źóĪ╝źÓ╝ęż¼ŠÆ╝┬ż╦▌xŠņż“│╚Įjż╣żļż┐żßįÆż─ż╬┐Ę×æēäż“ARM Forum 2010żŪ╚»╔Į
║ŪĮjŠ}ż╬IPź┘ź¾ź└Ī╝żŪżóżļ▒č╣±ż╬źóĪ╝źÓ╝꿎ARM Forum 2010ż“11ĘŅ11Ų³ż╦│½╠¢Īó┐Ę×æēäż“įÆż─╚»╔ĮżĘż┐ĪŻż│ż╬ż”ż┴źŽźżź©ź¾ź╔ż╬ź░źķźšźŻź├ź»ź╣IPżŪżóżļMali-T604ź░źķźšźŻź├ź»ź╣źūźĒź╗ź├źĄż╦┤žżĘżŲżŽĄŁŪv▓±Ė½ż“│½żżż┐ż┐żßĪóż╣żŪż╦╩¾╠OżĘż┐źßźŪźŻźóżŌżóżļĪŻ╝┬║▌ż╦Īų║Żöv╚»╔ĮżĘż┐┐Ę×æē俎įÆż─żóżļĪūĪ╩Ų▒╝ęCOOż╬Graham BuddĢ■Ī╦ĪŻ
┐▐1ĪĪź░źķźšźŻź├ź»ź╣ĄĪē”żžż╬═ūĄßżŽ¶öż»
żĶżĻ└Łē”ż“æųż▓ż┐ż╬ż¼GPUĪ╩ź░źķźšźŻź├ź»ź╣źūźĒź╗ź├źĄźµź╦ź├ź╚Ī╦Mali-T604żŪżóżļż¼Īó╗─żĻż╬Ų¾ż─żŽĪóź▐źļź┴ź│źóż╦żĶżļ╩┬š`ĮĶ═²ż“ź╣źÓĪ╝ź║ż╦╣įż”żõż╣ż»ż╣żļż┐żßż╬źąź╣źżź¾ź┐Ī╝ź│ź═ź»ź╚żŪżóżļCoreLinkĪóżĮżĘżŲر═²IPż╚żĘżŲ║Ū┼¼▓ĮżĘż┐Cortex-A9ż“║Żż╣ż░źĘźĻź│ź¾ż╦źżź¾źūźĻźßź¾ź╚ż╣żļż┐żßż╬źčź├ź▒Ī╝źĖPOPĪ╩źūźĒź╗ź├źĄ║Ū┼¼▓Įźčź├ź»Ī╦źĄĪ╝źėź╣ĪóżŪżóżļĪŻ3Ī┴5ŃQĖÕż╬ź╣ź▐Ī╝ź╚źšź®ź¾żõź┐źųźņź├ź╚żžż╬▒■├ōż“╣═ż©ż┐×æēäż╚żĘżŲżŽĪóMali-T604ż╚CoreLinkĪó║Żż╣ż░ź┐źųźņź├ź╚ż“Įą▓┘ż╣żļż┐żßż╬SoCż“║ŅżĻż┐żżĪóż╚╣═ż©żļźµĪ╝źČĪ╝ż╦żŽPOPźĄĪ╝źėź╣ż╬ŠW├ōż¼▓─ē”żŪżóżļĪŻżżż║żņżŌ“£═Ķż╬źóĪ╝źÓ╝ęż╬Ė▄Ąęż╬Ž╚ż“╣Łż▓Īó┐¶ŃQ└Ķż╬×æēäż½żķ║Żż╣ż░╗╚ż©żļ×æēäż▐żŪź½źąĪ╝żŪżŁżļżĶż”ż╦╣Łż▓żŲżżżļĪŻ
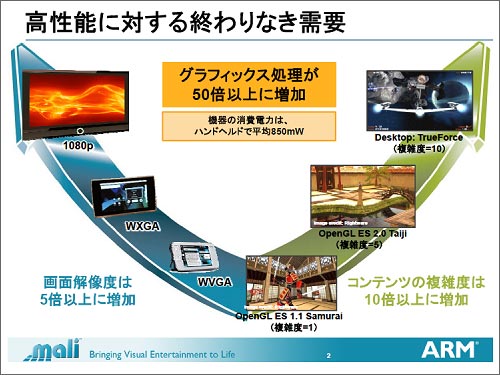
×æēä╚»╔ĮżĘż┐Mali-T604żŽ▓╠żŲżĘż╩żżź░źķźšźŻź├ź»ź╣└Łē”żžż╬═ūĄßż╦▒■ż©żļż┐żßż╬IPż└ĪŻŲ▒╝ęźßźŪźŻźóźūźĒź╗ź├źĘź¾ź░ŗ╠ń×æēäź▐ź═Ī╝źĖźŃĪ╝ż╬Steve SteeleĢ■ż╦żĶżļż╚Īó“£═Ķż╬Ę╚┬ėżõź╣ź▐Ī╝ź╚źšź®ź¾ż╚╚µż┘▓“ćĄ┼┘żŽWVGAż½żķHDēä䮿╬1080pż╚╚µż┘5Ū▄░╩æųż╦╗\▓├żĘĪ󿥿ķż╦OpenGL ES1.1żŪ└▀╝ŖżŪżŁżļµć┼┘ż╬ź│ź¾źŲź¾ź─ż½żķ║Żż╬═ūĄßżŽżĮż╬10Ū▄ż╬╩Ż╗©żĄż╦├ŻżĘżŲżżżļż╚żżż”ĪŻżĘż½żŌĘ╚┬ėĄĪ▀_ż╦╗╚ż”ż│ż╚ż“╣═╬Ėż╦Ų■żņżļż╚Īóźčź’Ī╝źąźĖź¦ź├ź╚ż╚żĘżŲżŽ╩┐Čč850mW░╩▓╝ż╦═▐ż©żļØŁ═ūż¼żóżļĪŻ
Š├õJ┼┼╬üż“æųż▓ż║ż╦└Łē”ż“æųż▓żļż┐żßĪóźóĪ╝źÓżŽź▐źļź┴ź│źóżžż╬│╚─ź└Łż“æųż▓żļż┐żßż╬ź│ź¾źįźÕĪ╝źŲźŻź¾ź░Š}╦Īż╬╣®╔ūż╚Īóź░źķźšźŻź├ź»ź╣▓ĶĀCż“╔Į┐āż╣żļż┐żßż╬źņź¾ź└źĻź¾ź░ż“╣®╔ūżĘż┐ĪŻ
┐▐2ĪĪMali-T604GPUź│źóż╬┤╦▄źóĪ╝źŁźŲź»ź┴źŃ
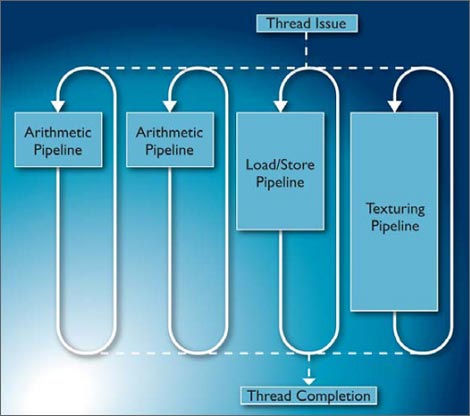
ź│ź¾źįźÕĪ╝źŲźŻź¾ź░ē”╬üż“æųż▓żļż┐żßĪóźĘź¾ź░źļż╬GPUź│źóż╬├µż╦3¹|╬Óż╬źčźżźūźķźżź¾╣Įļ]ż“ż╚żĻĪó└Łē”ż“æųż▓żļż╚Č”ż╦źšźņźŁźĘźėźĻźŲźŻżŌæųż▓żļ└▀╝Ŗż“║╬ż├żŲżżżļĪŻżĮżĘżŲ║Ū┐Ę▒įż╬źūźĒź╗ź├źĄź│źóżŪżóżļCortex-A15ż╚GPUĪóżĮżĘżŲźßźŌźĻĪ╝ż“Ė·╬©żĶż»źņźżźŲź¾źĘż“Š»ż╩ż»╩▌ż─ż┐żßż╦┐Ę×æēäCoreLinkźąź╣żŪ└▄¶öż╣żļĪŻź░źķźšźŻź├ź»ź╣ĄĪē”ż“æųż▓żļż┐żßĪóŲ▒╗■ż╦▓ĶĀCæųż╬Īų│©ĪūżõĪų▒ŲĪūż“┼╔żĻż─żųż╣ż┐żßż╬źĘź¦Ī╝ź└Ī╝ź│źóż“4Ė─╩┬š`ż╦Ų░║ŅżĄż╗żļĪŻżĮżņżķż╬ź│źóżŪ╝┬╣įż╣ż┘żŁź┐ź╣ź»ż“│õżĻ┼÷żŲĪó┼┼╬ü┤╔═²żŌ╣įż”╠“│õż“Ęeż─ż╬ż¼źĖźńźųź▐ź═Ī╝źĖźŃĪ╝żŪżóżļĪŻ
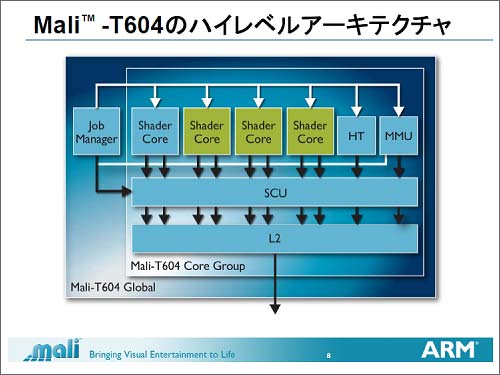
ż│ż”żżż├ż┐ź▐źļź┴ź│źóĪóź▐źļź┴ź╣źņź├ź╔öĄ╝░ż╬źūźĒź╗ź├źĄźóĪ╝źŁźŲź»ź┴źŃżŪżŽČ”Ń~źßźŌźĻĪ╝żŪżóżļL2źŁźŃź├źĘźÕż╬ź│źęĪ╝źņź¾źĘż“╣Ōżßżļż│ż╚ż¼─_═ūż╩ź½ź«ż“É█żļż│ż╚ż╦ż╩żļĪŻźßźŌźĻĪ╝ż╬ź│źęĪ╝źņź¾źĘż╚żŽĪóČ”Ń~źßźŌźĻĪ╝ż╬ŲŌ═Ųż“▐k├ūżĄż╗żļČ\Įčż╬ż│ż╚ĪŻź▐źļź┴ź│źóż╬żĶż”ż╩╩Ż┐¶ż╬ź│źóżŪĮĶ═²ż╣żļŠņ╣ńĪóČ”Ń~źßźŌźĻĪ╝ż╬ŲŌ═Ųż¼ź│źóż┤ż╚ż╦źąźķźąźķżŪżŽ└Łē”ż╦║╣ż¼ĮjżŁż»ż╩ż├żŲżĘż▐ż”ĪŻż│ż╬ż┐żßźŁźŃź├źĘźÕż╦╗╚ż”źßźŌźĻĪ╝ż╬ŲŌ═Ųż“Ų▒żĖż╦żĘżŲź│źóż┤ż╚ż╬źŁźŃź├źĘźÕź▀ź╣ż¼ÅŚżŁż╩żżżĶż”ż╦żĘżŲż¬ż»ĪŻż│ż╬ż┐żßĪóČ”Ń~źßźŌźĻĪ╝ż“┤╔═²ż╣żļMMUĪóżĮżĘżŲźßźŌźĻĪ╝ż╬ź│źęĪ╝źņź¾źĘż“┤╔═²ż╣żļSCUĪ╩ź╣ź╠Ī╝źūöUĖµźµź╦ź├ź╚Ī╦ż“Ęeż─ĪŻż│żņż╦żĶż├żŲźĘź¦Ī╝ź└Ī╝ź│źó┤ųż╬ź│źęĪ╝źņź¾źĘż“┤╔═²żŪżŁżļĪŻ╩┬š`ĮĶ═²ż╚żĘżŲżŽĪó║ŪĮj256ź╣źņź├ź╔ż▐żŪ┤╔═²żŪżŁżļĪŻ
┐▐3ĪĪGPUź│źó1Ė─ŲŌżŌ╩┬š`ĮĶ═²żĘżŲżżżļ
ż│ż”żżż├ż┐¾H┐¶ż╬źĘź¦Ī╝ź└Ī╝ź│źóż╦┼¼żĘż┐╩┬š`ĮĶ═²ż“GPUżŪ╣įż”źóĪ╝źŁźŲź»ź┴źŃż“╣Į└«żĘż┐ż│ż╚żŽĪó╝┬żŽźņź¾ź└źĻź¾ź░Š}╦Īż╚żŌ┤žŽóż╣żļĪŻŠ├õJ┼┼╬üż“æųż▓ż╩żżż┐żßż╦źßźŌźĻĪ╝ż╬źąź¾ź╔╔²ż“žōżķżĘżŲżżżļż¼ĪóżĮż╬ż┐żßż╦1ż─ż╬▓ĶĀCż“╬Ńż©żą4Ī▀4╩¼│õżĘżŲĪó╩¼│õżĘż┐ōļ░Ķż“ź┐źżźļż╚Ō}żėĪóżĮż╬¾H┐¶ż╬ź┐źżźļż“┼╔żĻż─żųż╣ż┐żßż╦¾H┐¶ż╬źĘź¦Ī╝ź└Ī╝ź│źóżŪ╩┬š`ĮĶ═²ż╣żļĪŻż│ż╬ź┐źżźļź┘Ī╝ź╣źóĪ╝źŁźŲź»ź┴źŃż“╝┬╣įż╣żļż┐żßż╦ź▐źļź┴ź╣źņź├ź╔öĄ╝░ż╬╩┬š`ĮĶ═²ż“Ų│Ų■żĘż┐Ślż└ĪŻ
ź┐źżźļź┘Ī╝ź╣źóĪ╝źŁźŲź»ź┴źŃżŪżŽĪó╝ŖōQĮń▀Mż╦═ź└Ķ┼┘ż“»éżßĪóż▐ż║╔Įż½żķĖ½ż©ż╩żżŗ╩¼ż╬źĘź¦Ī╝ź└Ī╝żŽ╣įż’ż╩żżĪŻ╝Īż╦▓ĶĀCĖÕżĒŖõż╦żóżļ│©ż╬źąź├ź»ź░źķź”ź¾ź╔ż“┼╔żĻż─żųż╣ĪŻżĮż╬źąź├ź»ź░źķź”ź¾ź╔ż╦ŠĶż├żŲżżżļØŖ─¦┼¬ż╩ŗ╩¼ż╬ź┐źżźļż“ĮĶ═²ż╣żļĪŻż│ż╬ØŖ─¦┼¬ż╩ŗ╩¼ż¼ź┐źżźļ┤ųż╦ż▐ż┐ż¼ż├żŲżżżļż│ż╚ż¼¾Hżżż┐żßĪóØŖ─¦ż“Įń░╠¤²ż▒żĘż╩ż¼żķØŖ─¦ż╬żóżļź┐źżźļż└ż▒ż“ĮĶ═²ż╣żļĪŻż│ż╬żĶż”ż╦żĘżŲźņź¾ź└źĻź¾ź░ż╬ØŁ═ūż╩ŗ╩¼ż╬ź┐źżźļż½żķĮń╚ųż╦╝ŖōQżĘżŲżżż»ż│ż╚żŪĪó╠ĄŠGż╩╝ŖōQż“╣įż’ż╩żżżĶż”ż╦╣®╔ūżĘżŲżżżļĪŻ
GPUź│źóżŽżŌż┴żĒż¾ź▐źļź┴ź│źóżŌ▓─ē”żŪżóżĻĪó╩Ż┐¶ż╬GPUź│źóż“ż─ż╩ż«ĪóźßźŌźĻĪ╝ż╬ź│źęĪ╝źņź¾źĘż“│╬╩▌ż╣żļż┐żßż╦CoreLinkźąź╣ż“└▀╝ŖżĘż┐ĪŻCoreLinkźąź╣żŽźóĪ╝źÓ╝ęż¼“£═Ķż½żķ╗╚ż├żŲżżżļAMBAźąź╣ż╬źŽźżź©ź¾ź╔╚Ūż╚żŌżżż©żļźąź╣żŪĪóAMBA4 źŁźŃź├źĘźÕź│źęĪ╝źņź¾ź╚źżź¾ź┐Ī╝ź│ź═ź»ź╚Ī╩CCI-400Ī╦ż╚Ō}ż¾żŪżżżļĪŻźŁźŃź├źĘźÕż╬ŠW├ōĖ·╬©ż¼╣Ōż»ż╩żĻźŁźŃź├źĘźÕź▀ź╣ż¼žōżļĪŻźĮźšź╚ź”ź©źóżŪźŁźŃź├źĘźÕż╬źßź¾źŲź╩ź¾ź╣ż“╣įż”ØŁ═ūżŌż╩żżĪŻ
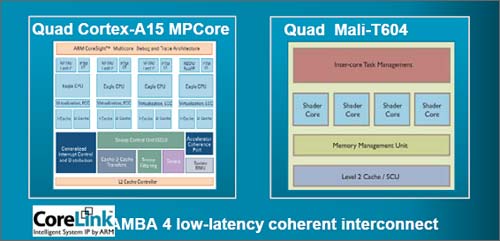
┐▐4ĪĪCPUż╚GPUż“ż─ż╩ż«źßźŌźĻĪ╝ż╬ź│źęĪ╝źņź¾źĘż“╣Ōżßżļż┐żßż╬CoreLinkźąź╣
CoreLinkż“─╠żĖżŲĪóGPUż½żķCPUż╬źŁźŃź├źĘźÕż“├ĄżĘż╦╣įż»ż│ż╚ż¼żŪżŁĪ󟣟џ├źĘźÕźŪĪ╝ź┐ż╬Č”Ń~▓Įż¼į~├▒ż╦ż╩żļĪŻż│ż╬ż┐żß╔į═ūż╩źŁźŃź├źĘź¾ź░ż“ż╩ż»ż╣ż│ż╚żŌżŪżŁĪó╝ŖōQĖ·╬©ż¼æųż¼żļż│ż╚ż╦ż╩żļĪŻ
ĖĮ╝┬┼¬ż╩źĮźĻźÕĪ╝źĘźńź¾ż“═▀żĘżżĖ▄Ąęż╦Ė■ż▒ż┐3╚ųų`ż╬┐Ę×æēäżŪżóżļPOPźĄĪ╝źėź╣żŽĪóźĘźĻź│ź¾ż╦övŽ®ż“ŠŲżŁ¤²ż▒ż╣ż░ż╦Ų░║Ņż“╝┬Š┌żŪżŁżļźčź├ź▒Ī╝źĖźĄĪ╝źėź╣ż└ż¼ĪóźšźĪź”ź¾ź╔źĻż“źčĪ╝ź╚ź╩Ī╝ż╚żĘżŲźšźĪźųźņź╣żõIDMż╬Ė▄Ąęż╦─¾ČĪż╣żļĪŻ╬Ńż©żąĪó32nmż╬źŽźżkźßź┐źļź▓Ī╝ź╚ż╬źĄźÓź╣ź¾ż╬źūźĒź╗ź╣ż“╗╚ż├żŲSoCż“×æļ]żĘż┐żĻĪó1.7GHzżŪŲ░║Ņż╣żļźŲźŁźĄź╣źżź¾ź╣ź─źļźßź¾ź─Ī╩TIĪ╦ż╬OMAPźūźĒź╗ź├źĄż“╝┬ĖĮżĘż┐żĻżĘżŲżżżļĪŻSoCż“ż╣ż░ż╦└▀╝Ŗ×æļ]żĘż┐żżĖ▄Ąęż╦┼¼żĘż┐źĄĪ╝źėź╣żŪCortex-A9ż╬ر═²IPż╬ż█ż½ż╦ARMż¼Ū¦─Ļż╣żļź┘ź¾ź┴ź▐Ī╝ź»ż“źŲź╣ź╚żŪżŁĪóźĻźšźĪźņź¾ź╣Š}╦ĪżŌ─¾ČĪż╣żļĪŻźšźĪź”ź¾ź╔źĻźčĪ╝ź╚ź╩Ī╝ż╚żĘżŲżŽĪ󟥟ӟ╣ź¾ż╦▓├ż©ĪóTSMCĪóź░źĒĪ╝źąźļźšźĪź”ź¾ź╔źĻĪ╝ź║żŌ╗╚ż©żļĪŻ
╗▓╣═½@╬┴
1) ARM╝ęź╦źÕĪ╝ź╣źĻźĻĪ╝ź╣
ARM Heralds New Era In Embedded Graphics With Next-Generation Mali GPU

