XilinxĪóUltraScaleźóĪ╝źŁźŲź»ź┴źŃżŪĮjæä╠ŽFPGAż╬Ū█└■Ī󟻟Ēź├ź»╩¼Ū█ż“║■┐Ę
XilinxżŽĪó20nmźļĪ╝źļż╬LSIż“┴ßż»żŌźŲĪ╝źūźóź”ź╚żĘż┐ĪŻźŪźČźżź¾źļĪ╝źļż¼20nmż╚╚∙║┘▓Įż╣żļż╚ĪóĮĖ└čżŪżŁżļövŽ®ż¼╦─Įjż╦ż╩żļż┐żßĪóźóĪ╝źŁźŲź»ź┴źŃż“║¼╦▄┼¬ż╦Ė½─ŠżĘĪóUltraScależ╚ć@¤²ż▒ż┐(┐▐1)ĪŻCLBĪ╩Configurable Logic BlockĪ╦╝■żĻż╬Ū█└■żõĪóDSPźųźĒź├ź»Ī󟻟Ēź├ź»╩¼Ū█ż╩ż╔ż“║Ū┼¼▓ĮżĘż┐ĪŻ

┐▐1ĪĪĮjæä╠ŽFPGAĖ■ż▒źóĪ╝źŁźŲź»ź┴źŃUltraScaleĪĪĮąųZĪ¦Xilinx
FPGAż╬▒■├ō×æē俎ż▐ż╣ż▐ż╣╣ŌÅ]▓ĮĪó╣Ō└Łē”▓Įż╣żļöĄĖ■ż╦Ė■ż½ż├żŲżżżļĪŻĖ„źšźĪźżźąź═ź├ź╚ź’Ī╝ź»żŽ100Gbpsż½żķ400GbpsĪ󿥿ķż╦żŽ1Tbpsżžż╚Ė■ż½ż├żŲżżżļĪŻźŪźĖź┐źļźėźŪź¬żŽ1080pż╬HDźėźŪź¬ż½żķżĮż╬4Ū▄/2Ū▄ż╬4K/2KĪóżĮż╬└Ķż╦żŽ8Kżžż╚╣Ō╗@║┘▓Į═ūĄßżŌ╗\ż©żŲżżżļĪŻź’źżźõźņź╣ź═ź├ź╚ź’Ī╝ź»żŽ3Gż½żķLTEżĄżķż╦LTE-Ażžż╚╣ŌÅ]ż╬źŪĪ╝ź┐źņĪ╝ź╚ż╬╗■┬Õżžż╚Ė■żżżŲżżżļĪŻ
ż│ż”żżż├ż┐╣ŌÅ]Ī”╣ŌĮĖ└čż╬źĘź╣źŲźÓż“FPGAżŪ╝┬ĖĮż╣żļż┐żßż╦żŽĪóFPGAż└ż▒żŪżŽż╩ż»ĪóSoCż╬żĶż”ż╩Š}╦Īż¼’Lż½ż╗ż╩ż»ż╩żļĪŻż╣ż╩ż’ż┴ĪóCPUź│źóż╦DSPżõROMĪóRAMĪóźżź¾ź┐Ī╝źšź¦Ī╝ź╣Īó╝■╩šövŽ®ĪóFPGAż╩ż╔ż“ĮĖ└čżĘż┐SoCż╦żĶż├żŲĮjæä╠Žż╩LSIż╦×┤▒■żĘżŲżŁż┐ĪŻµ£żŲFPGAżŪ╣Į└«ż╣żļż╩żķźĮźšź╚ź”ź©źóż“ź╝źĒż½żķ│½╚»żĘż╩ż▒żņżąż╩żķż║ĪóżŌżŽżõFPGAżŪĮą═ĶżļšJ░Žż“Ä═├”żĘżŲżżżļĪŻżĘż½żŌĮj▄ćż╬źĮźšź╚ź”ź©źóżŽź½ź╣ź┐ź▐źżź║żĄżņżŲżżżļż┐żßĪó║ŲŠW├ōż¼żŪżŁż╩żżĪŻż│ż│ż¼FPGAż╬³cżŁĮĻż└ĪŻ
╣ŌĮĖ└čFPGAżŽĪó└Łē”Ī”ĄĪē”Č”żŌżŽżõSoCż╚żżż”ż┘żŁ╚ŠŲ│öüLSIż╦ż╩ż├żŲżżżļĪŻż╚żŽżżż©Īó╝■╩šövŽ®ż╦Ų╚śOż╬źŽĪ╝ź╔ź”ź©źóövŽ®ż“ĮĖ└čżĘżŲ║╣╩╠▓Įż“┐▐żĒż”ż╚ż╣żļŠņ╣ńż╦żŽĪó╣ŌÅ]└Łē”ż“įużļż┐żßFPGAövŽ®ż“ŠW├ōż╣żļĪŻż│ż╬FPGAŗ╩¼żĄż©Įjæä╠Žż╦ż╩żĻĪóŪ█└■ŗ╩¼ż¼SoCż╬└Łē”ż╬ź▄ź╚źļź═ź├ź»ż╦ż╩żĻ╗Žżßż┐ĪŻ
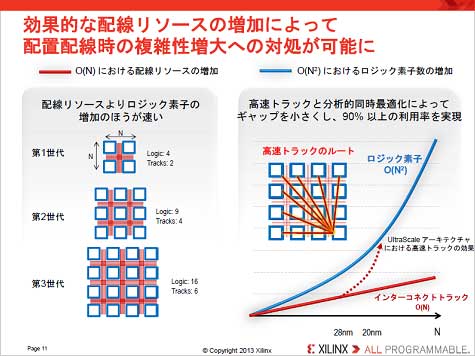
┐▐2ĪĪ¾H┴žŪ█└■żŪŪ█└■źĻźĮĪ╝ź╣Ė·╬©ż“æųż▓żļĪĪĮąųZĪ¦Xilinx
żĮż│żŪĪó║ŻövXilinxżŽĪóźĒźĖź├ź»ź©źņźßź¾ź╚CLBż╚XöĄĖ■ĪóYöĄĖ■ż╬Ū█└■ż└ż▒żŪżŽź╣źŁźÕĪ╝żõźĖź├ź┐Ī╝ż¼╗\▓├ż╣żļČ▓żņż¼żóżļż┐żßĪó¾H┴žŪ█└■ż╬źĻźĮĪ╝ź╣ż“ŖAżßöĄĖ■ż╦║Ū┼¼▓Įż╣żļźļĪ╝ź╚żŌ▓├ż©ĪóŪ█└■ŠW├ō╬©ż“90%░╩æųż╦æųż▓ż┐(┐▐2)ĪŻ▓├ż©żŲĪó20nm FPGAż╚żżż├ż┐╣ŌĮĖ└čźŪźąźżź╣żŽĪó╣ŌÅ]▓Įż╬ż┐żßż╦512Ī┴2048źėź├ź╚─╣ż╬źąź╣ż“╗╚ż”ż│ż╚ż¼¾HżżĪŻź»źĒź├ź»ż¼Ų▒╗■ż╦2048źėź├ź╚żŌ┴÷żļż╩żķź╣źŁźÕĪ╝ż╬╠õ¼öż¼╔ŌæųżĘżŲż»żļĪŻż│ż╬ż┐żßĪóASICż╬żĶż”ż╦ź»źĒź├ź»ź─źĻĪ╝ėXż╦ź»źĒź├ź»ź╔źķźżźąż“Ų│Ų■ż╣żļż│ż╚żŪ╬Ńż©żąXöĄĖ■ż╬╩┬š`Ū█└■ż“ź╔źķźżźųż╣żļŠņ╣ńżŪżŌĪóźĒĪ╝ź½źļź»źĒź├ź»ż╬żĶż”ż╦źųźĒź├ź»ż┤ż╚ż╦ø]żżŪ█└■ż“ź╔źķźżźųż╣żļĘ┴ż╦╩čż©żļ(┐▐3)ĪŻż│ż╬±T▓╠Ī󟻟Ēź├ź»ź╣źŁźÕĪ╝żŽÅŚżŁż╦ż»ż»ż╩żļĪŻ
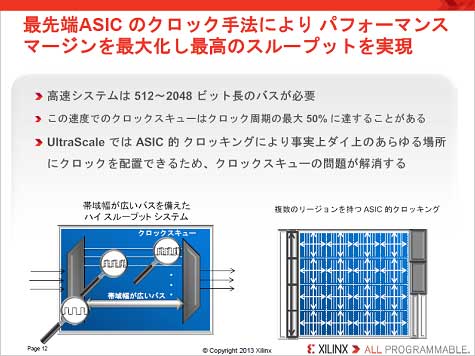
┐▐3ĪĪźĒĪ╝ź½źļź»źĒź├ź»ż“ź╔źķźżźųż╣żļż│ż╚żŪź╣źŁźÕĪ╝ż“╦╔ż░ĪĪĮąųZĪ¦Xilinx
└Łē”┼¬ż╦żŽDSPż╬╝ŖōQē”╬üż“æųż▓ż┐ĪŻØŖż╦╔ŌŲ░Š«┐¶┼└▒ķōQż╬Šņ╣ńż╦żŽĪó├▒╗@┼┘ż╚Ū▄╗@┼┘ż╬▒ķōQż“▓─ē”ż╦ż╣żļż┐żßĪó18Ī▀27źėź├ź╚ż╬MACĪ╩ŠĶōQ╩Å└č▒ķōQ▀_Ī╦ż“2Ė─ż└ż▒żŪ54źėź├ź╚╔²ż╬▒ķōQż¼żŪżŁżļżĶż”ż╦żĘżŲżżżļĪŻż│ż╬DSPż“╗╚żżĪóĖĒżĻÖÄ┘ćövŽ®CRCżõECCĪóEFECż╩ż╔ż“╝┬ĖĮżĘżŲżżżļĪŻ
Š├õJ┼┼╬üż╬║’žōż╦┤žżĘżŲżŽĪ󟻟Ēź├ź»ź▓Ī╝źŲźŻź¾ź░ż“├ōżżżŲź»źĒź├ź»╝■āS┐¶ż“▓╝ż▓żļż┐żßĪóźąź├źšźĪż“╗\żõżĘżŲżżżļĪŻż▐ż┐ĪóRAMż“źųźĒź├ź»ż╦╩¼ż▒Īóź└źżź╩ź▀ź├ź»┼┼╬üż“źčź’Ī╝ź▓Ī╝źŲźŻź¾ź░ż╦żĶż├żŲĪóČ╔ĮĻ┼¬ż╦▓╝ż▓żķżņżļżĶż”ż╦żĘż┐ĪŻ
ż▐ż┐Īó╩Ż╗©ż╩SoC/FPGAż“C/C++Ė└ĖņżŪ└▀╝ŖżŪżŁżļżĶż”ż╦ż╣żļż┐żßĪóVivado Design Suiteż╚Ō}żų┐ʿʿż└▀╝Ŗź─Ī╝źļż“├ō┴TżĘĪó└▀╝Ŗ║ŅČ╚ż“┴ßżßżŲżżżļĪŻ┐ʿʿżźąĪ╝źĖźńź¾ż╬Vivado Design Suit 2013.1ź─Ī╝źļż╦żŽVivado IP Integratorż╚Ō}żųĪóXilinxż╬IPż“║ŲŠW├ōż╣żļż┐żßż╬ź─Ī╝źļżŌ┤▐ż▐żņżŲż¬żĻĪóHDLĖ└Ėņż╦╩č┤╣żĘżŲIPżŌFPGAŗ╩¼żŌRTLż╦╣ń└«ż╣żļĪŻ
XilinxżŽĪó║Żövż╬UltraScaleźóĪ╝źŁźŲź»ź┴źŃż“20nmźŪźąźżź╣ż½żķŲ│Ų■ż╣żļż¼Īó28nmż╦żŌ│╚─źż╣żļż╚Ų▒╗■ż╦Īó16nmżŪżŌ·t│½żĘżŲżżż»(┐▐4)ĪŻżĘż½żŌ×æēäĘ▓ż╦ż─żżżŲżŌVirtexźĘźĻĪ╝ź║ĪóKintexźĘźĻĪ╝ź║Č”ż╦Ų│Ų■żĘżŲżżż»ĪŻĮø═ĶżŽZinqźĘźĻĪ╝ź║ż╬×æēäż╦żŌ┼¼├ōż╣żļ╝Ŗ▓Ķż└ĪŻUltraScaleźóĪ╝źŁźŲź»ź┴źŃż“ŲDżĻ╣■ż¾ż└║ŪĮķż╬SoCżŽ2013ŃQŗī4╗═╚Š┤³ż╦Įą▓┘ż╣żļ═Į─ĻżŪżóżļĪŻ
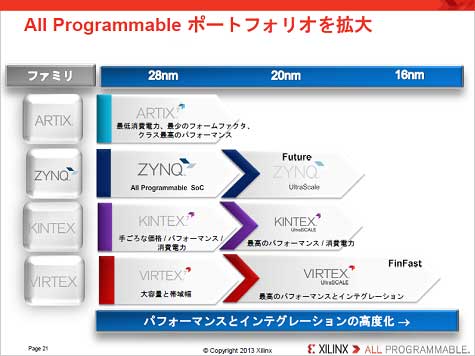
┐▐4ĪĪXilinx FPGA×æēäż╬źĒĪ╝ź╔ź▐ź├źū

