TSMCĪóSiźšź®ź╚ź╦ź»ź╣Ī󟔟¦Ī╝źŽź╣ź▒Ī╝źļĮĖ└čövŽ®ż╬┬ō(li©ón)┘I╗Ķż“─¾░Ų
AIź│ź¾źįźÕĪ╝źŲźŻź¾ź░źčź’Ī╝ż¼ż▒ż¾░·żĘĪóźūźĒź╗ź╣ź╬Ī╝ź╔ż╬╚∙║┘▓ĮżŽ┴ßż▐ż├żŲżżżļĪóż╚TSMCźĘź╦źóźąźżź╣źūźņźĖźŪź¾ź╚Ę¾╔¹Č”Ų▒║Ū╣ŌČ╚ē»╝╣╣į└šŪżŪvż╬Kevin ZhangĢ■(hu©¼)ż¼Įęż┘ż┐ĪŻż│żņżŽ6ĘŅ28Ų³ż╦▓Ż┘pżŪTSMC Technology Symposium Japanż“│½╠¢(h©żo)żĘż┐║▌ĪóźßźŪźŻźóĖ■ż▒Č\Įč└Ō£½▓±żŪĮęż┘ż┐żŌż╬ĪŻ

┐▐1ĪĪTSMC źĘź╦źóźąźżź╣źūźņźĖźŪź¾ź╚Ę¾╔¹Č”Ų▒║Ū╣ŌČ╚ē»╝╣╣į└šŪżŪvż╬Kevin ZhangĢ■(hu©¼)
TSMCżŽĪó2nmźūźĒź╗ź╣ź╬Ī╝ź╔ż½żķA16Ī╩1.6nmź╬Ī╝ź╔Ī╦żžż╬źĒĪ╝ź╔ź▐ź├źūż“┐ā(j©®)ż╣ż╚Ų▒╗■ż╦Īó└Ķ├╝źčź├ź▒Ī╝źĖź¾ź░ż╦żŌÅR╬üż╣żļĪŻ║ŲŪ█└■┴žż╬źżź¾ź┐Ī╝ź▌Ī╝źČĪ╝żŽ├▒ż╩żļŪ█└■ż╬║Ų╣Į└«ż“ż╣żļż└ż▒żŪżŽż╩ż»Īóźóź»źŲźŻźųż╩ź┴ź├źūżŌļmżß╣■żÓ╣Įļ]ĪóÕXż“Ų©ż¼ż╣źĄĪ╝ź▐źļźėźóĪ󿥿ķż╦żŽźĘźĻź│ź¾źšź®ź╚ź╦ź»ź╣ż╦żĶżĻĖ„Ų│Ė„Ž®ż“▐kż─ż╬źĄźųź╣ź╚źņĪ╝ź╚ż╦└▀ż▒żļ╣Įļ]Ī╩┐▐2Ī╦ż╩ż╔ż╦ż─żżżŲżŌ£½żķż½ż╦żĘż┐ĪŻ
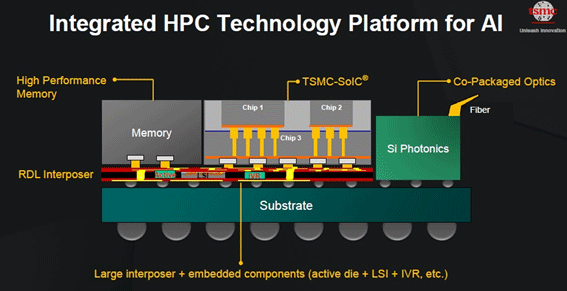
┐▐2ĪĪ1źčź├ź▒Ī╝źĖŲŌż╬I/OövŽ®ż╦Siźšź®ź╚ź╦ź»ź╣ż“Ų│Ų■ĪĪĮąųZĪ¦TSMC
TSMCżŽż╩ż╝└Ķ├╝źčź├ź▒Ī╝źĖż╦╬üż“Ų■żņżļż½ĪŻ6ĘŅżŽżĖżßż╬Computex Taipei 2024żŪNvidiaż╬CEOżŪżóżļJensen HuangĢ■(hu©¼)ż¼Įęż┘ż┐żĶż”ż╦ĪóźÓĪ╝źóż╬╦Īō¦ż╚żżż”żĶżĻźŪź╩Ī╝ź╔ż╬╦Īō¦ż└ż¼Īó╚∙║┘▓Įż¼╣įżŁż─ż»ż╚ż│żĒż▐żŪ╣įżŁż─żżż┐┤Čż¼żóżĻĪó╚∙║┘▓Įż╬ź╣źįĪ╝ź╔ż¼┤╦żÓ▐köĄ(sh©┤)żŪĪóÖ┌└«AIż╦żĶż├żŲAIź│ź¾źįźÕĪ╝źŲźŻź¾ź░źčź’Ī╝żžż╬═ūĄßż¼╗ž┐¶┤ž┐¶┼¬ż╦╗\▓├żĘżŲżŁż┐ĪŻHuangĢ■(hu©¼)żŽĪó╚∙║┘▓ĮČ\Įčż╚ź│ź¾źįźÕĪ╝źŲźŻź¾ź░źčź’Ī╝ż╬ź«źŃź├źūż¼ż▐ż╣ż▐ż╣╣Łż¼żĻĪóź│ź¾źįźÕĪ╝źŲźŻź¾ź░źčź’Ī╝ż╬źżź¾źšźņż¼ÅŚżŁżŲżżżļż╚╔ĮĖĮżĘż┐ĪŻż│żņż“▓“»éż╣żļöĄ(sh©┤)╦ĪżŽĪó╚∙║┘▓ĮżŪżŽż╩ż»└Ķ├╝źčź├ź▒Ī╝źĖČ\ĮčżŪżóżļż╚Č”ż╦Ī󟔟¦Ī╝źŽź╣ź▒Ī╝źļźżź¾źŲź░źņĪ╝źĘźńź¾żŪżŌżóżļĪŻ
TSMCż¼źĘźĻź│ź¾źšź®ź╚ź╦ź»ź╣ż╦┐©żņż┐ż╬żŽĪóż│żņż¼ĮķżßżŲż╚╗ūż’żņżļĪŻźĘźĻź│ź¾źšź®ź╚ź╦ź»ź╣żŽź┴ź├źūæųż╬Ų■Įą╬ü┤žĘĖż╬ż▀żŪĪóź┴ź├źūŲŌż╬▒ķōQżŽżŌż┴żĒż¾źĘźĻź│ź¾ż¼├┤ż”ĪŻē|Č╦┼¬ż╦żŽ1źčź├ź▒Ī╝źĖŲŌż╬I/Oŗ╩¼ż“źĘźĻź│ź¾źšź®ź╚ź╦ź»ź╣żŪ╣Į└«żĘĪóŠ├õJ┼┼╬üż╚źņźżźŲź¾źĘż“1/10░╩▓╝ż╦ż╣żļĪŻ
źčź├ź▒Ī╝źĖź¾ź░Č\Įčż╬┬Šż╦ź│ź¾źįźÕĪ╝źŲźŻź¾ź░źčź’Ī╝ż“æųż▓żļŠ}├╩ż╚żĘżŲĪóCerebrasż¼╝┬├ō▓ĮżĘżŲżżżļź”ź¦Ī╝źŽź╣ź▒Ī╝źļĮĖ└čövŽ®Č\Įčż¼żóżļĪ╩┐▐3Ī╦ĪŻCerebrasżŽ300mmź”ź¦Ī╝źŽż½żķźĘźĻź│ź¾ż“21.5cm│čżŪ╗═│čż»└┌żĻŲDż├ż┐ĄĮj(lu©░)ż╩1ź┴ź├źūż“└▀╝ŖżĘĪ╩╗▓╣═½@╬┴1Īó2Īó3Ī╦ĪóTSMCż¼×æļ]żĘżŲżżżļĪŻ║ŪĮķżŽ12nmĪó╝Īż╦7nmĪóżĮżĘżŲ║ŻŃQ│½╚»żĘż┐CS-3żŽ5nmźūźĒź╗ź╣żŪ×æļ]żĘżŲż¬żĻĪóĮĖ└迥żņż┐ź╚źķź¾źĖź╣ź┐┐¶żŽ║ŪĮķż╬1├¹Ė─ż½żķŗī3└ż┬ÕżŪżŽ4├¹Ė─ż╦╗\ż©żŲżżżļĪŻź”ź¦Ī╝źŽ1ĮŚżŪAIź│ź¾źįźÕĪ╝ź┐ż¼▓─ē”ż╦ż╩żļĪŻ
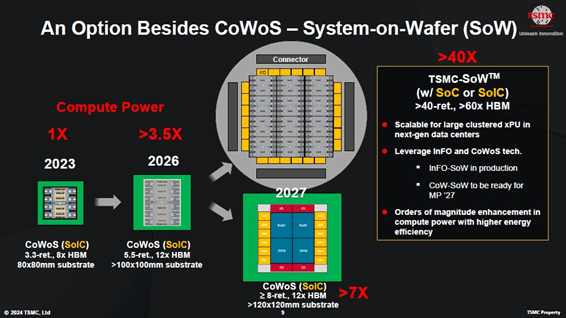
┐▐3ĪĪź”ź¦Ī╝źŽź╣ź▒Ī╝źļĮĖ└čövŽ®ż└ż╚Īóź│ź¾źįźÕĪ╝źŲźŻź¾ź░źčź’Ī╝żŽ40Ū▄ż╦ĪĪĮąųZĪ¦TSMC
TSMCż╚Č”Ų▒żŪCerebrasżŽź”ź¦Ī╝źŽź╣ź▒Ī╝źļĮĖ└čövŽ®ż“│½╚»żĘż┐ż¼ĪóTSMCżŽż│ż╬Č\ĮčżŌ┬ō(li©ón)┘I╗ĶĪ╩ź¬źūźĘźńź¾Ī╦ż╚żĘżŲĘŪż▓żŲżżżļĪŻĮø(j©®ng)═ĶĪóÖ┌└«AIż“┐õ┐╩ż╣żļĖ▄Ąęż¼ź”ź¦Ī╝źŽź╣ź▒Ī╝źļĮĖ└čövŽ®ż“═ūĄßż╣żļŠņ╣ńżŽĪóPDKĪ╩źūźĒź╗ź╣│½╚»źŁź├ź╚Ī╦ż“├ō┴TżĘżŲ▒■ż©żŲżżż»ż─żŌżĻż½Īóż╚KevinĢ■(hu©¼)ż╦ä®╠õżĘż┐ż╚ż│żĒĪóYesż╚┼·ż©ż┐ĪŻTSMCżŽĪóNvidiaż╬Huang CEOż¼Įęż┘żŲżżż┐Īųź│ź¾źįźÕĪ╝źŲźŻź¾ź░źčź’Ī╝ż╬źżź¾źšźņĪūż╦▒■ż©żļČ\Įčż“ź¬źūźĘźńź¾ż╚żĘżŲź”ź¦Ī╝źŽź╣ź▒Ī╝źļĮĖ└čövŽ®ż“├ō┴TżĘżŲżżżļż│ż╚żŪĪóż½ż─żŲż╬ź”źŻź¾źŲźļĪ╩Microsoftż╚IntelĪ╦ż╬┤žĘĖż╬żĶż”ż╦ĪóTSMCż╚Nvidiaż╬┤žĘĖż¼Įø(j©®ng)═ĶżóżĻż”żļż│ż╚ż“┐ā(j©®)║ȿʿŲżżżļĪŻ
╗▓╣═½@╬┴
1. ĪųCerebras╝ęĪ󟔟¦Ī╝źŽæä╠Žż╬AIź┴ź├źūż“╝┬äóżĘż┐ź│ź¾źįźÕĪ╝ź┐ż“╚»ŪõĪūĪóź╗ź▀ź│ź¾ź▌Ī╝ź┐źļĪó(2024/07/02)
2. Īų7nmźūźĒź╗ź╣żŪ×æļ]żĘż┐ź”ź¦Ī╝źŽæä╠Žż╬ĄĮj(lu©░)ż╩AIź┴ź├źūĪūĪóź╗ź▀ź│ź¾ź▌Ī╝ź┐źļĪó(2021/04/28)
3. ĪųCerebrasĪó4├¹ź╚źķź¾źĖź╣ź┐ż╬ŗī3└ż┬Õź”ź¦Ī╝źŽź╣ź▒Ī╝źļAIź┴ź├źūż“│½╚»ĪūĪóź╗ź▀ź│ź¾ź▌Ī╝ź┐źļĪó(2024/03/15)

