║Ūäėż╬AIźūźĒź╗ź├źĄż“ź”ź¦Ī╝źŽź¬ź¾ź”ź¦Ī╝źŽżŪ╝┬ĖĮżĘż┐Graphcore
▒č╣±ż╬AIźūźĒź╗ź├źĄźßĪ╝ź½Ī╝ż╬Graphcore╝ęż¼āįĄŅż╦Šę▓żĘż┐IPUĪ╩Intelligent Processor UnitĪ╦×æēäĪ╩╗▓╣═½@╬┴1Ī╦żĶżĻżŌ└Łē”ĀCżŪ40%╣Ōż»Īó┼┼╬üĖ·╬©żŌ16%╣Ōżż┐ĘĘ┐AIź┴ź├źūż“│½╚»żĘż┐ĪŻ║ŪĮjż╬ØŖ─╣żŽĪóWafer-on-waferżŪź┴ź├źūż“Ę┴└«żĘż┐ż│ż╚ż└ĪŻŲ▒╝꿎ĪóBow IPUż╚ć@¤²ż▒żķżņż┐ź┴ź├źūĪ╩┐▐1Ī╦ż½żķ│╚─ź└Łż╬╣ŌżżAIź│ź¾źįźÕĪ╝ź┐ż▐żŪ║ŅżĻæųż▓ż┐ĪŻ

┐▐1ĪĪŪ█└■┴žż“ź”ź¦Ī╝źŽź╣ź┐ź├ź»żŪĘ┴└«żĘż┐BOW IPUźūźĒź╗ź├źĄĪĪĮąųZĪ¦Graphcore
ż│ż╬AIź┴ź├źūżŽĪó┼┼Ė╗┴žż╬ź”ź¦Ī╝źŽż╚ĪóAIźūźĒź╗ź├źĄövŽ®ż╬ź”ź¦Ī╝źŽż“─źżĻ╣ńż’ż╗żļż│ż╚żŪĪó┼┼Ė╗ż½żķźūźĒź╗ź├źĄżõźßźŌźĻż▐żŪż╬š{▀`ż“ø]Į╠żĘĪó╣ŌÅ]Ų░║Ņż╚─ŃŠ├õJ┼┼╬üż“├Ż└«żĘż┐żŌż╬Ī╩┐▐2Ī╦ĪŻ
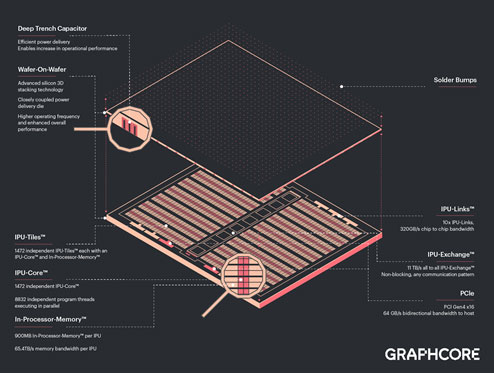
┐▐2ĪĪ┼┼Ė╗Ū█└■┴žż╬ź”ź¦Ī╝źŽĪ╩æųĪ╦ż╚AIź”ź¦Ī╝źŽĪ╩▓╝Ī╦ż“─źżĻ¤²ż▒ĪĪĮąųZĪ¦Graphcore
AIźūźĒź╗ź├źĄż╬ź╚źķź¾źĖź╣ź┐ŗż╬ź”ź¦Ī╝źŽżŽĪóØiöv╚»╔ĮżĘż┐IPUź┴ź├źūż╚Ė▀┤╣└Łż╬żóżļź┴ź├źūźóĪ╝źŁźŲź»ź┴źŃżŪĪóIPUź│źó┐¶żŽ1472Ė─Īóź╣źņź├ź╔┐¶żŽ8800Ė─░╩æųĪóźżź¾źūźĒź╗ź├źĄźßźŌźĻżŽ900MBż╚ż╩ż├żŲżżżļĪŻ┼┼Ė╗ČĪĄļźķźżź¾ż¼żŌż”▐kż─ż╬ź”ź¦Ī╝źŽżŪżóżĻĪóż│ż│ż╦┼┼Ė╗Ū█└■┴žż╚ĪóźŪźŻĪ╝źūź╚źņź¾ź┴żŪźŁźŃźčźĘź┐┴žż“Ę┴└«żĘżŲż¬żĻ(┐▐3)Īóź╬źżź║Į³ĄŅżõ┼┼▓┘Ą█╝²ż╩ż╔┼┼Ė╗ż╦ØŁ═ūż╩ź│ź¾źŪź¾źĄż╬╠“│õż“▓╠ż┐ż╣ĪŻ
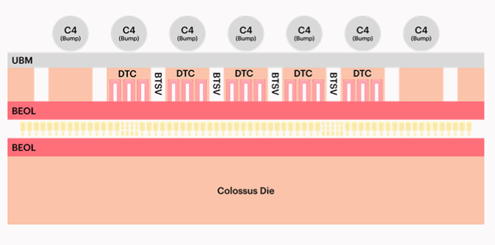
┐▐3ĪĪæųż╬┼┼Ė╗┴žź”ź¦Ī╝źŽżŽ╬óĀCTSVĪ╩BTSVĪ╦ż╦żĶż├żŲźŪźŻĪ╝źūź╚źņź¾ź┴źŁźŃźčźĘź┐Ī╩DTCĪ╦ż“Ę┴└«żĘżŲżżżļĪĪĮąųZĪ¦Graphcore
┼┼Ė╗źķźżź¾ż½żķźūźĒź╗ź├źĄżõźßźŌźĻż╚ø]żżš{▀`żŪ─Š±TżŪżŁżļż┐żßĪó┼┼╬üĖ·╬©ż¼æųż¼żĻĪóżĮż╬±T▓╠ĪóAI└Łē”ż¼350 Tera FLOPSż╚Øi└ż┬Õż╬ź┴ź├źūżĶżĻżŌ40%╣Ōż▐ż├ż┐ĪŻźšźĪźųźņź╣ż╬AIź┴ź├źūźßĪ╝ź½Ī╝żŪżóżļGraphcoreżŽĪóTSMCż╚Č”Ų▒żŪĪó╬óĀCż╬TSVĪ╩Backside Through Silicon ViaĪ╦ż╚ź”ź¦Ī╝źŽź¬ź¾ź”ź¦Ī╝źŽźŽźżźųźĻź├ź╔ź▄ź¾źŪźŻź¾ź░ż“│½╚»żĘżŲżŁż┐ĪŻ┼┼Ė╗źķźżź¾Ī╩Power DeliveryĪ╦Č\Į迎ż│żņż½żķż╬╚ŠŲ│öüż╦ż╚ż├żŲ─_═ūż╩Č\Įčż╚ż╩żĻżĮż”ż└ĪŻ
ź┴ź├źūż“4Ė─┼ļ║▄żĘż┐IPUź▐źĘź¾ĪųBOW-2000Īūż“┤╦▄├▒░╠ż╚żĘżŲĪóBOW-2000ż“4±śź╣ź┐ź├ź»żĘĪóCPUźĄĪ╝źąĪ╝1±ś└▀ż▒ż┐AIź│ź¾źįźÕĪ╝ź┐BOW POD16ż½żķĪóBOW POD16ż“4ź╣ź┐ź├ź»ż╚1~4±śż╬CPUźĄĪ╝źąĪ╝ż“└▀ż▒ż┐ź│ź¾źįźÕĪ╝ź┐źķź├ź»BOW POD64ż“┤╦▄źķź├ź»ż╚żĘżŲ4źķź├ź»Īó16źķź├ź»ż╚żżż”ź│ź¾źįźÕĪ╝ź┐źĘź╣źŲźÓż▐żŪ│╚─źżŪżŁżļĪ╩┐▐4Ī╦ĪŻ

┐▐4ĪĪź┴ź├źū4Ė─ż╬║ŪŠ«╣Į└«ż╬BOW-2000żŽ1024±śż▐żŪ│╚─źżŪżŁżļĪĪĮąųZĪ¦Graphcore
└Łē”żŽIPUż“│╚─źż╣żņżąż╣żļż█ż╔╣Ōż»ż╩ż├żŲż¬żĻĪóżŌżŽżõźóźÓź└Ī╝źļż╬╦Īō¦żŽ┤░µ£ż╦╩°żņżŲżżżļĪŻż│ż╬╦Īō¦żŽĪóżóżļŠ“°PżŪżŽźūźĒź╗ź├źĄż“╩┬š`ż╦Ų░║ŅżĄż╗żŲżŌ┐¶Ė─~10Ė─żŪČÉŽ┬żĘżŲżĘż▐ż”ż╚1960ŃQ┬Õż╦─¾░ŲżĄżņż┐╦Īō¦ĪŻAIźūźĒź╗ź├źĄż└ż▒żŪżŽż╩ż»Īóź╣Ī╝źčĪ╝ź│ź¾źįźÕĪ╝ź┐Īų╔┘▀tĪūżŪżŌ«Ć╩┬š`╝ŖōQż¼▓─ē”ż╦ż╩ż├żŲżżżļĪŻ
ż╣żŪż╦ä▌╣±ź©ź═źļź«Ī╝Š╩Ī╩DoEĪ╦╗▒▓╝ż╦żóżļPNNLĪ╩źčźĘźšźŻź├ź»ź╬Ī╝ź╣ź”ź¦ź╣ź╚╣±╬®Ė”ē|ĮĻĪ╦żŪźĄźżźąĪ╝ź╗źŁźÕźĻźŲźŻż╬ĖĪĮążõ╝ŖōQ▓Į│žż╩ż╔żŪ╗╚ż├żŲżżżļĪŻż│ż”żżż├ż┐¾H╩č╬╠▓“└Žż╬╩¼╠ŅżŪżŽź░źķźš═²ébż“ź┘Ī╝ź╣ż╦żĘżŲżżż┐ż¼Īóż│ż│ż╦ĄĪ│Ż│žØ{ż“╗╚ż©żļżĶż”ż╦ż╣żļź░źķźšź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż¼ÅRų`żĄżņżļżĶż”ż╦ż╩ż├żŲżŁż┐ĪŻŲ▒Ė”ē|ĮĻż╬Č”Ų▒źŪźŻźņź»ź┐ż╬Sutanay ChoudhuryĢ■żŽĪóĪųGraphcoreż╬źĘź╣źŲźÓżŽĪó│žØ{Īó┐õébż╚żŌ┐¶Ų³ż½ż½ż├żŲżżż┐╠õ¼öż“┐¶╗■┤ųżŪ║čż▐ż╗żļż│ż╚ż¼żŪżŁż┐Īūż╚ź│źßź¾ź╚żĘżŲżżżļĪŻ
Graphcoreż╬ų`╗žż╣żŌż╬żŽ±TČ╔Īó┐═┤ųż╬Ų¼╦NżŪżóżļĪŻ╦Nż╦żŽ╠¾1000▓»Ė─ż╬ź╦źÕĪ╝źĒź¾Ī╩┐└Ęą║┘╦”Ī╦ż╚100├¹Ė─ż╬źčźķźßĪ╝ź┐ż¼żóżļĪŻĖĮ║▀║ŪĮjż╬AIźŌźŪźļżŽż▐ż└1├¹źčźķźßĪ╝ź┐żĘż½ż╩żżż¼ĪóGraphcoreżŽĪó┐═┤ųż╬Ų¼╦Nż╬źčźķźßĪ╝ź┐ż“«Ćż©żļAIź│ź¾źįźÕĪ╝ź┐ż“│½╚»├µżŪżóżļż╚żżż”ĪŻ2024ŃQż▐żŪż╦ż│ż╬Goodź│ź¾źįźÕĪ╝ź┐Ī╩GoodżŽ┐═╬Óż╬Ų¼╦Nż“«Ćż©żļź▐źĘź¾ż“éb╩Ė╚»╔ĮżĘż┐Jack GoodĢ■ż╦żĶżļĪ╦ż╚Ō}żų«Ćźżź¾źŲźĻźĖź¦ź¾ź╚ż╩AIź│ź¾źįźÕĪ╝ź┐ż“╚»╔Įż╣żļ╝Ŗ▓ĶżŪżóżļĪŻ
╗▓╣═½@╬┴
1. Īų└Łē”ż╚│╚─ź└Łż╬╣ŌżżMIMDźóĪ╝źŁźŲź»ź┴źŃż╬AIź┴ź├źūżŪ▒M╔ķż╣żļGraphcoreĪūĪóź╗ź▀ź│ź¾ź▌Ī╝ź┐źļ (2021/10/12)

