IntelĪóŗī4└ż┬Õż╬XeonźūźĒź╗ź├źĄżŪÅŚĘxövÖ┌ż╩żļż½Īó3D-IC/EMIBżŪ«Ć╣ŌĮĖ└č
Intelż¼żĶż”żõż»ź│Ī╝ź╔ć@ĪųSapphire RapidsĪūż╬CPUż“ŗī4└ż┬Õż╬Xeonź╣ź▒Ī╝źķźųźļźūźĒź╗ź├źĄż╚żĘżŲ╬╠ŠÅż╦ż│ż«ż─ż▒ż┐ĪŻ4Ė─ż╬CPUź└źżż“EMIBĪ╩Embedded Multi-die Interconnect BridgeĪ╦żŪ└▄¶öżĘż┐Xeonź╣ź▒Ī╝źķźųźļCPUż╦▓├ż©ĪóICźčź├ź▒Ī╝źĖŲŌż╦HBMźßźŌźĻż“ĮĖ└čżĘż┐Xeon CPU MAXźĘźĻĪ╝ź║ż╚GPU MAXźĘźĻĪ╝ź║Ī╩ź│Ī╝ź╔ć@Ponte VecchioĪ╦żŌŲ▒╗■ż╦╚»╔ĮżĘż┐ĪŻ

┐▐1ĪĪŗī4└ż┬Õż╬Intel Xeonź╣ź▒Ī╝źķźųźļźūźĒź╗ź├źĄĪĪĮąųZĪ¦Intel
ż│ż╬ŗī4└ż┬Õż╬źūźĒź╗ź├źĄż“IntelżŽĪó╝┬║▌ż╬ĖĮŠņżŪ╗╚ż”ź’Ī╝ź»źĒĪ╝ź╔ż“║Ū═ź└ĶżĘż┐ż╚ĖņżĻĪóź’Ī╝ź»źĒĪ╝ź╔ż╬└Łē”ż¼SPECintż╩ż╔ż╬ź┘ź¾ź┴ź▐Ī╝ź»źŲź╣ź╚żŪż╬└Łē”ż╚żŽ░█ż╩żļż│ż╚ż“┐āżĘż┐Ī╩┐▐2)ĪŻż─ż▐żĻż│żņż▐żŪż╚żŽ░ŃżżĪóĪų└@├ōĪūż╬CPUżŪżŽż╩ż»Īó╝┬║▌ż╬ź’Ī╝ź»źĒĪ╝ź╔└Łē”ż“═ź└ĶżĘż┐ĪųØŹ└ņ├ō┼¬Īūż╩źūźĒź╗ź├źĄż╦╗┼æųż▓ż┐ĪŻ
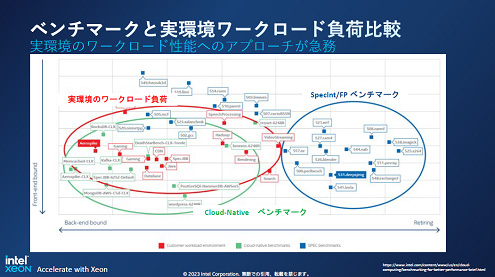
┐▐2ĪĪź┘ź¾ź┴ź▐Ī╝ź»żŪż╬└Łē”ż╚╝┬╗╚├ōżŪż╬└Łē”żŽĮjżŁż»░Ńż├żŲżŁż┐ĪĪĮąųZĪ¦Intel
żĮż╬ż┐żßż╦ĪóCPUź│źóż╦▓├ż©żŲĪóĘQ╩¼╠Ņż╬źóź»ź╗źķźņĪ╝ź┐żŌĮĖ└čżĘż┐Ī╩┐▐3Ī╦ĪŻż─ż▐żĻĪó└@├ōż╬CPUż╦ĪóAIĪó─╠┐«ź═ź├ź╚ź’Ī╝ź»Īóź╣ź╚źņĪ╝źĖĪóźŪĪ╝ź┐ź╗ź¾ź┐Ī╝ĪóHPCĪ╩High Performance ComputingĪ╦ż╦ØŖ▓ĮżĘż┐źóź»ź╗źķźņĪ╝ź┐ż“▓├ż©ż┐ĪŻĘQ╩¼╠Ņż╦┼¼żĘż┐×æēäźĘźĻĪ╝ź║ż“─¾ČĪż╣żļĪŻ╬Ńż©żąĪóAIĪ╩ĄĪ│Ż│žØ{Ī╦żŪżŽAMXĪ╩Advanced Matrix ExtensionsĪ╦ż╚Ō}żųźóź»ź╗źķźņĪ╝ź┐ż“┼ļ║▄żĘżŲż¬żĻĪóCPUż╬▒ķōQ╔ķ▓┘ż“Ę┌ż»ż╣żļĪŻż│ż╬źóź»ź╗źķźņĪ╝ź┐żŽTensorFlowżõPyTorchż╩ż╔ż╬Ė└Ėņż“źĄź▌Ī╝ź╚ż╣żļĪŻ5G┤├ŽČ╔ż╩ż╔ż╬─╠┐«ź═ź├ź╚ź’Ī╝ź»żŪżŽĪóVirtual RANĖ■ż▒ż╬AVXĪ╩Advanced Vector ExtensionsĪ╦źóź»ź╗źķźņĪ╝ź┐ż“╗╚ż”ĪŻźĮźšź╚ź”ź©źó─Ļ▒Iż╬ź═ź├ź╚ź’Ī╝ź»żŪ╗╚ż’żņżļźŪĪ╝ź┐źūźņĪ╝ź¾Ė■ż▒ż╬źĮźšź╚ź”ź©źó│½╚»├ōż╬│½╚»źŁź├ź╚Ī╩DPDKĪ╦ż“├ō┴Tż╣żļĪŻź╣ź╚źņĪ╝źĖźĘź╣źŲźÓż½żķż╬źóź»ź╗ź╣ż╦żŽDSAĪ╩Data Storage AcceleratorĪ╦źóź»ź╗źķźņĪ╝ź┐ż╩ż╔ż“ŠW├ōżŪżŁżļĪŻ
├µżŪżŌAIĄĪē”żŽźŪĪ╝ź┐ź╗ź¾ź┐Ī╝żŪżŌHPCżŪżŌź©ź├źĖżŪżĄż©żŌ╗╚ż’żņżļż┐żßĪó╝┬┤─ČŁżŪż╬źūźĒź╗ź├źĄżŪżŽAIźŌźŪźļż╬ĮjŠ«żŽżóżļżŌż╬ż╬Īó══Ī╣ż╩├ō²ŗżŪ╗╚ż’żņżļżĶż”ż╦ż╩ż├żŲżŁż┐ĪŻż│ż╬ż┐żßĪó║ŪŖZż╬CPUżõSoCż╦żŽ¾Hż½żņŠ»ż╩ż½żņĪóAIĪ╩ĄĪ│Ż│žØ{Ī╦ĄĪē”ż¼┼ļ║▄żĄżņżļżĶż”ż╦ż╩żĻż─ż─żóżĻĪó║Żövż╬XeonźūźĒź╗ź├źĄżŪżŌAI└ņ├ōźóź»ź╗źķźņĪ╝ź┐ż¼ĮĖ└迥żņż┐ĪŻ

┐▐3ĪĪAIżõ5G─╠┐«ź═ź├ź╚ź’Ī╝ź»Īóź╣ź╚źĻĪ╝ź▀ź¾ź░ż╩ż╔├ō²ŗż┤ż╚ż╬źóź»ź╗źķźņĪ╝ź┐ż“ĮĖ└čżĘż┐ĪĪĮąųZĪ¦Intel
żĮżĘżŲ╝■╩šövŽ®ż╦żŽ║Ū╣ŌÅ]ż╬DDR5źßźŌźĻ×┤▒■żõĪóPCIe5.0ż╬╣ŌÅ]źĘźĻźóźļźżź¾ź┐Ī╝źšź¦źżź╣Īó╣ŌÅ]źßźŌźĻĖ■ż▒ż╬CXL 1.1╝Ī└ż┬ÕI/Oż╩ż╔ż╬źżź¾ź┐Ī╝źšź¦źżź╣żõ║ŪĮj64GBż╬HBM2eźßźŌźĻż“┼ļ║▄żĘżŲżżżļĪŻ
║ŻövĪóXeon ź╣ź▒Ī╝źķźųźļźūźĒź╗ź├źĄż╦▓├ż©żŲĮą▓┘żĘ╗Žżßż┐Xeon MAXźĘźĻĪ╝ź║ż╦żŽĪóHBM2eźßźŌźĻż“ICźčź├ź▒Ī╝źĖŲŌż╦ŲŌē┼żĘżŲżżżļĪŻż│ż╬×æē俎ź╣Ī╝źčĪ╝ź│ź¾źįźÕĪ╝ź┐żõźŪĪ╝ź┐ź╗ź¾ź┐Ī╝ż╩ż╔ż╬HPCĪ╩High Performance ComputingĪ╦Ė■ż▒ż╬×æēäźĘźĻĪ╝ź║żŪżóżļĪŻ
żĮżņżŠżņż╬ź┴ź├źūż╬źóĪ╝źŁźŲź»ź┴źŃżŽ┐▐4ż╬żĶż”ż╦╣Į└«żĄżņżŲżżżļĪŻŗī4└ż┬Õż╬Xeonź╣ź▒Ī╝źķźųźļźūźĒź╗ź├źĄż╦żŽ3¹|╬ÓżóżĻĪóźŌź╬źĻźĘź├ź»ż╩CPUż╬MCCźĘźĻĪ╝ź║ż╚Īó4ź┐źżźļż╬CPUż“EMIBżŪ└▄¶öżĘż┐XCCĪ󿥿ķż╦ż│ż╬XCCż╦HBMż“4Ė─┼ļ║▄żĘż┐×æēäż¼MAXźĘźĻĪ╝ź║żŪżóżļĪŻXCCżŽ║ŪĮj60Ė─ż╬CPUź│źóż½żķż╩żļĪŻ
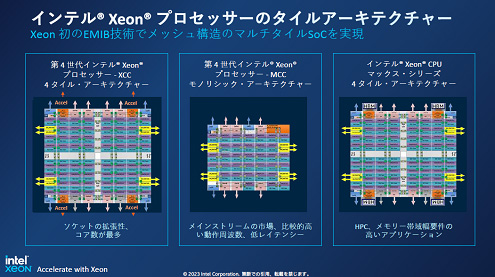
┐▐4ĪĪŗī4└ż┬ÕIntel Xeonź╣ź▒Ī╝źķźųźļźūźĒź╗ź├źĄż╦żŽ3¹|╬ÓĪĪ║Ėż╚īÜż╬XCC×æēäż╚MAXźĘźĻĪ╝ź║żŽ4ź┴ź├źūźņź├ź╚ż“EMIBĪ╩Ū“żżŪ█└■ŗ╩¼Ī╦żŪ└▄¶öżĘżŲżżżļĪĪĮąųZĪ¦Intel
ż│żņżķż╬CPUż╦▓├ż©żŲ╚»╔ĮżĘż┐ĪóźŪĪ╝ź┐ź╗ź¾ź┐Ī╝Ė■ż▒ż╬GPUż╬MAXźĘźĻĪ╝ź║żŽź│Ī╝ź╔ć@Ponte Vecchioż╚ć@¤²ż▒żķżņĪó└Ķ├╝źčź├ź▒Ī╝źĖČ\ĮčżŪ║ŅżķżņżŲżżżļĪŻż│ż╬GPUżŽĪóIntelż╬3D-ICČ\ĮčżŪżóżļFoverosČ\Įčż╚Īó2.5DżŪ╩┐ĀCæųż╦żóżļź┴ź├źūĪ╩ź└źżĪ╦Ų▒Ģ■ż“└▄¶öż╣żļż┐żßż╬EMIBż“╗╚ż├żŲź┴ź├źūźņź├ź╚Ī╩IntelżŽź┐źżźļż╚Ō}ż¾żŪżżżļĪ╦ż“└▄¶öżĘżŲżżżļĪŻ╣ń╝Ŗ1000▓»ź╚źķź¾źĖź╣ź┐ż½żķż╩żĻĪóźóź»źŲźŻźųż╩ź┴ź├źūźņź├ź╚ż¼47Ė─ĪóFoverosŠW├ōż╬ź╣ź┐ź├ź»żĘż┐ź└źżż¼16Ė─ĪóEMIBż¼11Ė─┼ļ║▄żĄżņżŲżżżļĪŻEMIBżŽĪóźĘźĻź│ź¾źżź¾ź┐Ī╝ź▌Ī╝źČż╚░ŃżżĪóźĘźĻź│ź¾µ£ĀCż“╗╚ż’ż║Īó║ŲŪ█└■┴žż╚┼┼Č╦źčź├ź╔ż“×óż©ż┐ź┴ź├źūŲ▒╗╬ż╬└▄¶öż└ż▒ż“ų`┼¬ż╚ż╣żļŠ«żĄż╩║ŲŪ█└■┴žż╬źĘźĻź│ź¾ź└źżżŪżóżļĪŻ
Ų³╦▄▌xŠņżŪżŽĪó»B┼įĮj│žż¼ź╣Ī╝źčĪ╝ź│ź¾źįźÕĪ╝ź┐ż╦Xeon MAXźĘźĻĪ╝ź║Īó├▐āSĮj│žż¼Xeonź╣ź▒Ī╝źķźųźļźūźĒź╗ź├źĄż╚OptaneźßźŌźĻż“Ų│Ų■ż╣żļż│ż╚ż“»éżßż┐ĪŻż▐ż┐ĪóNvidiaż½żķżŌĪó“£═Ķż╬źŪĪ╝ź┐ź╗ź¾ź┐Ī╝ż╬źĄĪ╝źążĶżĻżŌ25Ū▄żŌ╣Ō└Łē”ż╩Nvidia DGX H100ż╦żŽNvidiaż╬Tensor Core GPUż“öUĖµż╣żļŗī4└ż┬Õż╬Xeon ź╣ź▒Ī╝źķźųźļźūźĒź╗ź├źĄż¼┼ļ║▄żĄżņżļżĶż”ż╦ż╩żļĪóż╚żżż”╚»╔Įż¼żóż├ż┐Ī╩╗▓╣═½@╬┴1Ī╦ĪŻNvidiaż╬H100źĄĪ╝źą60±ś░╩æųż╦Xeonź╣ź▒Ī╝źķźųźļźūźĒź╗ź├źĄż¼╗╚ż’żņżļĪŻIntelż╬źūźĒź╗ź├źĄż╚Nvidiaż╬GPUż╬┴╚ż▀╣ńż’ż╗żŪH100źĄĪ╝źążŽ“£═Ķż╬CPUż└ż▒ż╬źŪĪ╝ź┐ź╗ź¾ź┐Ī╝źĄĪ╝źąż╚╚µż┘Īóź©ź═źļź«Ī╝Ė·╬©żŽ3.5Ū▄ĪóTCOĪ╩µ£▒┐├ōź│ź╣ź╚Ī╦1/3░╩▓╝ż╦ż╩żļż╚Ė½└čżŌżķżņżŲżżżļĪŻ
╗▓╣═½@╬┴
1. "The Greenest Generation: NVIDIA, Intel and Partners Supercharge AI Computing Efficiency", Nvidia (2023/01/10)

