪ╩Sparse Linear AlgebrašÅ└■Ę┴┬Õ┐¶Ī╦ź│źóż¼Ų▒╝ęż╬ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬┤┴├ż╚ż╩ż├żŲżżżļĪŻź│źóżŽŠ«żĄż»Ī󟣟џ├źĘźÕźßźŌźĻż“┤▐ż▐ż║Īó┬Šż╬┤ž┐¶żõź¬Ī╝źąĪ╝źžź├ź╔żŌ┤▐ż¾żŪżżż╩żżĪŻż┐ż└żĘĪóSLAź│źóżŽźūźĒź░źķźÓ▓─ē”żŪżóżĻĪóź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬─_ż▀ż“śOĮyż╦╩čż©żķżņżļĪŻżĘż½żŌĪóĘQź│źóżŽöUĖµĮĶ═²ż╚źŪĪ╝ź┐ĮĶ═²ż╬╬ŠöĄż“╝┬╣įżŪżŁżļĪŻöUĖµĮĶ═²żŽ╩┬š`▒ķōQżŪżŁżļ║┬║Yż╚żĘżŲ╗╚ż’żņĪóźŪĪ╝ź┐ĮĶ═²żŽ▒ķōQżĮż╬żŌż╬ż╦╗╚ż’żņżļĪŻ
ż│ż╬ź┴ź├źūżŪżŽšÅ╣įš`ż╬²Xż▒ōQżŪĪó0ż“ż½ż▒żļ▒ķōQż¼¾Hż▒żņżą╠ĄŠGż╩▒ķōQż¼╗\ż©żļż│ż╚ż╦ż╩żļż┐żßĪóżĮżņż“Š╩ż»żĶż”ż╩ĮĶ═²ż“╣įż”ĪŻź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»żŪżŽĪóźŪĪ╝ź┐ż╬50~98%ż¼ź╝źĒż╦ż╩żļż│ż╚ż¼¾Hżżż¼Īóż│ż╬Šņ╣ńż╦żŽ²Xż▒ōQż“żĘż╩żżĪŻ
Cerebrasż╬WSEżŽ18GBż╬źßźŌźĻż╚9.6PB/sż╬źßźŌźĻźąź¾ź╔╔²ż“Ęeż─ĪŻżżż║żņżŌGPUż╚╚µż┘żŲ3000Ū▄Īó1╦³Ū▄¾Hżżż╚żżż”ĪŻźņźżźŲź¾źĘżŽ1źĄźżź»źļż╬ż▀żŪĪóµ£żŲż╬źŌźŪźļźčźķźßĪ╝ź┐żŽź¬ź¾ź┴ź├źūż╦Ęeż─ĪŻ
ż│ż╬WSEż╬żŌż”▐kż─ż╬ØŖ─╣żŽĪó╣ŌÅ]─╠┐«źšźĪźųźĻź├ź»żŪżóżļĪŻAIź┴ź├źūżŪżŽĪóMAC▒ķōQ▀_ż╬┐¶ż╚żĮż╬ź╣źįĪ╝ź╔ĪóżĮżĘżŲźšźņźŁźĘźėźĻźŲźŻż¼└Łē”ż“»éżßżļĪŻĘQź│źóżŽźņźżźõĪ╝┐¶ż╚Č”ż╦Š’ż╦Ų░║ŅżĘżŲż¬żĻĪó╣ŌÅ]ż╬źąź¾ź╔╔²ż╚─ŃźņźżźŲź¾źĘżŪŲ░║ŅżĄż╗żļż│ż╚ż│żĮ└Łē”ż“æųż▓żļźŁźŌż╚ż╩żļĪŻż│ż╬ż┐żßż╦ź│źóż“żęż╚╔wż▐żĻż╦żĘżŲź░źļĪ╝źūż╦ż╣żļĪŻ▐kż─ż╬źųźĒź├ź»ż╦AIź│źóż¼╠¾4700Ė─╔wżßżŲĮĖ└čżĘżŲżżżļż╬żŽżĮż╬ż┐żßż└ĪŻ
LSI╚ŠŲ│öüżŪżŽĪóź┴ź├źū│░ż╬─╠┐«żĶżĻżŌź┴ź├źūŲŌż╬─╠┐«ż╬öĄż¼┐¶╦³Ū▄żŌÅ]żżĪŻż└ż½żķż│żĮĪóŠ«żĄż╩ź┴ź├źūŲ▒╗╬ż“╠Jż╦żĘżŲż▐ż╚żßĪóEthernetżõInfiniBandĪóPCIeż╩ż╔żŪ─╠┐«żĄż╗żŲ└Łē”ż“│╬╩▌ż╣żļĪŻż└ż½żķĪó▐kż─ż╬ĄĮjż╩ź┴ź├źūż╦żĘż┐ĪŻ
CerebrasżŽĪóSwarmż╚Ō}żų─╠┐«źšźĪźųźĻź├ź»ż“│½╚»żĘĪóź┴ź├źūæųż╬Įj╬╠ż╬Ū█└■ź═ź├ź╚ź’Ī╝ź»ż“║ŅżĻĮążĘż┐ĪŻ40╦³Ė─ż╬AIź│źóżŽSwarm─╠┐«źšźĪźųźĻź├ź»żŪ2╝ĪĖĄźßź├źĘźÕėXż╦└▄¶öżĄżņżŲż¬żĻĪó100Pźėź├ź╚/╔├ż╚żżż”«Ć╣ŌÅ]ż╬źąź¾ź╔╔²ż“╝┬ĖĮżĘż┐ĪŻNvidiażŌ¾H┐¶ż╬Š«żĄż╩GPUź│źóż“╩┬ż┘ĪóżĮżņżķż“ż─ż╩ż░─╠┐«Ū█└■ż“╣®╔ūżĘżŲżżżļĪŻCerebrasż╬WSEżŪżŌź│źó┤ųżŽźņźżźŲź¾źĘż╚źąź¾ź╔╔²ż“║Ū┼¼▓ĮżĘż┐ø]żżŪ█└■żŪż─ż╩ż«ĪóĘQ▒ķōQź│źóż╦źŽĪ╝ź╔ź”ź©źóŪ█└■ź©ź¾źĖź¾ż“└▀ż▒żŲżżżļż╚żżż”ĪŻż│żņż╦żĶż├żŲĪó▐kż─ż╬Ė└±äż╬źßź├ź╗Ī╝źĖżŪź│źóż½żķź│źóĪóźņźżźõĪ╝ż½żķźņźżźõĪ╝żžż╚─╠┐«ż╣żļż│ż╚ż¼żŪżŁżļĪŻżĘż½żŌź│ź¾źšźŻź«źÕźóźķźųźļżŪźūźĒź░źķź▐źųźļż└ż╚żĘżŲżżżļĪŻSwarmżŽźŽĪ╝ź╔ź”ź©źóż╬Ū█└■ź©ź¾źĖź¾ż“źĮźšź╚ź”ź©źóżŪ║Ų╣Į└«▓─ē”ż╦żĘżŲż¬żĻĪóźµĪ╝źČĪ╝Ų╚śOż╬źŌźŪźļż╦╣ńż”żĶż”ż╦│žØ{ż╦ØŁ═ūż╩─╠┐«ż“╩čż©żļż│ż╚ż¼żŪżŁżļż╚żĘżŲżżżļĪŻż│ż╬±T▓╠Īó▐kż─ż╬źŽĪ╝ź╔ź”ź©źóźĻź¾ź»ż“źßź├ź╗Ī╝źĖż¼─╠żļŠņ╣ńż╬źņźżźŲź¾źĘżŽ┐¶ź╩ź╬╔├żŪż╣żÓż╚żżż”ĪŻ
ż│żņż└ż▒ż╬WSEżŪżóżņżąŠ├õJ┼┼╬üżŽż½ż╩żĻ╣ŌżżżŽż║ż└ż¼ĪóCerebrasżŽŠ├õJ┼┼╬üż╦┤žżĘżŲżŽ▓┐żŌź│źßź¾ź╚ż“ĮążĘżŲżżż╩żżĪŻż┐ż└Īó└╬ż╚░Ńż├żŲĪóź╣Ī╝źčĪ╝ź│ź¾źįźÕĪ╝ź┐żŪżŽ┐Õ╬õżŪź┴ź├źūż“╬õĄčż╣żļŠ}╦Īż¼─ĻŠÆżĘżŲż¬żĻĪóż│ż╬ĄĮjż╩ź┴ź├źūżŌ╬õĄčē”╬üż╬╣Ōżż┐Õ╬õż“ŠW├ōż╣żļż╦░Ńżżż╩żżĪŻ
ż½ż─żŲż╬WSIżŽ±TČ╔ĪóŠ”ēäż╦ż╩żĻż©ż╩ż½ż├ż┐ĪŻ╩Ōé╬ż▐żĻż¼╬╔ż»ż╩żķż╩ż½ż├ż┐ż┐żßż└ĪŻżĘż½żŌ├ō²ŗż¼źßźŌźĻżŪżóżĻĪóź│ź╣ź╚ż“▓╝ż▓żķżņż╩ż½ż├ż┐ĪŻ║Żövż╬ź┴ź├źūż¼źŌź╬ż╦ż╩żļż½ż╔ż”ż½żŽźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╬│žØ{ęŖ═ūż╦żĶżļż¼Īó└Łē”ż¼ź▒ź┐░Ńżżż╦╬╔ż»ż╩żļż│ż╚ż└ż▒żŽ│╬ż½żŪżóżļĪŻ
╗▓╣═½@╬┴
1. Cerebras╝ęż╬ź█Ī╝źÓź┌Ī╝źĖ

