ź╦źÕĪ╝źĒź┴ź├źū▄ć└ŌĪĪĪ┴żżżĶżżżĶ╚ŠŲ│öüż╬Įą╚ų(2-2)
ŗī2ŠŽĪ¦źŪźŻĪ╝źūĪ”ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬ź╦źÕĪ╝źĒź┴ź├źūżžż╬╝┬äóĪ┴żĮż╬┤¬ĮĻżŽ!!
ŗī2ŠŽżŪżŽĪóź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬┬Õ╔Į┼¬ż╩Č\Įčż╚żĘżŲCNNĪ╩øQż▀╣■ż▀ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»Ī╦ż“ż▐ż║Šę▓żĘĪóźŪźŻĪ╝źūÄźź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬µ£═Ųż“▓“└ŌżĘż┐Ī╩ź╦źÕĪ╝źĒź┴ź├źū▄ć└ŌĪ┴żżżĶżżżĶ╚ŠŲ│öüż╬Įą╚ų(2-1)╗▓Š╚ĪŻż│ż╬ŗī2ŠŽż╬2-2żŪżŽĪóżĮżņż“£pż▒żŲCNNż╬źŌźŪźļż╬┐╩▓Įż“Šę▓żĘĪó╚ŠŲ│öüź┴ź├źūż╦═Ņż╚ż╣ż┐żßż╬┤¬ĮĻż“▓“└Ōż╣żļĪŻĪ╩ź╗ź▀ź│ź¾ź▌Ī╝ź┐źļįćĮĖ╝╝Ī╦
├°ŪvĪ¦ĪĪĖĄ╚ŠŲ│öü═²╣®│žĖ”ē|ź╗ź¾ź┐Ī╝Ī╩STARCĪ╦/ĖĄ┼ņėøĪĪ╝å└źĪĪĘ╝
2.4ĪĪ CNNż╬źŌźŪźļż╬┐╩▓Į (1) Ī┴źóĪ╝źŁźŲź»ź┴źŃż╬╩č╔ÅĪ¦żĶżĻ╣Łż»Ī®Ī¬ żĶżĻ┐╝ż» 152┴žĪ┴
2012ŃQż╦ź╚źĒź¾ź╚Įj│žż¼╚»╔ĮżĘż┐Alex Netż½żķĪó2015ŃQ12ĘŅż╦│½╠¢żĄżņż┐ĄĪ│Ż│žØ{╩¼╠Ņż╦ż¬ż▒żļ║Ū╣Ō╩÷ż╬╣±║▌▓±Ą─ż╚Ė└ż’żņżŲżżżļNIPSĪ╩the Annual Conference on Neural Information Processing Systems 2015Ī╦ż╦żŲMSRA(Microsoft Research Asia)ż¼╚»╔ĮżĘż┐ResNet (Residual Net)ż▐żŪż╬żżż»ż─ż½ż╬┬Õ╔Į┼¬ż╩CNNż╬źŌźŪźļż╦┤žżĘżŲ└Ō£½ż╣żļĪŻźŌźŪźļżŽéāżĻż╬ż╩żżĖ┬żĻĪó╣±║▌┼¬ż╩▓ĶćĄŪ¦╝▒ż╬ź│ź¾ź┌źŲźŻźĘźńź¾żŪżóżļILSVRC/Imagenetż¼╝ń╠¢ż╣żļź┘ź¾ź┴ź▐Ī╝ź»ż╬▐kż─ż╬▐k╚╠رöüŪ¦╝▒ŗ╠ńż╦╗▓▓├żĘ═źĮ©ż╩±T▓╠Ī╩1░╠ĪóVGGNetżŽ2░╠Ī╦ż“┐āżĘż┐źŌźŪźļż“║╬żĻæųż▓żļĪŻ
2.4£IżŪżŽżĮżņżķż╬źóĪ╝źŁźŲź»ź┴źŃĪ╩╣Į└«Ī╦ż“Īó2.5£IżŪżŽŲŌŗż╬╣Į└«═ū┴Ūż“ĪóżĮżĘżŲ2.6£IżŪżŽLSIżžż╬╝┬äóż╦ż¬żżżŲ─_═ūż╩└čŽ┬▒ķōQöv┐¶ż╚źčźķźßĪ╝ź┐┐¶ż╦ŠÆų`żĘżŲ└Ō£½ż╣żļĪŻ║ŪĖÕż╬2.6£IżŪźŌźąźżźļżž┼ļ║▄żĘż┐║▌ż╬ź▒Ī╝ź╣ź╣ź┐źŪźŻż“▓├ż©żļĪŻżĮżņżķż╬═²▓“ż“─╠żĘżŲĘQźŌźŪźļż“LSIżž╝┬äóż╣żļ║▌ż╬┤¬ĮĻż“ż─ż½żÓż╬ż¼ż│ż╬ŠŽż╬╝ń╗▌żŪżóżļĪŻ
(1) ┬Õ╔Į┼¬CNNźŌźŪźļ
CNNż“ź┘Ī╝ź╣ż╚żĘżŲĪó▓Ķ楿╬Ū¦╝▒╬©ż╬Ė■æųż“ų`╗žżĘżżż»ż─żŌż╬źŌźŪźļż¼─¾░ŲżĄżņżŲżŁż┐ĪŻ║¼öfż╦żóżļź╚źņź¾ź╔żŽź═ź├ź╚ź’Ī╝ź»ż╬┴žż“żĶżĻ¾Hż»└čż▀─_ż═żļż│ż╚ż╦żĶżļĖ■æųżŪżóżļ(ż╩ż¬Īó¾H┴žż¼Ń~ŠWż└ż╚żżż”żóżļµć┼┘ż╬┤┴├┼¬ż╩═²▓“żŽ┐╩ż¾żŪżżżļĪ╩╗▓╣═½@╬┴14Īó171╩ŪĪ╦)ĪŻ┐▐9ż╦┬Õ╔Į┼¬źŌźŪźļż╬┐õöĪż“┐āż╣ĪŻ1998ŃQż╦║ŪĮķż╦╚»╔ĮżĄżņż┐CNNż╬░ķżŲĪ╩Ö┌ż▀ż╬Ī╦┐Ųż╚Ė└ż’żņżŲżżżļLeCunĢ■ż╬╣═░ŲżĘż┐LeNet6Ī╩╚ųęÄżŽ┴ž┐¶Ī¦╗▓╣═½@╬┴24Ī╦ż“╗▓╣═ż╚żĘżŲ▓├ż©ż┐ĪŻAlexNet8ĪóVGGNet19(╗▓╣═½@╬┴25)ĪóResNet152(╗▓╣═½@╬┴28Ī╦ż▐żŪżóżļĪŻ┴ž┐¶ż¼6┴žż½żķ152┴žż▐żŪ╗\▓├Ī╩żĶżĻźŪźŻĪ╝źūż╦Ī╦żĘżŲżżżļĪŻź’źżź╔ż╦ż╩ż├żŲżżżļźŌźŪźļżŌżóżļĪ╩GoogLeNet22Ī¦╗▓╣═½@╬┴27Ī╦ĪŻźĘź¾ź¼ź▌Ī╝źļ╣±╬®Įj│žż¼2014ŃQ╗Žżßż╦╚»╔ĮżĘż┐NiN (Network in NetworkĪ¦╗▓╣═½@╬┴26)ż╬źŌźŪźļżŌ▓├ż©żŲżóżļĪŻ
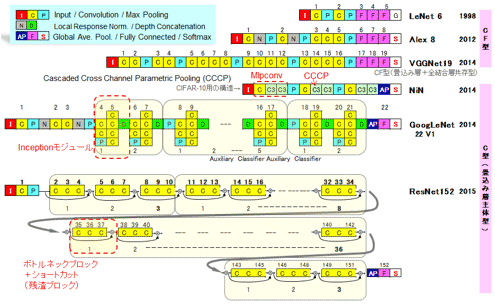
┐▐9 CNNż╬┬Õ╔Į┼¬ż╩źŌźŪźļĪ¦ CFĘ┐Ī╩Č”┘TĘ┐Ī╦ż½żķCĘ┐Ī╩øQż▀╣■ż▀┴ž╝ńöüĘ┐Ī╦żž
┐▐9ż╬Ė½öĄż╦┤žżĘżŲżŽĪó┤╦▄═ū┴Ūż½żķż╩żļAlexNetż“├ōżżżŲ└Ō£½ż╣żļĪŻż│ż│żŪżŽĪóI-C-N-P-C-N- ├µŠS -F-F-F-Sż╚╩┬ż┘żķżņżŲżżżļĪŻIżŽŲ■╬üImageĪóCżŽConv┴žĪóNżŽ┘ćæä▓Į┤ž┐¶Ī╩NormalizationĪ╦ĪóPżŽPooling┴žĪóFżŽµ£±T╣ń┴ž(Fully Connected layer)ĪóżĮżĘżŲ║ŪĖÕż╬SżŽīÖ└Ł▓Į┤ž┐¶ż╬SoftmaxżŪżóżļĪŻż╩ż¬ĪóConv┴žż╬─ŠĖÕż╦żóżļīÖ└Ł▓Į┤ž┐¶żŽŠ╩ŠSżĄżņżŲżżżļż╬żŪÅR┴Tż¼ØŁ═ūżŪżóżļĪŻReLU (Rectified Linear Unit)ż¼AlexNet░╩æTµ£żŲż╬źŌźŪźļż╬µ£żŲż╬Conv┴žż╬─ŠĖÕżŪ╗╚├ōżĄżņżŲżżżļĪŻ
¾H┴ž▓Įż╦żĶżļ╗@┼┘Ė■æųż╬╝{Ąßż╬╬«żņż╬├µżŪź═ź├ź╚ź’Ī╝ź»ż╬╣Į└«ż╦2ż─ż╬╩č▓Įż¼ĖĮżņż┐ĪŻ2013ŃQ¼ŹĪ┴2014ŃQĮķŲ¼ż╦╚»╔ĮżĄżņż┐źĘź¾ź¼ź▌Ī╝źļ╣±╬®Įj│žż╬NiNĪ╩Network in NetworkĪó╗▓╣═½@╬┴26)ż¼└Ķ╩▄ż“ż─ż▒ż┐ĪŻż╩ż¬Īó┐▐9ż╦┐āżĘż┐NiNż╬╣Į└«żŽĪóCIFAR-10├ōĪ╩╩╠ż╬ź┘ź¾ź┴ź▐Ī╝ź»Ī╦żŪżóżļĪŻż│ż│żŪĪó┐▐ż╬īÜ├╝żŪČĶ╩¼ż▒żĘżŲżżżļżĶż”ż╦Īó“£═Ķż╬µ£±T╣ń┴žż¼╩Ż┐¶┴žŲ■ż├żŲżżżļżŌż╬ż“ĪóCFĘ┐Ī╩øQż▀╣■ż▀┴žĪ▄µ£±T╣ń┴žČ”┘TĘ┐Ī╦ż╚Ō}żėĪóNiN░╩æTż╬øQż▀╣■ż▀┴žż╦╝ńöüż¼Åøż½żņĪóż½ż─Conv┴žż¼źŌźĖźÕĪ╝źļ▓ĮżĘżŲżżżļźŌźŪźļż“CĘ┐Ī╩øQż▀╣■ż▀┴ž╝ńöüĘ┐Ī╦ż╚Ō}żųż│ż╚ż╚ż╣żļĪŻCĘ┐żŽ├▒ĮŃż╩Conv┴žżŪżŽż╩ż»ĪóźŌźĖźÕĪ╝źļ▓ĮżĄżņżŲżżżļż│ż╚ż¼ØŖ─¦żŪżóżļĪŻ
(2) CĘ┐ż╬ØŖ─¦Ī╩żĮż╬1Ī╦Ī”Ī”Ī”źŌźĖźÕĪ╝źļż╬Ų│Ų■
CFĘ┐ż½żķCĘ┐żžż╬1ż─ų`ż╬╩č▓ĮżŽøQż▀╣■ż▀┴žĪ╩CĪ╦ż╬╣Į└«ż¼╩Ż╗©ż╦ż╩ż├ż┐┼└ż└ĪŻ“£═Ķż╬VGGNetż▐żŪż╬├▒ĮŃż╦øQż▀╣■ż▀┴žż¼C-CżŌżĘż»żŽC-C-C-Cż╚Ę½żĻ╩ųżĄżņżļĘ┴╝░ż½żķĪóżĮżņżŠżņż╬┴T┐▐ż“Ęeż┴ż╩ż¼żķźŌźĖźÕĪ╝źļĘ┴╝░Ī╩┐▐9ż╬Mlpconv/NiNĪóInceptionźŌźĖźÕĪ╝źļ/GoogLeNetĪó╗─▐ųźųźĒź├ź»/ResNetĪ╦ż╦ÅøżŁ┤╣ż’żĻĪóżĮż╬źŌźĖźÕĪ╝źļśOöüż¼ź═ź├ź╚ŲŌżŪĘ½żĻ╩ųżĄżņżļĪ╩Š▄║┘żŽĪó╗▓╣═½@╬┴26Ī┴29ż╬ĘQéb╩ĖĪó╗▓╣═½@╬┴14ĪóżŌżĘż»żŽä▌PurdueĮj│žż╬ČĄĶbżŪż½ż─TeraDeep CTOż╬CulurcielloČĄĶbż╬źųźĒź░Ī¦Neural Network ArchitecturesĪ╩╗▓╣═½@╬┴32Ī╦ż“╗▓Š╚Ī╦ĪŻ
┐▐10ż¼ĘQźŌźĖźÕĪ╝źļż╬Š▄║┘╣Įļ]żŪżóżļĪŻį~ŠS▓ĮżĘż┐└Ō£½ż╦ż╩żļż¼Īó╝ŖōQ╬╠/źčźķźßĪ╝ź┐┐¶ż╬├▒ĮŃ╗\▓├ż“═▐ż©żļźŲź»ź╦ź├ź»ż“Ų■żņż─ż─ØŖ─¦╔ĮĖĮ╬üż“æųż▓ż┐MlpconvźŌźĖźÕĪ╝źļ(NiNĪ¦Conv┴žż╬─ŠĖÕż╦├▒ĮŃż╩µ£±T╣ńż╬CCCP┴ž[Cascaded Cross Channel Parametric Pooling]ż“żżż»ż─ż½┘UŲ■)ĪóNiNż╬źŲź»ź╦ź├ź»ż“ŲDżĻ╣■ż▀▓├ż©żŲøQż▀╣■ż▀┴žż“╩┬š`ż╦żĘŪ¦╝▒╬©źóź├źūż“ų`ébż¾ż└źŌźĖźÕĪ╝źļ(Inception Layer/GoogLeNet)ĪóżĮżĘżŲ╬ŠŪvż╬╬╔żżĮĻż“ŲD╝╬┬ō┘IżĘĪóż½ż──Š±TżĘż┐100┴ž░╩æųżŪ│žØ{ż“▓─ē”ż╚ż╣żļ╗─▐ųźųźĒź├ź»(Residual block/ResNet)ż╬3ż─ż╬źŌźĖźÕĪ╝źļż¼ĘQĪ╣ż╬źŌźŪźļżŪ─¾░ŲżĄżņż┐ĪŻ╗─▐ųźųźĒź├ź»ż╦żĶżĻ┐ʿʿż▄ćŪ░ż╬╗─▐ų│žØ{Ī╩Residual learningĪ╦ż¼▓─ē”ż╚ż╩żļĪŻż│żņżķż╬źŌźĖźÕĪ╝źļż╦żĶżĻ¾H┴ž▓Įż¼▓─ē”ż╚ż╩żĻĪóŪ¦╝▒╬©żŌĖ■æųż╣żļĪŻŠ▄║┘żŽ╝Ī£IżŪĮęż┘żļĪŻ
![┐▐10Ī¦ĘQźŌźĖźÕĪ╝źļż╬╣Įļ]](/archive/contribution/img/COA160804-01b.gif)
┐▐10Ī¦ĘQźŌźĖźÕĪ╝źļż╬╣Įļ]
(a) Mlpconv/NiN(╗▓╣═½@╬┴26) śĘÖCżŽ├°Ūv╝{ĄŁĪó(b) Inception Layer/GoogLeNet (╗▓╣═½@╬┴27)
(c) Residual net/ResNet (╗▓╣═½@╬┴28)ĪŻ
(3) CĘ┐ż╬ØŖ─¦Ī╩żĮż╬2Ī╦Ī”Ī”Ī”µ£±T╣ń┴žż¼Č╦┼┘ż╦Ę┌ż»ż╩żļ
2ż─ų`ż╬╩č▓ĮżŽĪóØi├╩ż╬ØŖ─¦├ĻĮąŗż╬║ŪĮ¬├╝ż╦¾H┐¶ż╬ØŖ─¦ź▐ź├źū┤ųż“├▒ĮŃż╦╩┐Čč▓Įż╣żļGAP (Global Average PooingĪ¦µ£öüźūĪ╝źĻź¾ź░) ┴žż¼Ų│Ų■żĄżņĪ󿥿ķż╦ĖÕ├╩ŗż╬µ£±T╣ń┴žż╬┐¶ż¼3┴žż½żķ1┴žż╚Š»ż╩ż»ż╩ż├żŲżżżļ┼└żŪżóżļĪŻØi├╩ż╬ØŖ─¦├ĻĮąŗż╦╣ŌżżØŖ─¦╔ĮĖĮ╬üż¼×óż’ż├ż┐ż│ż╚ż½żķĖÕ├╩ŗż╬╔ķ├┤ż¼Ę┌ż»ż╩ż├ż┐±T▓╠ż╚╣═ż©żķżņżŲżżżļĪŻż╣ż╩ż’ż┴Īóµ£±T╣ń┴žż╬ź»źķź╣▓Įż╬║ŅČ╚ż¼ĪóØi├╩ŗż╬ØŖ─¦├ĻĮąż╬║ŅČ╚ż╦“EżĻ╣■ż▐żņż┐±T▓╠Īóµ£±T╣ń┴žż¼╔į═ūż╚ż╩ż├ż┐ż╚╣═ż©żķżņżļĪŻż╩ż¬ĪóGoogLeNetĪóResNetż╬ĖÕ├╩ŗż╦µ£±T╣ń┴žż¼1┴žŲ■ż├żŲżżżļż¼Īóż│żņżŽ┼ŠöĪ│žØ{ż“═Ų░ūż╚ż╣żļż┐żßż╚GoogLeNetż╬│½╚»ŪvĪóSzegedyĢ■żŽĮęż┘żŲżżżļ (╗▓╣═½@╬┴27Īó14)ĪŻ
2.5ĪĪ CNNż╬źŌźŪźļż╬┐╩▓ĮĪĪ(2) Ī┴╣Į└«═ū┴Ūż╬┤¬ĮĻĪ¦ ź▌źżź¾ź╚żŽ5Īó6ź½ĮĻĪ┴
╦▄£IżŪżŽĪóźŌźŪźļż╬┐╩▓Įż“╣Į└«═ū┴Ūż╬£å┼└ż½żķ└┌żĻ╣■żÓĪŻ╔Į1ż╦Øi£IżŪĮęż┘ż┐ĘQźŌźŪźļż╬┐¶├═(æų├╩)Ī󿬿Ķżė╣Į└«═ū┴Ūż╬▐k═„ż“┐āżĘż┐ĪŻ
(1) ▒ķōQöv┐¶Ī”źčźķźßĪ╝ź┐┐¶ĪóżĮżĘżŲź©źķĪ╝╬©
▐k╚╠رöüŪ¦╝▒ż╬ź©źķĪ╝╬©ż╦┤žżĘżŲżŽĪó┼÷Įķż╬╚»╔Įż╦ĪóżĮż╬ĖÕż╬▓■╬╔├═żŌ▓├ż©±éĄŁżĘż┐ĪŻResNet34ż╬ź©źķĪ╝├═ĪųĪ▄1.5%ĪūżŽResNet152ż╦×┤ż╣żļ┴Ļ×┤╗\▓├╩¼żŪżóżļĪŻ┴ž┐¶ĪóźčźķźßĪ╝ź┐Īó▒ķōQ┐¶żŽ2.3£IżŪĮęż┘ż┐öĄ╦ĪżŪ╝ŖōQżĘż┐±T▓╠żŪżóżļĪŻźčźķźßĪ╝ź┐┐¶ż╚▒ķōQ┐¶żŽźŌźŪźļŖõż╬╚»╔Į├═ż¬żĶżė╗▓╣═½@╬┴6Īó14ż╬±T▓╠┼∙ż╚╣ńż├żŲżżżļż│ż╚ż“│╬Ū¦żĘżŲżżżļĪŻResNetż╬źčźķźßĪ╝ź┐┐¶żŽĖĮ╗■┼└żŪĮo│½żĄżņżŲżżż╩żżĪŻNiNĪóGoogLeNet░╩æTżŪ┐¶├═ż╦ĮjżŁż╩╩č▓Įż¼żóżļĪŻŠ▄żĘż»żŽĪó╝Ī£IżŪĮęż┘żļĪŻ
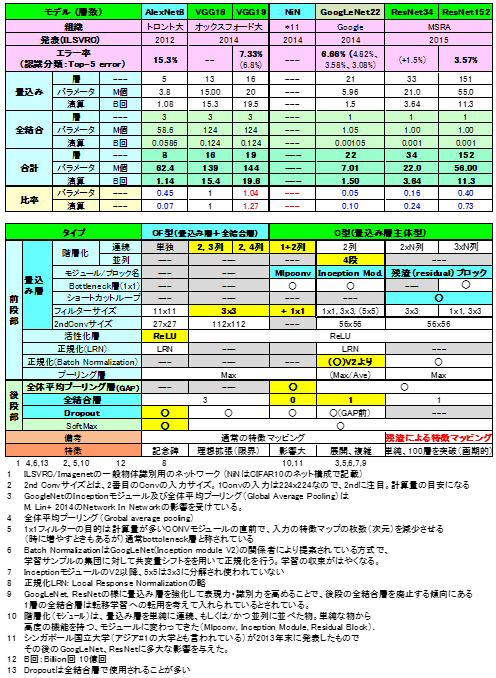
╔Į1 CNNż╬ĘQź═ź├ź╚źŌźŪźļż╬╣Į└«▐k═„
(2) ╣Į└«═ū┴Ū
╔Į1ż╬▓╝├╩ż╦ĘQź═ź├ź╚źŌźŪźļż╬╣Į└«═ū┴Ūż╬▐k═„ż“┐āżĘż┐ĪŻØi£Iż╦Ø{żżĪóCFĘ┐Ī╩øQż▀╣■ż▀┴žĪ▄µ£±T╣ń┴žČ”┘TĘ┐Ī╦ż╚CĘ┐Ī╩øQż▀╣■ż▀┴ž╝ńöüĘ┐Ī╦ż╦╩¼ż▒żŲżżżļĪŻ
╔Įż╬▓½┐¦żż┼ōĮĻż¼ĪóĘQ╣Į└«═ū┴Ūż¼║ŪĮķż╦Ų│Ų■Ī”─¾░ŲżĄżņż┐źŌźŪźļż“┐āżĘżŲżżżļĪŻ┐õöĪż“Ų╔ż▀ŲDżļż╚AlexNetżŪĮjŽ╚ż╬ź═ź├ź╚╣Į└«ż╬╣³╗ęĪ╩øQż▀╣■ż▀┴žĪóīÖ└Ł▓Į┤ž┐¶ ReLUĪóSoftmaxĪó│žØ{öĄ╦ĪDropoutĪ╦ż¼╔wż▐żĻĪó░·żŁ¶öżŁŪ¦╝▒╬©▓■║¤ż“ź┐Ī╝ź▓ź├ź╚ż╚żĘżŲVGGNetżŪConv┴žż╬¾H┴ž▓Į╝{Ąßż╚Š«Ę┐źšźŻźļź┐żžż╬źĘźšź╚ż¼╣įż’żņĪóżĮż╬ĖÕNiN░╩æTĪóConv┴žŲŌż╬źŌźĖźÕĪ╝źļ▓Įżžż╚╬«żņżŲżŁżŲżżżļż╚Ė½żļż│ż╚ż¼żŪżŁżļĪŻĘQĪ╣ż╬└Ō£½żŽĪó╔Į1ż╬£ņÅRż╦ĄŁ║▄żĘż┐ĪŻ─_╩Żż“żĄż▒└Ō£½żŽ│õ░”ż╣żļĪŻ
╔Į2ż╦CNN╣Į└«ż╬ż┐żßż╬┤¬ĮĻż“ż▐ż╚żßż┐ĪŻīÖ└Ł▓Į┤ž┐¶Īó│žØ{╗■Ī”Č\╦ĪżŽCĘ┐/CFĘ┐ż╦Č”─╠ż└ż¼ĪóżĮżņ░╩│░żŽCĘ┐╝ńöüżŪż▐ż╚żßż┐ĪŻĮjöĄżŽĪó╔wż▐ż├żŲżŁż┐ż╚╣═ż©żķżņżļĪŻ╩Ż╗©ż╩ż╬żŽConv┴žźŌźĖźÕĪ╝źļżŪĪó║ŻĖÕż╔ż╬żĶż”ż╦╩čż’żļż½ÅR£åż╣ż┘żŁżŪżóżļĪŻ
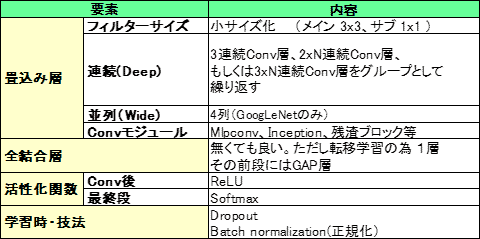
╔Į2Ī¦CNNż╬╣Į└«ż╬┤¬ĮĻĪĪCĘ┐╝ńöüĪĪĪ╩īÖ└Ł▓Į┤ž┐¶Īó│žØ{╗■ż╬Č\╦ĪżŽĪóC/CFĘ┐Č”─╠Ī╦
(3) Š«Ę┐źšźŻźļź┐żžż╬źĘźšź╚ż╚źŌźĖźÕĪ╝źļ▓Į
┼÷Įķż╬AlexżŪ╗╚├ōżĄżņż┐ĮjĘ┐ż╬11x11ż╦┬Õż’żĻ3x3ż╬Š«Ę┐źšźŻźļź┐ż¼╗╚ż’żņżļ═²Įyż╦Īó▒ķōQöv┐¶ż¼Š»ż╩ż»ż╩żļ┼└ż¼żóżļĪŻ░╩▓╝ż╬żĶż”ż╦└Ō£½ż¼żŪżŁżļĪŻ9x9ż╬ōļ░Ķż╦øQż▀╣■ż▀ż“²Xż▒żļŠņ╣ń9x9ż╬źšźŻźļź┐ż└ż╚(9x9)x(9x9)=81x81övż╬▒ķōQż¼ØŁ═ūżŪżóżļĪŻ3x3ż╬źšźŻźļź┐ż└ż╚(3x3)x(3x3)ż╬▒ķōQż“9x9ż╬ōļ░Ķż╦ż╣ż╩ż’ż┴9öv╣įż’ż╩żżż╚żżż▒ż╩żżĪŻ┴Ē┐¶żŽ(3x3)x(3x3)x(3x3)=81x9övĪŻµ£öüżŪżŽ3x3ż╬źšźŻźļź┐ż└ż╚▒ķōQ╬╠żŽ1/9ż╚žōżļĪŻżĶż├żŲż▐ż║źšźŻźļź┐ż“Š«żĄż»żĘżŲżĮżņż½żķŪ¦╝▒╬©ż╬▓■║¤ż“┴└ż”ĪŻ
žōżķżĘż┐╩¼ż“▓┐ż½żŪ▌öĮ■żĘżĶż”ż╚ż╣żļż╚ĪóźŪźŻĪ╝źū▓Įż½ź’źżź╔▓Įż½ĪóżŌżĘż»żŽź▐ź├źū┐¶ż“╗\żõż╣ż½żŪżóżļĪ╩Š«Ę┐źšźŻźļź┐ż╬┬Šż╬Ė·▓╠żŌżóżļż│ż╚ż¼Øi─¾Ī╦ĪŻNiN░╩æTż╬Conv┴žż╬źŌźĖźÕĪ╝źļ▓ĮżŌ║¼ż├ż│żŽźšźŻźļź┐ż╬Š«źĄźżź║▓Įż╦żĶżļ▒Ųūxżžż╬×┤▒■║÷ż╚╣═ż©żļż╚ż’ż½żĻżõż╣żżĪŻżĮż╬└▐├’░Ų┼¬ż╩żŌż╬ż¼GoogLeNetżŪĪó1x1Īó3x3ż╚5x5 (Version3żŪżŽ5x5żŽŪč┘V)ż“╩┬š`ż╦Ų■żņżŲżżżļĪŻż╣ż╩ż’ż┴Š«Ę┐źšźŻźļź┐▓Įż╬▒Ųūx▓“Š├ż╬ż┐żßż╦ź’źżź╔▓Įż“╝{ĄßżĘż┐ż╚╣═ż©żļż╚Īóżóżļµć┼┘żŽ┴T┐▐ż“ż─ż½żßżļĪŻ▐köĄĪóResNetżŽ├▒ĮŃż╦Deep▓Įż“╝{ĄßżĘĪó│žØ{ż¼╝²╠JżĘż╩żżż│ż╚/Ū¦╝▒╬©ż¼ĄK▓Įż╣żļż│ż╚ż½żķ╗─▐ų│žØ{Ī╩residual learningĪ╦ż╬┐Ę▄ćŪ░ż“Ų│Ų■żĘż┐ĪŻż╩ż¬ĪóConvźŌźĖźÕĪ╝źļż╬├µż╦Č”─╠żĘżŲ╗╚├ōżĄżņżŲżżżļČ\╦Īż╦Bottleneck┴žż¼żóżļĪŻØŖ─¦ź▐ź├źū┐¶ż“śO║▀ż╦╩č▓ĮżĄż╗żļČ\╦ĪżŪżóżļĪŻ╬Ńż©żąRGBż╬3┐¦żŪ╩¼ż▒żŲżżż┐ż¼ĪóżĶżĻ├µ┤ų┐¦ż╬8┐¦ż╦ØŖ─¦ź▐ź├źūż“╩¼ż▒żļĪŻż▐ż┐żĮż╬Ąšż“żõżļĪóż╚żżż├ż┐źżźßĪ╝źĖżŪżóżļĪŻ 1x1ż╬źšźŻźļź┐żŽżĮż╬ź▐ź├źū┐¶─┤┼D/┼D╣ńŲDżĻż╬ż┐żßż╦¾H├ōżĄżņżŲżżżļĪŻ
2.6ĪĪCNNż╬źŌźŪźļż╬┐╩▓ĮĪĪ(3) ĪĪĪ┴▒ķōQ┐¶ż╚źčźķ-źßĪ╝ź┐┐¶Ī¦34┴ž░╠żŪ╬╔żżż╬żŪżŽż╩żżż½⁈Ī┴
╦▄£IżŪżŽĪóĘQźŌźŪźļż“ĪóLSIż╬╝┬äóż╦─Š±Tż╣żļźčźķźßĪ╝ź┐ż╚▒ķōQ┐¶ż╬ćĶ┼└ż½żķ└┌żĻ╣■żÓĪŻ
(1) CFĘ┐ż╚CĘ┐ż╬’łĖ■
┐▐11ż╦Øi£Iż╬╔Į1żŪ┐āżĘż┐ĘQź═ź├ź╚ź’Ī╝ź»źŌźŪźļż╬┴ž┐¶Ī╩9┴žż½żķ152┴žĪ╦ż╦×┤ż╣żļĪóILSVRC/ImageNetżŪż╬ź©źķĪ╝╬©Ī╩╦└ź░źķźšż╚Č╩└■Ī¦īÜ╝┤Ī╦Ī󿬿ĶżėĘQźŌźŪźļż╬źčźķźßĪ╝ź┐┐¶Ī╩┼└└■Ī╦ż╚▒ķōQöv┐¶Ī╩╝┬└■Ī¦ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬▒ķōQöv┐¶żŽż█ż╚ż¾ż╔ż¼└čŽ┬▒ķōQ┐¶/MAC┐¶żŪżóżĻĪóż▐ż┐MAC┐¶żŽź═ź├ź╚ź’Ī╝ź»ż╬┴žż╚┴žż“ż─ż╩ż░└▄¶ö┐¶ż╚┼∙żĘżżĪ╦ż╬┐õöĪż“źūźĒź├ź╚żĘż┐ĪŻīÜ╝┤Īó║Ė╝┤ż¬żĶżė▓╝╩šż╬┴ž┐¶ż“┤▐żßµ£żŲ×┤┐¶╝┤ż╚ż╩ż├żŲżżżļĪŻAlexNet8ż╚VGGNet19żŽśĘĪ╩CFĘ┐Ī╦żŪĪóż▐ż┐GoogLeNet22/ResNet152Ī╩CĘ┐Ī╦żŽ×EżŪ╔ĮĄŁżĘż┐ĪŻź©źķĪ╝╬©ż╦╗▓╣═├═ż╚żĘżŲResNet34ż╚ResNet50ż╬├═ż“▓├ż©ż┐ĪŻVGGNetż╬Version4żŪĪó3.08%ż╬╩¾╣ż¼żóżļż¼ĪóźūźĒź├ź╚żĘżŲżżż╩żżĪ╩╗▓╣═½@╬┴30Ī╦ĪŻ
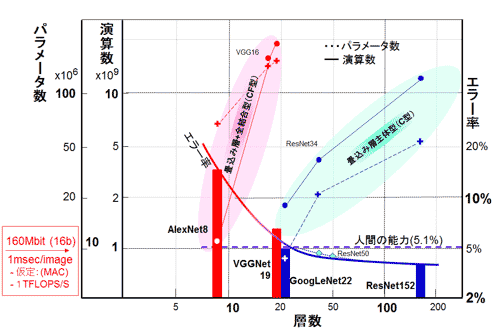
┐▐11 ▒ķōQ┐¶ż╚źčźķźßĪ╝ź┐ż╬┤žĘĖ
(2) CFĘ┐żŪżŽĖ┬─c
AlexNetż╬8┴žż½żķVGGNetż╬19┴žż╦╗\▓├ż╣żļż╚Īóź©źķĪ╝╬©żŽ16.4%ż½żķ7.3%żžż╚▓■║¤żĄżņż┐ĪŻżĘż½żĘĪóźčźķźßĪ╝ź┐┐¶żŽ6200╦³Ė─ż½żķ1.44▓»Ė─ż╚2Ū▄╗\Īó▒ķōQ┐¶żŽ11.4▓»öv┐¶ż½żķ196▓»övż╚╠¾20Ū▄æųĖéżĘż┐ĪŻż│żņ░╩æųż╬▓■║¤ż“┴└ż”ż╚źčźķźßĪ╝ź┐┐¶ż╚ØŖż╦▒ķōQ┐¶ż╬╗\▓├ż¼┼÷─ś═Į„[żĄżņżļĪŻż▐ż┐│žØ{ż¼╝²╠JżĘż╩żżż╚Ė└ż’żņżŲżżżļĪŻżĄżķż╦┐▐12ż╦┐āż╣żĶż”ż╦¾H┴žż╦ż╣żļż╚Ī╩20┴žż½żķ56┴žż╦╗\żõż╣ż╚Ī╦ź©źķĪ╝╬©ż¼ĄK▓Įż╣żļż╚żżż”źŪĪ╝ź┐ż¼╩¾╣żĄżņżŲżżżļĪ╩╗▓╣═½@╬┴28/29Ī¦MSRAż╬HeĢ■ż╬éb╩ĖĪ╦ĪŻ
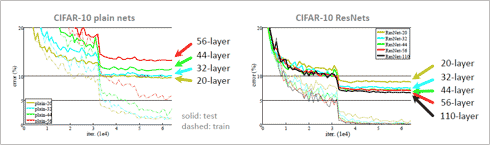
┐▐12 ¾H┴ž▓Įż╦żĶżļź©źķĪ╝╬©╗\ĮjĪ╩CIFAR-10Ī╦╗▓╣═½@╬┴28/29Ī¦
▓Ż╝┤ │žØ{öv┐¶Īóāe╝┤ ź©źķĪ╝╬©Ī╩%Ī╦ ║Ė┐▐ “£═ĶĘ┐Ī╩ResNetż╬Short Cut╠ĄĪ╦żŽ╬¶▓ĮżĘżŲżżżļĪŻ
īÜ┐▐ ResNetżŽ▓■║¤żĄżņżŲżżżļĪŻ
(3) CĘ┐żŪźųźņĪ╝ź»ź╣źļĪ╝
żĮż╬╩╔ż“źųźņĪ╝ź»żĘĪ╩╩╔ż╚Ū¦╝▒ż╣żļØiż╦▓“»éżĄżņżŲżĘż▐ż├ż┐żĶż”ż└Ī╦żĶżĻ¾H┴ž▓Įż“▓─ē”ż╚żĘż┐źŌźĖźÕĪ╝źļ/źŌźŪźļż╬┬Õ╔Įż¼ĪóØi£IżŪ└Ō£½żĘż┐Mlpconv/NiN (Network in Network) Inception Layer/GoogLeNetż╚Ī󿥿ķż╦Residual Block/ResNetżŪżóżļĪŻż╩ż¬ĪóGoogLeNetż╬┴ž┐¶żŽ22┴žżŪżóżļĪŻ╝┬║▌ż╦żŽź’źżź╔(2żóżļżżżŽ4╩┬š`ż╬ŗ╩¼żŌżóżĻ)ż╦ż╩ż├żŲżżżļż│ż╚ż½żķConv┴žż“µ£żŲź½ź”ź¾ź╚ż╦Ų■żņżļż╚40┴žĪ╩┐▐9żŪź½ź”ź¾ź╚Ī╦ż╚ż╩żļĪŻResNetżŽResidual Blockż╬Ų│Ų■ż╦żĶżĻ152┴žżŪżŌ│žØ{ż¼▓─ē”ż╚ż╩ż├ż┐ĪŻź©źķĪ╝╬©żŽĪóGoogLeNetżŽ6.67% (ĖÕż╦Īó4.82%/BN-V2Īó3.58%/V3Īó3.08%/V4ż╚Version Up)ĪóResNetżŽ3.57%ż╚Č”ż╦┐═┤ųż╬ē”╬üĪ╩5.1%Ī¦Š»żĘ└pżĘżż┤ØŹż└ż¼Ī╦ż“▒█ż©żļ±T▓╠ż“ųÖżŁĮążĘż┐ĪŻ
CĘ┐ż╬żŌż”▐kż──_═ūż╩┼└żŽĪó┐▐11ż╬20┴ž┼÷ż┐żĻżŪż╬VGGNet19ż╚GoogLeNet22ż╬┐¶├═ż╬║╣żŪżóżļĪŻźčźķźßĪ╝ź┐┐¶ż¼1.44▓»Ė─ż½żķ701╦³Ė─ż╦Īó▒ķōQöv┐¶żŽ196▓»övż½żķ15▓»övż╚ĘQĪ╣▐kĘÕ░╩æų(20╩¼ż╬1)▓■║¤żĄżņżŲżżżļ┼└żŪżóżļĪŻ 16bit▒ķōQż╚ż╣żļż╚ĪóGoogLeNetż└ż╚Īó112MbitĪóResNet34ż└ż╚352Mbitż╬źßźŌźĻż¼ØŁ═ūż╚ż╩żļĪŻ═Š═Ąż“żŌż├żŲ║«║▄ż╣żļźņź┘źļżŪżŽż╩żżż¼Īóż½ż╩żĻ░Ężżżõż╣żżźņź┘źļż╬źßźŌźĻ╬╠ż╬šJßŲż╦Ų■ż├ż┐ż╚╣═ż©įużļĪŻ
(4) CĘ┐żŽ┴ž┐¶ż╦╚µ╬ѿʿŲ╗\▓├
į~├▒ż╩─Ļ╬╠┼¬ż╩└Ō£½ż“ż╣żļĪŻ┐▐11żŽ×┤┐¶ź░źķźšżŪżóżļĪŻźčźķźßĪ╝ź┐Īó▒ķōQ┐¶Č”ż╦┴ž┐¶ż╦ż█ż▄╚µ╬ѿʿŲżżżļĪŻ░╩▓╝ż╬┤žĘĖż“Ęeż─ĪŻ
- ┴ž┐¶ż╦╚µ╬Ń ▒ķōQ┐¶ 1▓»öv/┴žĪóźčźķźßĪ╝ź┐┐¶ 50╦³Ė─/┴ž
- źčźķźßĪ╝ź┐┐¶/▒ķōQ┐¶ż╬╚µ 1/200Ī┴1/300µć┼┘ (Ų■╬üż¼224x224Ī󟻟ķź╣1000ż╬Šņ╣ń)
źčźķźßĪ╝ź┐┐¶ż¼Š»ż╩żżż╬żŽĪóČ”─╠ż╬źčźķźßĪ╝ź┐ż“╗╚├ōżĘżŲżżżļĪ╩─_ż▀Č”Ń~Ī¦weight sharingĪ¦╗▓╣═½@╬┴6Ī╦ż½żķżŪĪóżĮż╬╚µ(Ę½żĻ╩ųżĘ╗╚ż’żņżļöv┐¶)żŽĘQ┴žż╬Įą╬üż╬źĄźżź║ż╬╩┐Čč├═ż╦ŖZżżżŽż║ĪŻ╬ŠźŌźŪźļż╚żŌĘQ┴žż╬Įą╬üż╬źµź╦ź├ź╚┐¶żŽ14x14=256ż“ØiĖÕż╦żĘż┐źĄźżź║żŪżóżļĪŻż│ż╬200Ī┴300ż╬├═ż╦×┤ż╣żļĖČ═²┼¬ż╩└Ō£½Ī╩═²▓“Ī╦żŽĖĮ╗■┼└żŪżŽżŪżŁż╩żżĪ╩ż┐żųż¾ĪóŲ■╬üż╚ź»źķź╣┐¶ż╚┤žŽóż╣żļĪ╦ĪŻ
(5) ¾H┴ž▓Įż╬╝{ĄßĪĪ1202┴žż▐żŪ żĘż½żĘĪ¬
MSRAż╬HeĢ■żķżŽCIFAR-10ż╚żżż”▐k╚╠رöüŪ¦╝▒ż╬ź┘ź¾ź┴ź▐Ī╝ź»żŪResNetż╬1202┴žż▐żŪź╚źķźżżĘż┐(╗▓╣═½@╬┴28)ĪŻ│žØ{żŽ▓─ē”ż└ż¼7.93%ż╚ź©źķĪ╝╬©żŽĄK▓ĮżĘż┐ĪŻ110┴žż¼╗ŅżĘż┐├µżŪżŽź┘ź╣ź╚6.43%ż╚╩¾╣żĄżņżŲżżżļĪŻ╬¶▓ĮĖČ░°ż╦┤žżĘżŲżŽĪóCIFAR-10ż╬æä╠Žż¼Š«żĄżżĪ╩32x32źįź»ź╗źļRGB Īó10ź»źķź╣Ī╦ż│ż╚ż½żķĪóāį│žØ{/āį┼¼╣ń(Overfitting)ż¼ÅŚż│ż├żŲżżżļż╚ż╬┐õ▒Rż¼╩¾╣żĄżņżŲżżżļĪŻČ├żŁż╩ż╬żŽŠ«żĄż╩32x32ź»źķź╣ż╬Ų■╬ü▓Ķ楿ŪżŌČ╦żßżļż╚110┴žżŌØŁ═ūż╩┼└żŪżóżļ(╗▓╣═½@╬┴28Īó7╩Ū)ĪŻ
ż▐ż╚żßżļż╚Īó“£═Ķż╬ĪųøQż▀╣■ż▀┴ž+µ£±T╣ń┴žĘ┐Ī¦CFĘ┐Īūż½żķźŌźĖźÕĪ╝źļ▓ĮżĘż┐ĪųøQż▀╣■ż▀┴ž╝ńöüĘ┐Ī¦CĘ┐Īūż╦öĪżĻĪó100┴ž░╩æųż╬¾H┴žżŪż╬│žØ{ż¼▓─ē”ż╚ż╩ż├ż┐ĪŻżĮż╬±T▓╠Īó┐═┤ųż╬ē”╬üż“«Ćż©ż┐3%±śĪ╩ILSVRC/Imagenetż╬ź┘ź¾ź┴ź▐Ī╝ź»Ī╦ż╬ź©źķĪ╝╬©ż╦┼■├ŻżĘż┐ĪŻżĄżķż╦źčźķźßĪ╝ź┐┐¶Ī╩źßźŌźĻ╬╠Ī╦Ą┌żė▒ķōQ┐¶Ī╩▒ķōQ╗■┤ųĪó╣ŌÅ]└ŁĪ╦żŌ▐kĘÕĪ╩░╩æųĪ╦ż╬Ę┌žōż¼╝┬ĖĮżĄżņż┐ĪŻźóźūźĻź▒Ī╝źĘźńź¾ż╚ż╬ź©źķĪ╝ß×═ŲšJ░Žż╚ż╬Ė½╣ńżżż└ż¼Īó34┴žżŪżŌż½ż╩żĻ╬╔żżźņź┘źļżŪżóżļĪŻź©ź├źĖ▒■├ōżŪ╝┬äóż¼Š}ż╦ŲŽż»ż╚ż│żĒż▐żŪ═Ķż┐ż╚╣═ż©įużļĪŻ
(6) ÅRų`żŽĪóGoogLeNetż╚ ResNetżŪż╔ż┴żķż¼╬╔żżż╬ż½Ī®
MSRAż╬HeĢ■żķż╬─¾░Ųż╬ResNetż╬╗─▐ų│žØ{ż╚żżż”╗┬┐Ęż╩źóźżźŪźŻźóż╦×┤ż╣żļäh▓┴żŽ╣ŌżżĪŻż▐ż┐ResNetżŽ║“ŃQ¼ŹĘQ¹|ż╬ź│ź¾ź┌źŲźŻźĘźńź¾żŪ║Ū╣Ō├═ż“æ═įużĘżŲżżżļĪŻżĮż╬├µżŪرöüŪ¦╝▒żĶżĻžM░ū┼┘ż¼╣ŌżżØ±öüĖĪē¶ż╬Faster R-CNNż╬źóźļź┤źĻź║źÓż“ResNetæųż╦╝┬äóżĘĪóĖĪē¶╬©żŪ║Ū╣Ō├═ż“ųÖżŁĮążĘżŲżżżļ┼└żŽØŖ╔«ż╣ż┘żŁżŪżóżļĪŻż╩ż¬Īóż│ż╬źóźļź┤źĻź║źÓż╬ź¬źĻźĖź╩źļżŌMSRAż╬HeĢ■ż╬ź░źļĪ╝źūż╬╚»░ŲżŪżóżļĪŻ║ŪŖZĪó╩╠ĄĪ┤žż¼Recurrent NNż╦ResNet┼¼├ōżĘż┐Īóż╩ż╔¾Hż»ż╬·t│½ż╬╩¾╣żŌżóżļĪ╩╗▓╣═½@╬┴29Ī╦ĪŻ═ŠÕiżŪżóżļż¼ĪóMSRAż╬Kaming HeĢ■żŽ5ĘŅ¼ŹMSRAż“Ķī┐”żĘĪó║ŻĘŅ7ĘŅż╦Facebookż╦┼Š┐”żĘż┐ĪŻ╩╠ż╦ĪóرöüĖĪē¶ż╬R-CNNż¬żĶżėFast R-CNNżŪ├°ć@ż╩R. GirshickżŌ║“ŃQ11ĘŅż╦MSż½żķFacebookż╦┼Š┐”żĘż┐ĪŻ║ŻĖÕĪó▐k┴žFacebook AI research (FAIR) ż╬ĮĻ─╣żŪCNNż╬░ķżŲĪ╩Ö┌ż▀ż╬Ī╦ż╬┐Ųż╬LeCunżĄż¾ż╬éŃ┬®ż¼╣ėż»ż╩żļż╚═Į„[żĄżņżļĪŻż▐ż┐FacebookĪ╩ResNet??Ī╦ż╚GoogleĪ╩GoogLeNetĪ╦ż╬▐k³hæ]ż┴ż¼▐k┴žŚ„żĘż»ż╩żļż╚═Į„[żĄżņżļĪ®Ī¬
▐köĄĪóGoogleŖõżŽ2016ŃQ2ĘŅż╦Ī╔Inception-V4, Inception-ResNet and the Impact of Residual Connections on LearningĪ╔ż╩żļź┐źżź╚źļż╬éb╩ĖżŪGoogLeNet V4Ī╩version4Ī¦╗▓╣═½@╬┴30Ī╦ż“╚»╔ĮżĘżŲżżżļĪŻGoogLeNetż╦Residual Learningż“ŲDżĻŲ■żņż┐źŌźŪźļżŪżóżļĪŻØ±öüŪ¦╝▒╬©Ī╩ź©źķĪ╝╬©Ī╦żŽĪó3.08%ż“├Ż└«żĘżŲżżżļĪŻż┐ż└żĘĪóż│ż╬╚»╔Įż╦×┤żĘżŲ╣Įļ]ż¼╩Ż╗©ż╣ż«żļż╚żżż”┴TĖ½żŌżóżļĪŻ
ż½ż╩żĻż▐ż╚ż▐żĻż─ż─żóżļż¼ĪóżĘżążķż»ÅR£åż¼ØŁ═ūż╚╣═ż©żļĪŻ
╗▓╣═½@╬┴ (1Ī┴23ż▐żŪżŽØiöv░╩Øi)
24. Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, Ī╚Gradient-based learning applied to document recognitionĪ╔, Proceedings of the IEEE, 86(11):2278–2324, November 1998, LeNet.
25. Karen Simonyan and Andrew Zisserman, Ī╚Very Deep Convolutional Networks for large-Scale Image RecognitionĪ╔, in International Conference on Learning Representations (ICLR2015), 20150507. VGGNet
26. Min Lin, Qiang Chen, Shuicheng Yan, Ī╚Network In NetworkĪ╔, 2014ŃQ3ĘŅ4Ų³(Ver3). NiN.
27. Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Ī╚Going Deeper with ConvolutionsĪ╔, 2014ŃQ9ĘŅ17Ų³. GoogLeNet V1.
28. Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Ī╚Deep Residual Learning for Image RecognitionĪ╔, 2015ŃQ12ĘŅ10Ų³. ResNet.
29. Kaming He, Ī╚Deep Residual Networks, Deep Learning Gets Way DeeperĪ╔, ICML 2016 tutorial, 0160619, ║Ū┐Ęż╬ResNetŠ╩¾
30. Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Ī╚Inception-v4, Inception-ResNet and the Impact of Residual Connections on LearningĪ╔, 2016ŃQ2ĘŅ23Ų³. GoogLeNet V4.
31. Sergey Ioffe, Christian Szegedy, Ī╚Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate ShiftĪ╔, 2015ŃQ3ĘŅ2Ų³(V3). GoogLeNet V2. w/BN Ī╩Batch Normalizationż╬éb╩ĖĪ╦
32. Eugenio Culurciello, Ī╚Neural Network ArchitecturesĪ╔, źųźĒź░, 2016ŃQ6ĘŅ4Ų³, Neural Network Architectureż╬źĄź▐źĻ.

